







 本文详细介绍如何在Anaconda环境下安装和使用多个自然语言处理工具包,包括NLTK、Gensim、Tensorflow、Jieba、StanfordNLP及Hanlp,涵盖中文分词、词性标注、主题提取等NLP核心功能。
本文详细介绍如何在Anaconda环境下安装和使用多个自然语言处理工具包,包括NLTK、Gensim、Tensorflow、Jieba、StanfordNLP及Hanlp,涵盖中文分词、词性标注、主题提取等NLP核心功能。
注意:以下pip命令都是在Anaconda prompt中运行的。因为使用anaconda来安装pyhon库时,它会自动解决各种依赖问题,方便快捷
1、NLTK
Natural Language Toolkit,自然语言处理工具包,在NLP领域中,最常使用的一个Python库。
安装:pip install nltk
2、Gensim
可以用来从文档中自劢提取语义主题。它包含了很多非监督学习算法如:TF/IDF,潜在语义分析(Latent Semantic Analysis,LSA)、隐含狄利克雷分配(Latent Dirichlet Allocation,LDA),层次狄利克雷过程
( Hierarchical Dirichlet Processes ,HDP )等。它还支持Word2Vec,Doc2Vec等模型。
安装:
方法一: pip install gensim
方法二:http://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载对应版本的whl文件,然后在命令行进入文件所在目录,输入:pip install **.whl 其中 ** 要替换为你的文件的文件名。
3、Tensorflow
这个东西是Google研发的,广泛用于深度学习领域。
安装:pip install tensorflow
或者先新建一个环境,然后再安装:
第一步:创建一个名为 tensorflow 的新环境,并安装pip,python3.6,以及anaconda的基础包(包括numpy,pandas等)
conda create -n tensorflow pip python=3.6 anaconda
第二步:进入新建的环境(想要退回基础环境base时,输入:deactivate)
activate tensorflow
第三步:输入以下命令安装tensorflow cpu版本:
pip install --ignore-installed --upgrade tensorflow
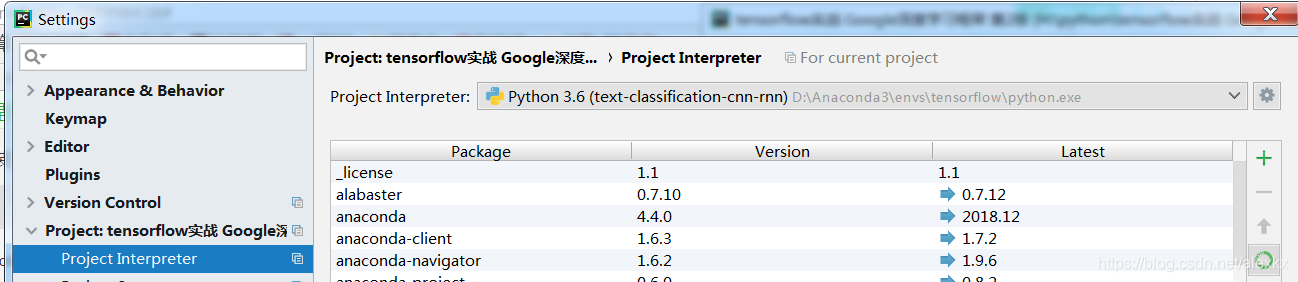
第四部(optional):在pycharm中想使用tensorflow时,需要将项目的interpreter修改为该环境中的python.exe,一般在安装目录下的envs文件夹中可以找到新建的环境,点进去就可以找到这个python.exe
4、Jieba
广泛使用的中文分词工具,也可以用来做词性标注。
项目地址:https://github.com/fxsjy/jieba
安装:
pip install jieba
5、Stanford NLP
支持中文、英文、阿拉伯语、法语、德语、西班牙语等多种语言
Stanford NLP提供了一系列自然语言分析工具。它能够给出基本的词形,词性,不管是公司名还是人名等,格式化的日期,时间,量词,并且能够标记句子的结构,语法形式和字词依赖,指明那些名字指向同样的实体,指明情绪,提取发言中的开放关系等。
安装:
-
安装stanford nlp自然语言处理包:
pip install stanfordcorenlp -
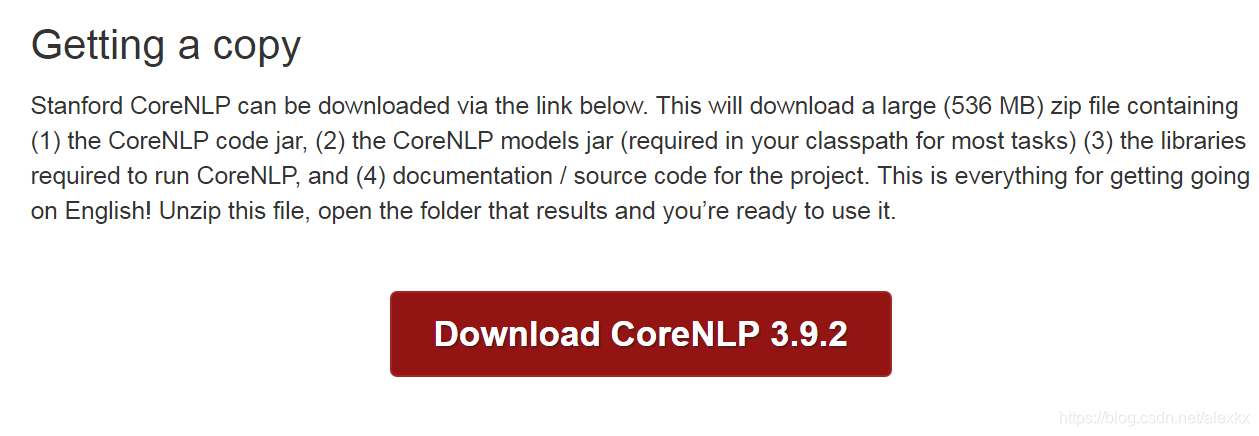
下载Stanford CoreNLP文件:https://stanfordnlp.github.io/CoreNLP/download.html
-
下载中文模型jar包,https://stanfordnlp.github.io/CoreNLP/download.html

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8834
8834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









