






✍🏻 本文作者:俊广、卓立、凌潼、青萤
1. 背景
随着在搜索、推荐、广告技术上多年的迭代积累,业界逐步形成了召回(匹配)、粗排、精排这一多阶段的系统架构。其中,召回作为链路的最前端,决定了业务效果的天花板。召回阶段的主要目的是从全量广告库中高效筛选高质量top-k集合给后链路进一步打分&排序。近年来,随着机器学习,尤其是深度学习技术的发展,学术界及工业界已经全面进入到了 model-based 召回算法的研究与应用阶段。其中阿里妈妈代表性的工作有:TDM 系列算法[1-3]、二向箔索引算法[4]。在model-based的召回模型中,主要基于离散ID来描述广告和用户,这种方式直接针对最终目标进行优化,具有很高的优化效率,也非常适合个性化推荐的需求。但是,只使用离散ID模态进行个性化推荐存在以下几方面的问题:
信息不全:真正给用户展现的是商品创意、标题等图、文、视频模态信息,而非离散ID。
泛化性不强:ID类特征无泛化性,因此完全基于离散ID特征的推荐系统在长尾商品、冷启广告等低频ID上存在预估不准的问题。
与ID模态相反,图像、文本等内容内容模态泛化性强,对新广告友好,更接近用户感知,但是内容模态的个性化能力差,不容易针对广告召回的目标进行优化。例如在淘宝上可能存在多个商家使用相同的图片,但是这些店铺的信誉度有好有差,广告主的出价有高有低,内容模态都无法将其有效区分开。
离散ID模态和内容模态在分布、形态、优势上均存在明显的差异,在本文中我们将探索在展示广告的召回模型中如何将ID模态和内容模态进行融合,并提出了混合模态专家模型的设计。
2. 模型召回的形式化目标及检索方法介绍
图文内容模态主要反映了用户的兴趣偏好,因此我们这里重点介绍在以用户兴趣作为目标的召回模型中引入多模态的方法。用户兴趣召回模型是展示广告召回的主力通道之一,一方面它保障了召回的结果满足用户的兴趣和需求,另一方面避免系统陷入数据循环,保障系统的长期健康。
在用户兴趣建模中,为用户 从全库候选集 挑选出商品 的概率为:
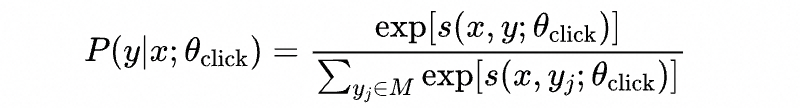
其中 表示用户 对商品 的兴趣分,对应的优化目标为:
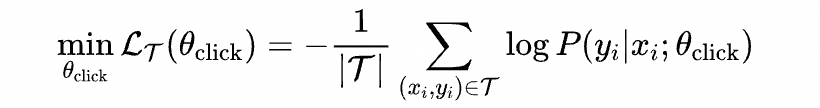
其中 表示用户在全域中的兴趣行为(点击为主,也包括购买、收藏、加购)。
推理时的目标是从候选集中找到用户点击概率最高的一个子集:
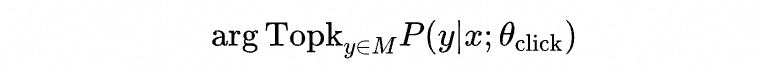
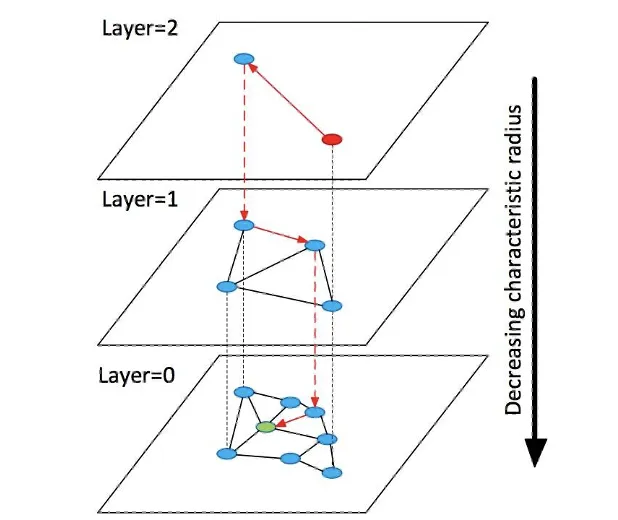
为了降低在线serving时的推理时间,我们采用了二向箔检索框架[3]来减少模型打分量。如下图所示,在推理时,首先会对Layer=2层的所有商品 计算兴趣分 ,从中挑选出兴趣分较高的商品,然后在HNSW层次化图结构进行扩展,得到Layer=1层的候选集,之后继续对扩展出的商品候选 计算兴趣分,这个过程迭代进行,直至抵达Layer=0层。通过二向箔检索,我们可以将千万级别的候选库打分量降低至万级别,同时检索精度依然接近90%。二向箔检索框架使得我们可以用相对复杂的模型结构来建模用户对商品的兴趣分,这也是我们后面引入混合模态专家召回模型的重要基础。
3. 混合模型专家模型
本节将介绍我们在用户兴趣建模中如何引入多种模态的信息,来提高用户兴趣的建模能力。多模态召回的主要目标是通过引入多种模态的表征,使得模型更好地拟合或反映真实的价值度量函数。这个目标可以进一步分解为三个关键问题:
模态选择:对于召回任务,需要明确选择哪些模态来描述广告或用户。哪些模态最适合用于召回的任务?
模态表征优化:一旦确定了使用的模态,接下来的问题是如何在给定模态后优化其表征。这涉及到模态表征的训练和优化策略。
模态融合:在获得不同模态的表征后,需要解决如何融合这些模态以训练最终的召回模型。这一步是确保不同模态信息有效协同工作的关键。
3.1 模态选择
在个性化推荐系统中,使用最为广泛的模态是离散的ID模态,例如我们会使用性别、年龄、地理位置等ID特征表述用户,使用商品、店铺、类目等ID特征描述商品。商品侧天然地存在一些其他模态的信息,例如商品的文本和图像,但是用户侧并不存在类似的文本或者图像。幸运的是,在电商场景下往往存在丰富的用户行为序列,因此我们可以将用户行为过的商品的文本或者图像序列作为用户侧的内容模态特征。
在实践中,我们发现图像单一模态更适合排序任务,而图文融合模态则更适合召回任务。这是因为召回需要从全库商品中进行筛选,全库商品中存在大量的负样本(无关样本),而文本这种粗粒度的特征对这些负样本的判别性更强。在排序任务中,候选集往往已经是相似的商品,因此图像这种细粒度的特征的判别性更强。下图中提供了图像单一模态的一些badcase,可以看到图像模态的表征确实可以检索出视觉上较为相关的广告,然而却忽视了实际的语义(例如艺术体操鞋检索出的是婴儿地板鞋和老年人手套,清洁剂检索出的是苏籽油、清凉油和食用油,游戏机检索出的是刻录机、打印机和遥控器)。与此相比,图文融合模态能够更好地弥补这一缺陷,找到的是同一类目下外观相似的商品。



3.2 模态表征优化
图像和文本模态的表征往往需要使用更深的模型结构,优化时需要采样更多的负样本,同时训练完成之后对于参数更新的需求较低;而ID模态的表征需要的网络层数更浅,但是需要根据回流的数据实时更新模型参数。考虑到这两种表征的差异,我们采用了分离的训练方式:首先使用对比学习获得商品的图文预训练表征;然后将这些已经训练完毕不再更新的商品图文表征引入到原始的召回模型中,使用标准的Sample Softmax Loss 对召回模型中的ID表征进行优化。接下来我们简要介绍图文内容模态的表征预训练方法。
我们使用阿里电商行为数据构建了图文的正样本对,对图像和文本分别用ViT[6] 和BERT[7]进行编码后,输入融合编码器得到融合特征,在融合特征上使用了对比学习[8]进行训练。同时,我们采用了跨 batch 的负样本采样和在线难样本挖掘策略,力求增加训练过程中的负样本的难度,提升商品的同款率和相关性指标。整个训练的模型架构如下图所示:
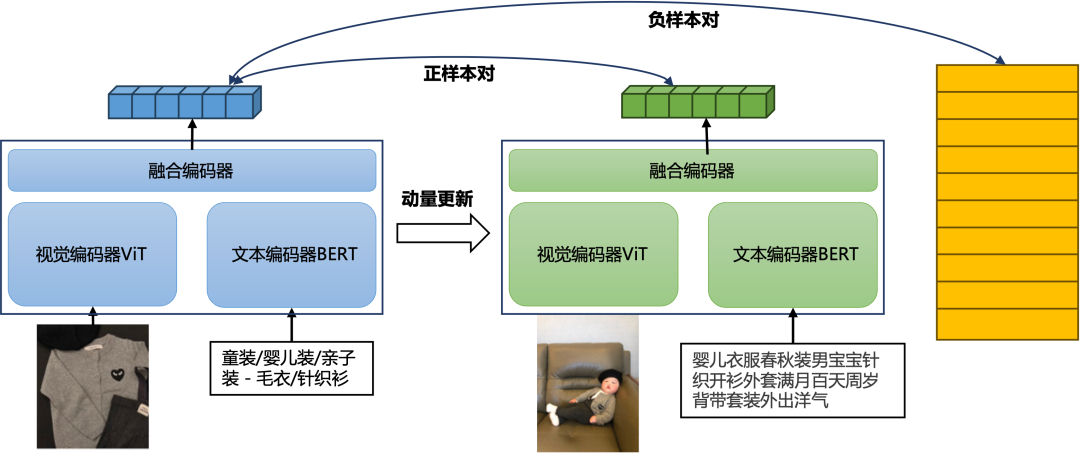
3.3 模态融合
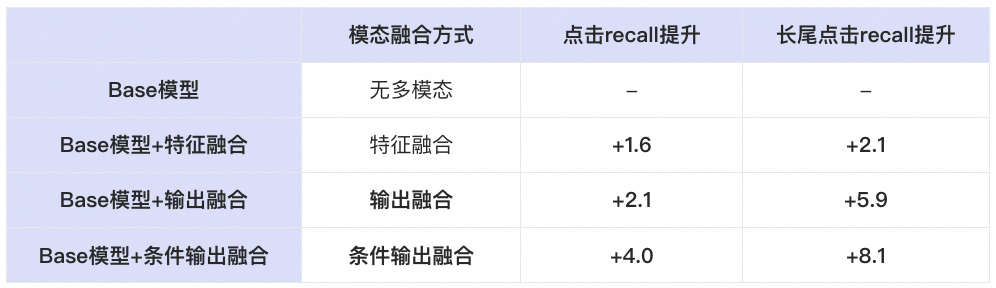
3.3.1 特征融合
离散ID模态和图文模态的表征空间存在较大差异,直接在召回模型中加入图文表征适配困难。而图文模态的余弦空间(用户行为和目标广告的余弦)和模型目标更加接近,且更容易适配。因此我们将用户侧行为序列图文特征和广告侧图文特征逐一计算余弦值,然后对余弦序列进行直方图统计后再作为召回模型的特征。这种方式减少了内容模态和ID模态在特征空间上的差异,降低了特征融合的困难。直接将其用于兴趣召回模型,点击recall+1.6pt,长尾点击recall+2.2pt (recall:用户点击正样本被模型召回为 top-1000的比例)。
然而特征融合依然存在着一些问题:
难以分析和监控不同模态的作用。神经网络是一个相对黑盒的模型,在项目开发初期中,当测试指标不变时,我们很难验证是某种模态本身没用,还是因为在特征融合中被其他模态的作用给压制了。在项目上线后,我们也难以监控随着模型不断地训练,每个模态是否依然正常发挥着作用。
没有显式建模模态自适应性。一个理想的特征融合模型应该能够自适应地结合ID模态和内容模态特征。例如,对于高热商品,应该更多地关注ID模态特征,而对于长尾冷启商品,应该更多地关注内容模态特征。然而特征融合的范式下,难以直接验证模型能否学习到这种自适应性。
3.3.2 输出融合
为了更好地分析理解ID模态和内容模态在用户兴趣建模中的作用,我们借鉴了集成学习的思想,尝试在输出层面进行模态的融合。具体而言,模型中包括纯ID模态专家输出的兴趣分和纯内容模态专家输出的兴趣分,其中和分别表示用户和商品。最终融合的兴趣分是:
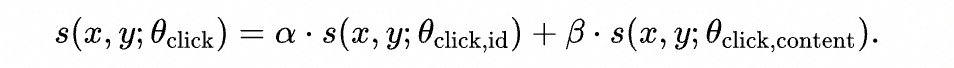
其中和是可学习的参数,,以及均使用全部数据进行训练,它们的区别来自于假设空间的差异。在相同的兴趣数据训练集上进行多任务优化后,
纯ID模态专家、纯内容模态专家、输出融合模型的训练准确率依次为~79.3%, ~48.3%, ~79.5%,可以看出纯ID模态专家拟合训练集的能力远高于纯内容模态专家。
纯ID模态专家的权重,纯内容模态专家的权重。说明输出融合模型最终主要依赖ID模态,但是内容模态确实也对最终的结果产生了影响。
在测试集上,输出融合模型相比于特征融合模型,在点击recall上+0.5pt,在长尾点击recall上+3.7pt,长尾广告的涨幅更加明显。说明直接在输出上进行模态融合更能发挥内容模态泛化性强的优势,反过来其实说明了特征层面的模态融合可能并没有充分挖掘内容模态的优势。
3.3.3 条件输出融合
进一步地,我们希望能显式地建模输出融合模型在不同热度商品上的模态自适应性。长尾冷启与高热商品最显著的差别是它们的淘内点击量,因此我们将其作为融合权重的条件输入,最终融合的兴趣分是:
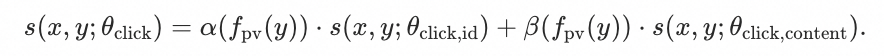
其中是对点击量进行了取log然后离散化分桶处理后的结果。
下图给出了训练得到门控权重和之间的关系曲线,可以看出:
对于长尾冷启商品,也就是减小时,内容模态专家的门控权重增大,ID模态专家的门控权重减小,因此模型逐渐增加对内容模态的关注。
对于高热商品,也就是增大时,ID模态专家的门控权重增大,因此模型的输出更加依赖ID模态。
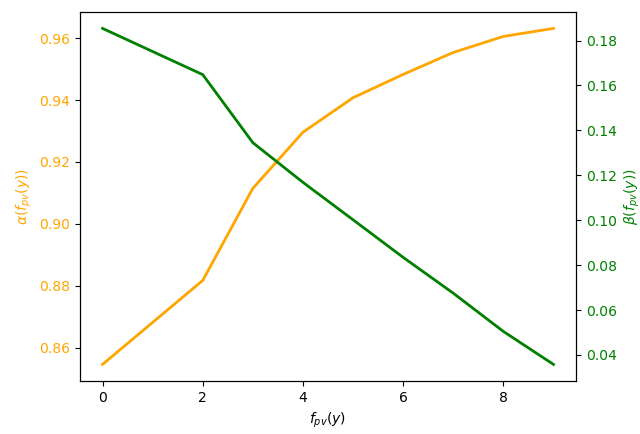
注意到在淘内点击量接近于0的时候,ID模态专家相比于内容模态专家依然占据主导地位,原因是ID模态中不仅包括item_id等非常个性化的特征,也包括类category_id、shop_id等相对更加泛化的特征,因此在点击量接近于0的商品上的预估依然具有意义。
输出层面的条件融合模型,显式建模了不同热度商品上的模态自适应性,相比于输出融合模型,在点击recall上+1.9pt,在长尾点击recall上+2.2pt。在长尾和非长尾上均有提升,说明模态自适应性对于不同热度的商品均有意义。
我们将最终得到的兴趣召回模型称为混合模态专家模型(Mixture of Multi-Modal Experts, MoMME)。下图给出了完整的架构图,其中黄色的部分是ID模态专家,绿色的部分是内容模态专家,通过商品点击量作为门控单元的输入,对ID模态专家和内容模态专家的输出进行了条件融合,得到用户兴趣分数。
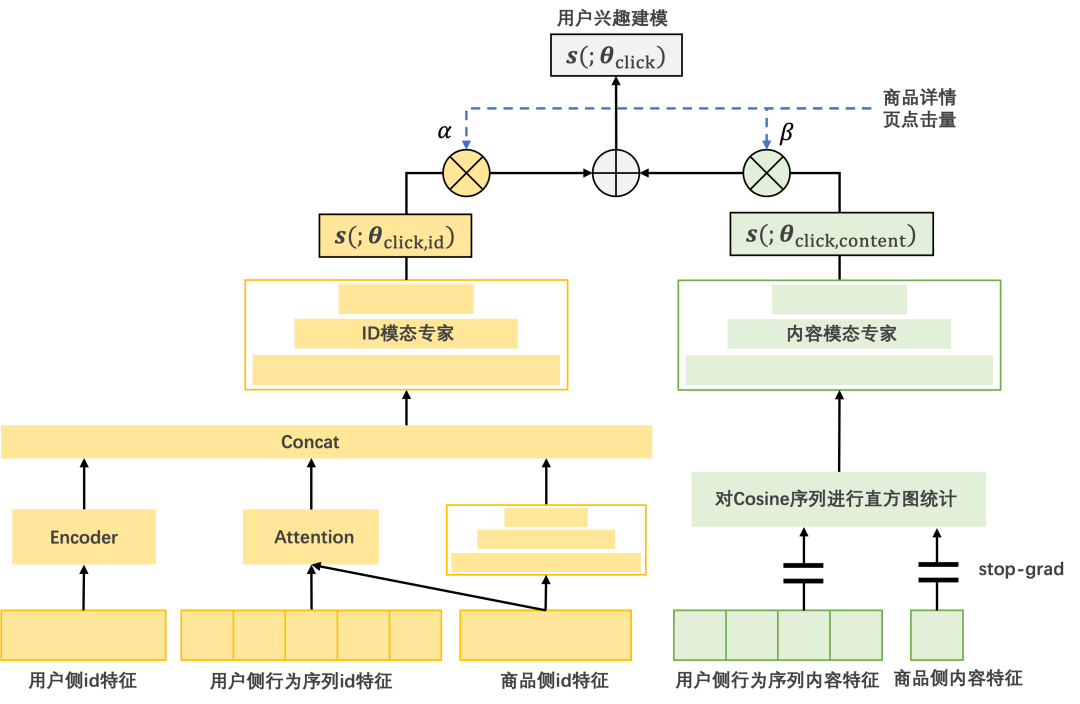
4. 实验结果
离线指标:各部分对于兴趣召回模型的点击recall (用户点击正样本被模型召回为 top-1000的比例)的影响总结如下。引入多模态特征后,我们取得了点击recall+4.0pt、长尾点击recall+8.1pt的显著提升。
在线指标:整体升级已在展示大盘主要场景全量,累计贡献展示大盘收入+2.33% / CTR+0.82%。全场景长尾广告(广告库占比较高但消耗占比较低)展现点击消耗相对涨幅均大于非长尾部分:PV+5.24%。
🏷 关于我们
我们是阿里妈妈展示广告Match团队,负责阿里妈妈展示及内容广告业务中的算法研发工作。团队在大规模检索、多场景建模、用户兴趣建模、冷启动、无截断召回系统等方向上持续深耕,用持续的技术突破和创新带动业务增长;结合深入的业务理解和大模型等前沿技术,实现广告算法迭代体系与投放模式的突破。欢迎感兴趣、聪明靠谱的小伙伴加入我们~
✉️ 简历投递邮箱:alimama_tech@service.alibaba.com
▐ 引用
[1] Han Zhu, Xiang Li, Pengye Zhang, Guozheng Li, Jie He, Han Li, and Kun Gai. Learning tree-based deep model for recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (2018). 1079–1088.
[2] Han Zhu, Daqing Chang, Ziru Xu, Pengye Zhang, Xiang Li, Jie He, Han Li, Jian Xu, and Kun Gai. Joint optimization of tree-based index and deep model for recommender systems. Advances in Neural Information Processing Systems 32 (2019).
[3] Jingwei Zhuo, Ziru Xu, Wei Dai, Han Zhu, Han Li, Jian Xu, and Kun Gai. Learning optimal tree models under beam search. In International Conference on Machine Learning (2020), 11650–11659.
[4] Weihao Gao, Xiangjun Fan, Chong Wang, Jiankai Sun, Kai Jia, Wenzhi Xiao, Ruofan Ding, Xingyan Bin, Hui Yang, and Xiaobing Liu. Deep Retrieval: Learning A Retrievable Structure for Large-Scale Recommendations. arXiv preprint arXiv:2007.07203 (2020).
[5] Rihan Chen, Bin Liu, Han Zhu, Yaoxuan Wang, Qi Li, Buting Ma, Qingbo Hua, Jun Jiang, Yunlong Xu, Hongbo Deng, Bo Zheng. Approximate Nearest Neighbor Search under Neural Similarity Metric for Large-Scale Recommendation. CIKM (2022).
[6] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ICLR (2022).
[7] Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. ACL (2019)
[8] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, Ross Girshick. 2020. Momentum Contrast for Unsupervised Visual Representation Learning. CVPR (2020)
END

也许你还想看
丨TDM到二向箔:阿里妈妈展示广告Match底层技术架构演进
丨KDD'23 | CC-GNN:基于内容协同图神经网络的电商召回方法
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”哦ღ~
















 109
109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









