







1. 摘要
广告创意是展示商品内容、传达商家营销信息的直接载体。商家通常会为一个商品创作多种不同的创意,由于不同用户的关注点不同,这些候选创意所对应的投放效果则相差甚远。创意优选的目的是学习用户对于广告创意的偏好,为用户挖掘及展现最具吸引力的广告创意内容以最大化广告收益。然而,目前业内普遍的做法是将创意优选放在排序阶段之后,这将导致排序模型无法感知到广告创意,即广告内的创意选择无法影响广告间的排序,一个好的创意排在前面,会影响后面广告间的排序。针对这些问题,本文提出了一种新颖的创意优选级联结构(Cascade Architecture of Creative Selection,简称CACS),在广告排序阶段之前构建创意优选模型,以实现广告内创意优选和广告间排序的联合优化。
考虑创意优选前置所带来的效率和效果问题,我们主要做了以下工作: 1)设计一个经典的双塔结构来降低计算成本,并允许创意优选模型生成的创意表征与下游排序模型共享,避免重复计算;2)提出一种基于软标签序学习蒸馏方法(soft label list-wise ranking distillation),从强大的排序模型中提取知识来指导创意优选模型中广告内创意序的学习。除此之外,设计一种自适应 dropout 网络,鼓励模型以一定概率忽略 ID 特征,而偏向于内容特征,来平衡 ID 特征的记忆性和内容特征的泛化性,以学习创意的多模态表示。最重要的是,排序模型从 CACS 中获取到了每个广告的最优创意信息,并最终提升排序模型的效果。大量的实验结果证明了该方法在离线和在线评估中的有效性和优越性。基于该项工作整理的论文已发表在SIGIR 2022,欢迎感兴趣同学阅读交流。
论文:Joint Optimization of Ad Ranking and Creative Selection
2. 背景
创意是广告的呈现方式,它可以将丰富的产品信息以视觉的方式快速地传递给用户。尽管同一广告的不同创意代表了相同的产品,但因为展现样式上的差异,它们的点击率通常会相差甚远,因此根据用户的偏好个性化展示创意是至关重要的。淘宝搜索广告系统目前采用客户、计划、推广单元、创意的多级账户体系,如图1(a),推广单元(ad)和商品(item)通常为一一对应关系,在每个推广单元(adgroup)下广告主可以提供多组创意(creative),每组创意可以设置单独的创意标题和创意图片,这种产品设计一定程度上给广告商品提供了个性化样式展示的空间。
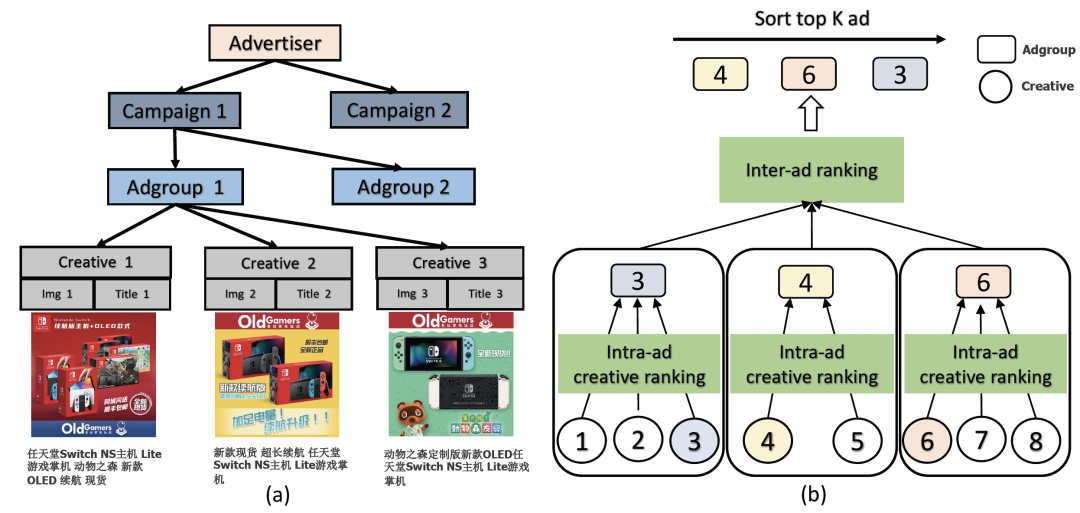
考虑到系统性能和效果的平衡,传统广告多阶段系统分为召回(Ad matching)、排序(Ad ranking)和创意优选(Creative selection)阶段。现有的创意优化工作都是在这个架构下集中在创意优选环节,虽然取得了不错进展但是影响面有限。排序阶段考虑到系统性能问题无法扩展到创意粒度,否则打分规模需要翻数倍无法接受,所以该阶段无法感知实际展现的最优创意(包括打分粒度在 Ad、随机选择创意、离线选择非个性化最热门创意等手段)这对于 CTR 预估而言有较大的提升空间。
理想的多阶段架构应该是召回、创意优选、排序,即先进行广告内的创意优选,然后排序阶段可以感知最优创意,从而使得系统收益最大化。但理想的架构会面临性能和效果的双重挑战,1)性能方面:创意优选前置打分个数量级的扩大,计算开销显著增加;2)效果方面:创意优选前置会面临更多没有机会展现的创意或者展现机会较少的创意,加剧了数据稀疏问题,使得基于历史反馈的学习策略有很大挑战且内容侧与id侧特征的联合学习尤为重要。
针对上述问题,本文提出了一种新颖的创意优选级联架构(Cascade Architecture of Creative Selection,简称CACS),将创意优选模块前置到排序阶段之前,以关联广告内的创意优选和广告间的排序,如图1(b)。为了提高系统性能,我们做了以下工作: 1)设计了一种经典的双塔结构,可以通过简单的双塔内积直接预测分数; 2) 创意优选模型产生的创意表征与下游排序模型共享。为了提高系统的效果性,我们提出了 1)基于软标签序学习蒸馏方法(soft label list-wise ranking distillation),学习同一个广告内创意的相对顺序而不是绝对分数,并提取排序模型的知识来指导创意优选模型的学习;2)融合创意 ID 特征与内容(图像、标题)特征,以缓解数据稀疏问题。通过自适应 dropout 网络,根据展现量自适应调整 dropout 比例,以鼓励模型忽略 ID 特征,而选择内容特征来学习创意的多模态表征。
该项工作主要成果总结如下:
我们将创意优选模块构建在排序阶段之前,同时通过高效的级联结构,优化了广告内的创意选择和广告间的排序;
从效率和效果上考虑,我们设计了以下策略: 1)设计经典的双塔结构,降低计算成本,此外在创意优选和排序之间共享创意表征,避免重复计算; 2)提出一种基于软标签序学习蒸馏方法,从强大的排序模型中“蒸馏”知识来指导 CACS 学习,并设计一个自适应 dropout 网络来平衡 ID 特征的记忆性和内容特征的泛化性;
大量的实验结果证明了我们的 CACS 方法在离线和在线实验中的有效性和优越性。
3. 方法
CACS 的总体框架如图2所
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 619
619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









