







✍🏻本文作者:雨行、列宁、阿洛、腾冥、枭骑、无蹄、少奇、持信等
一、阿里妈妈智能创意服务介绍
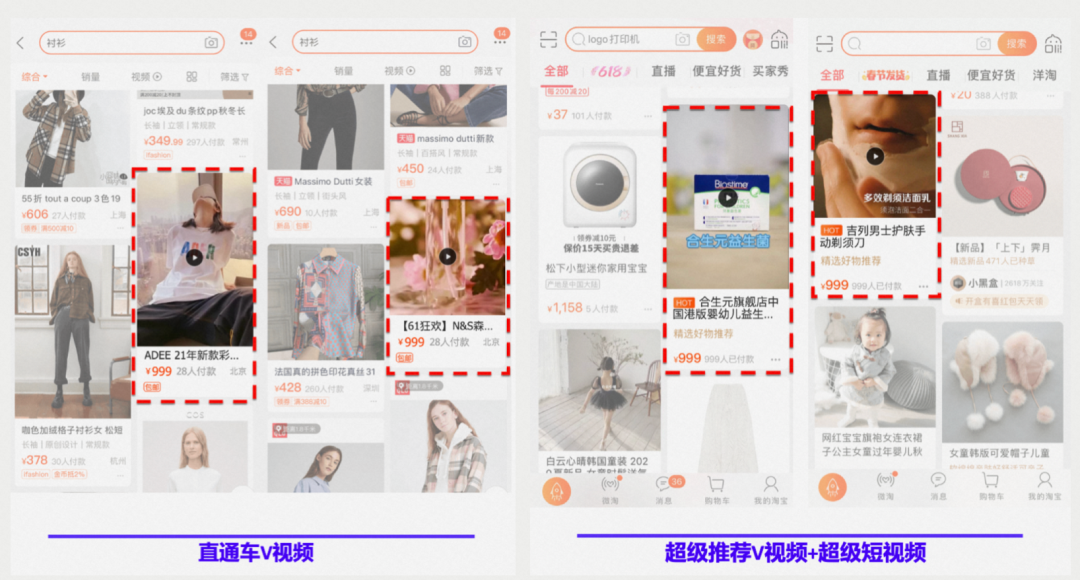
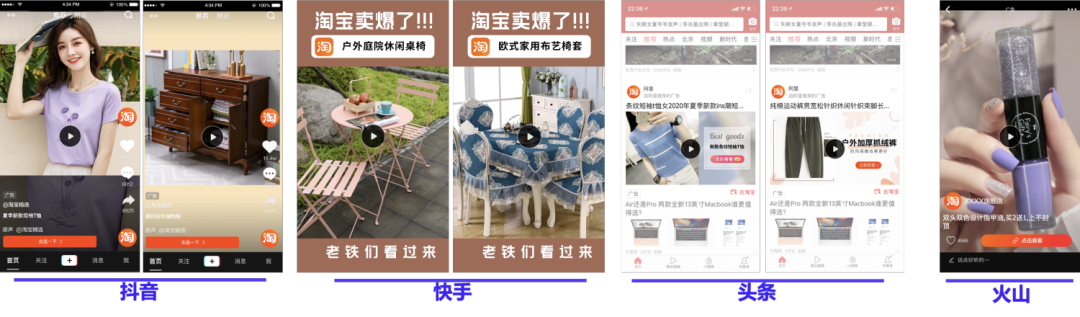
随着短视频逐渐成为人们表达自我和生活的主流媒介之一,各大短视频平台也得到了迅猛发展,短视频流量已经成长为互联网优质流量阵地之一,短视频的供给和消费都呈现出爆发式增长。在这个背景下,阿里妈妈智能创意服务,借助当前主流的深度学习算法,自动高效的为商品产出创意视频,大大丰富了广告的表现形式,既有视觉美学价值,还能提高用户的点击率,提升投放效果。目前,该服务已经在阿里妈妈各个广告业务场景中得到大量应用,其中包括搜索直通车、淘宝直播、抖音快手外投等。下面就是智能创意广告的部分展示场景。
为实现上述功能,需要许多深度学习模型来支持,主要包括视频和文本两大类,具体如下:
1.视频类:
3D Convs Net:单模态视频模型,主要采用三维卷积算子,提取视频前后帧之间的信息。
Visual Transformer:多模态视频处理模型,能够将图片、文本等信息融入视频语义理解中。
2.文本类:
Transformer / GPT-2:文本生成模型。使用场景如商品介绍文案自动生成,"这是一款保暖舒适的被子,选用了轻盈纤维棉,蓬松轻柔且透气性好,有效锁住热量,让被身更加轻盈保暖。加上轻柔的结构,让你的体重轻松达到零负担,更加舒适。"
为淘宝海量的商品自动生成创意视频,是个巨大的工程。而现有的服务性能以及GPU数量,不足以处理全量的商品,因此对智能创意服务的优化需求非常迫切。通过对现有服务架构的分析,我们决定进行两方面的优化:一是从服务流程的角度进行优化,二是对视频和文本两大类模型自身进行优化。下面我们以实时创意短视频生成服务(以下简称短视频生成服务)为例,介绍我们在智能创意服务的优化工作。
短视频生成服务,是从一个商品介绍视频中抽取出5秒的精彩瞬间。该服务根据商品主图、商品描述,从广告主上传的视频中,计算出相似度最高5秒。比如下面这个场景:
商品描述:"316儿童可爱保温杯子吸管幼儿园小学生上学男女高颜值壶宝宝水杯"
商品主图:

选取出的宽高比1:1的5秒精彩短视频如下:
当商家新建一个推广计划时,如果商品中有视频内容,那么系统会自动触发调用一次短视频生成服务,基本流程如下图:

其中,虚线框内部分是短视频生成服务的主体。该服务接收到商品id后,下载商品的创意视频、介绍文案以及商品主图,经过多模态视频检索模型,找出创意视频中与商品主图、介绍文案相似度最高的一个时间片段,再将该片段经过主体位置检测模型后,裁剪出不同宽高比的视频,如1:1, 2:3等以适配不同的终端。如果视频出现了介绍文字,还要经过OCR模型检测出文字的位置,避免文字的部分被裁剪掉。最后生成一个完整的精彩短视频。
在框架语言选择方面,虽然C++比Python更适合服务端开发,但是我们还是决定使用Python作为开发语言,主要考虑以下几个因素:
视频类模型需要对图片进行复杂的预处理和后处理操作,Python相较于C++开发更加便利,有利于算法同学自助开发上线;
目前业务正处于快速迭代期,而学术界最新的研究成果都是通过Pytorch+Python的方式公开,使用Python能够降低迭代周期。
但是直接使用PyTorch+Python进行部署的缺点也很明显,PyTorch的灵活性的代价是性能优化方面的劣势,性能比较差。这就给我们提出了优化PyTorch模型的业务需求,在追求计算性能的同时,还需要兼顾灵活性、易用性。
在服务框架选择方面,我们选取了Tornado V6.0版本,以HTTP接口形式对外提供服务。业务初期采用了Tornado的单线程的模型,每个服务同一时刻只能处理一条请求。但这种使用模式处理能力太低,因此我们首先尝试将单线程的服务升级为多线程服务,在T4显卡的性能如下表所示:
| 单并发 | 4并发 | |
|---|---|---|
| 吞吐:视频/分钟 | 6 | 12 |
| Latency | 9.6秒 | 18.9秒 |
| 模型推理Latency | 3秒 | 9秒 |
| GPU利用率 | 16% | 30% |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 581
581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









