






正则表达式:
1.正则表达式的库文件:re
2.正则表达式的方法:findall,search,sub
findall(寻找的值,对象),返回一个列表
3.换行
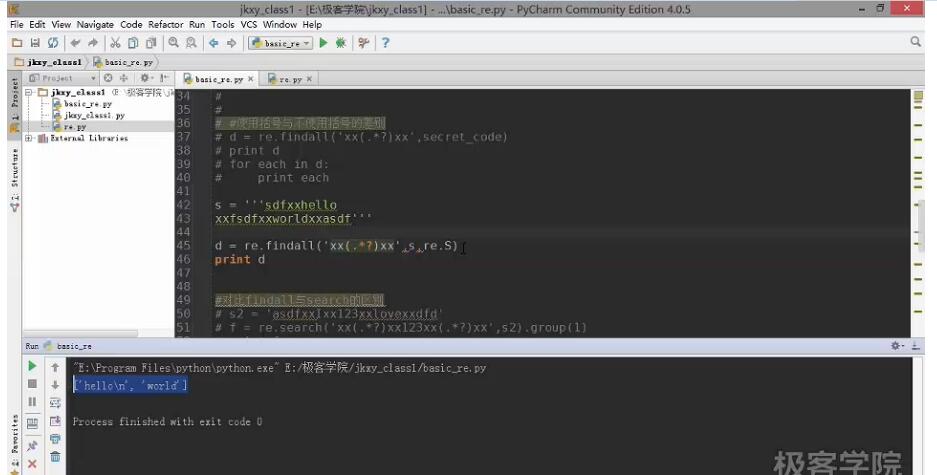
4.匹配数字
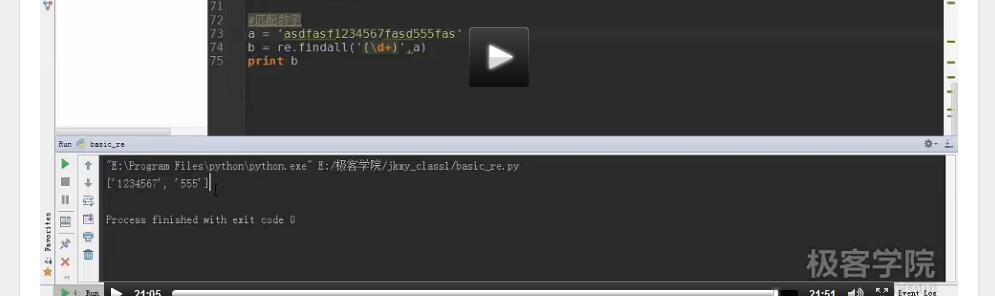
网页爬虫(半自动)
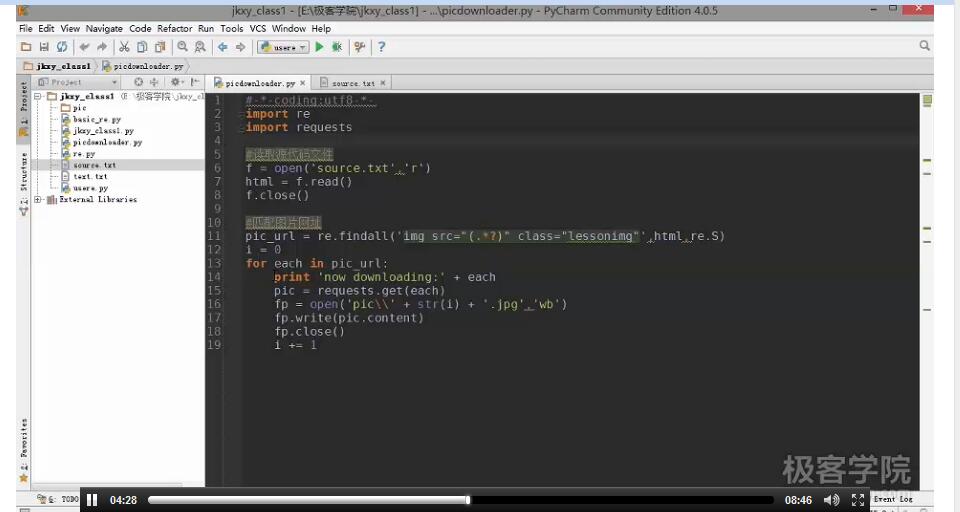
提取网页源代码
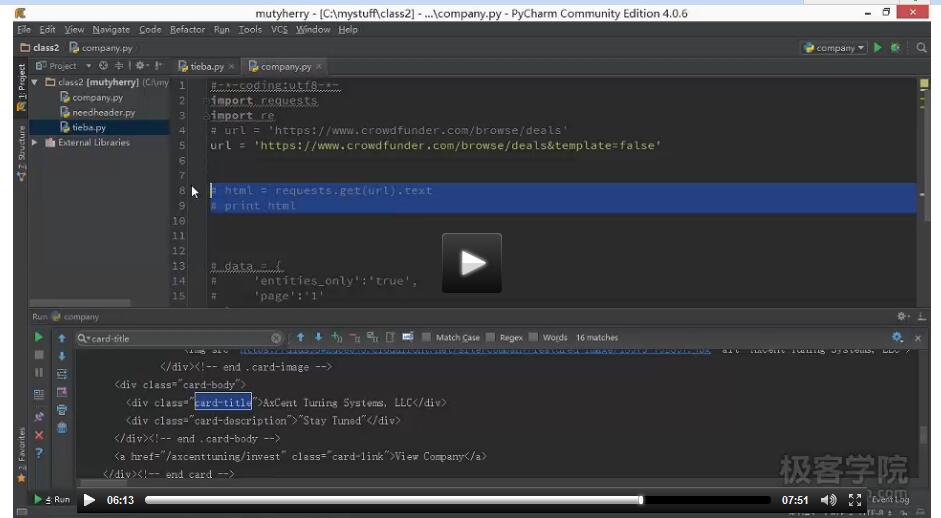
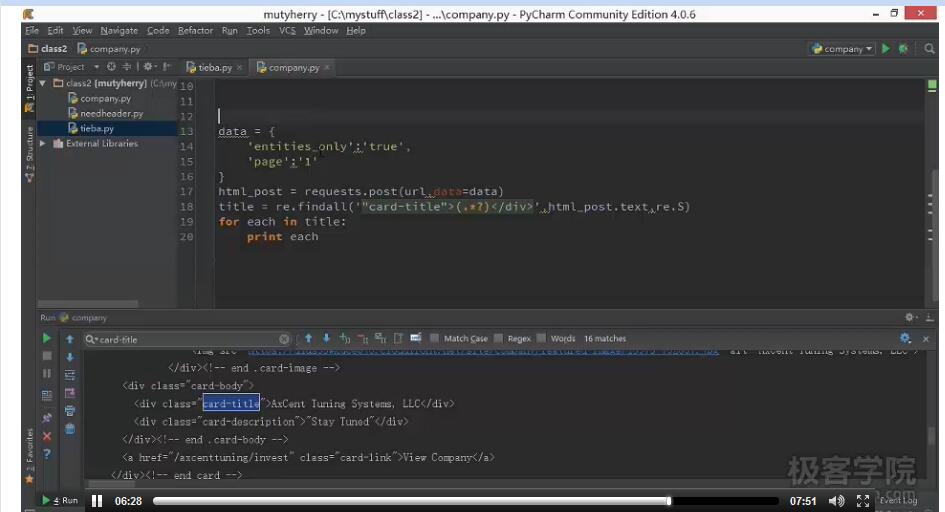
7.向网页提交数据
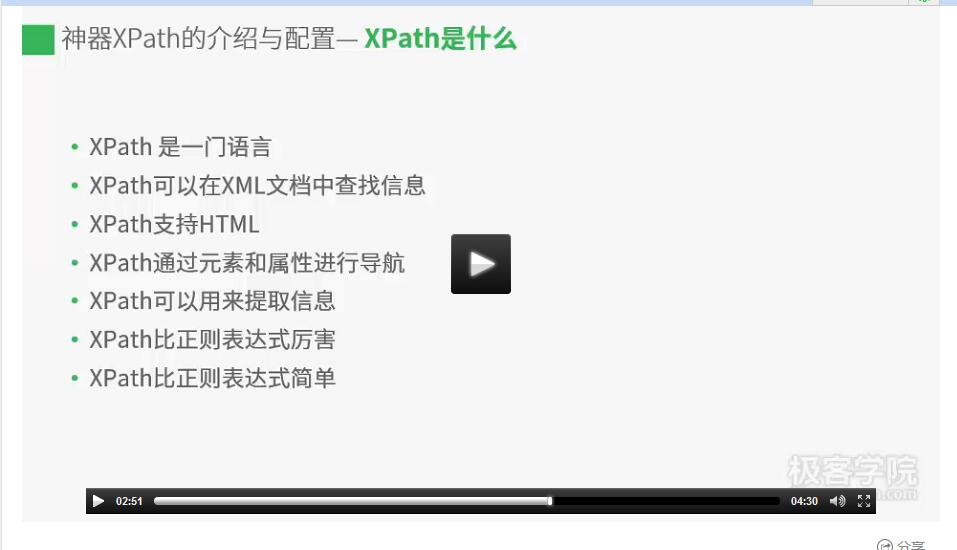
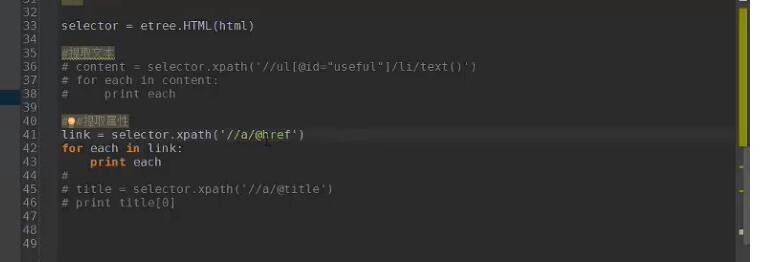
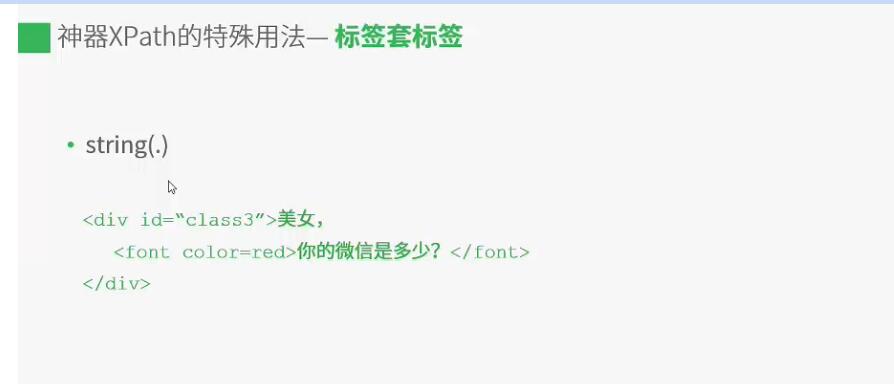
- XPath
获取神奇符号的方法:右击源代码,选择copy xpath
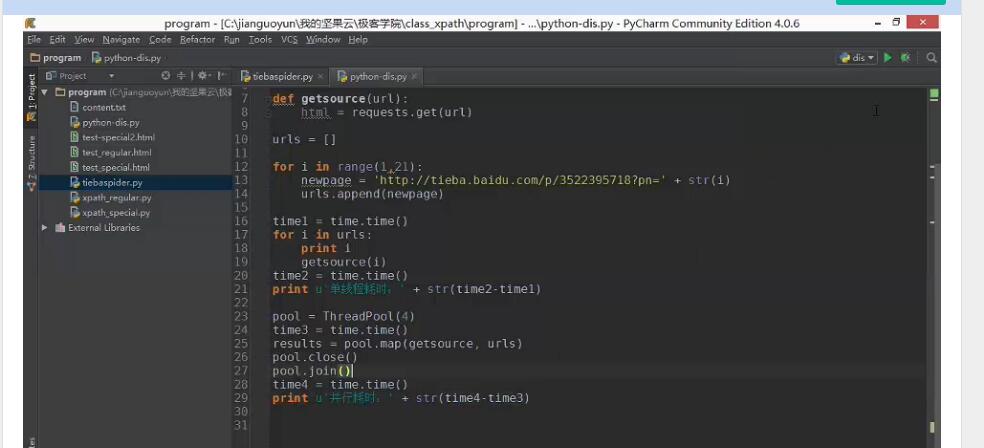
9.python的并行化多线程操作
(python中开源爬虫框架scrapy自带更高效率的并行化多线程技术,这里map可初步了解)

正则表达式:
1.正则表达式的库文件:re
2.正则表达式的方法:findall,search,sub
findall(寻找的值,对象),返回一个列表
3.换行
4.匹配数字
网页爬虫(半自动)
提取网页源代码
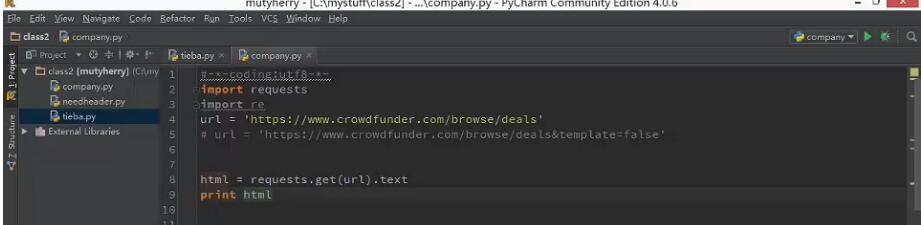
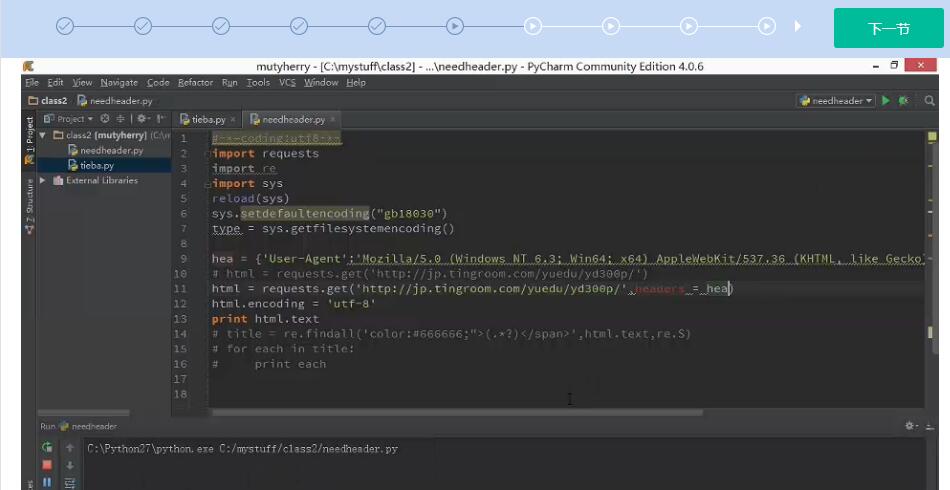
7.向网页提交数据



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



















 5750
5750





