






🏷 本文作者:御医、陌奈、列宁、陌瑶、加木、吉多
一、内容风控业务背景及挑战
1.1 业务背景
内容作为营销的重要载体,能够促进信息的交流和传播。在营销场景中,广告高曝光的特性放大了风险外漏带来的一系列问题,少数用户为了引流获利,可能会发布一些涉嫌违规内容,也存在部分用户对广告法的理解存在偏差,误发布涉嫌违规内容。对于发布平台而言,如果这些内容确实违反法律法规,将会影响用户对平台的正面评价。
因此,阿里妈妈的努力方向不光是使内容风控系统对变更的广告进行实时管控,还需要具备对百亿级别存量广告数据快速定位和清理的能力,迅速发现风险,防止涉嫌违规的内容扩大传播。
随着新一轮AI技术浪潮的兴起,阿里妈妈也推出了AI创意生产工具——万相实验室,助力商家实现0成本上新,推动电商进入“AI上新“新时代。但相比原有的业务场景,新业务在响应时效和风险特性上都存在很大差别,这对内容基础服务能力建设工作带来了更大的挑战。
1.2 面临的挑战
内容风险类型的多样性、变异性和迅速传播性等特征使内容风控面临巨大挑战,而新一轮AI技术浪潮的兴起对内容风险的防控能力、响应速度、计算资源以及成本管理都提出了更高要求。
1.2.1 业务的挑战
下面列举多种风险类型样例,上述特性导致防控过程中存在较大难度,且一旦外漏,影响可能难以控制。

1.2.2 技术的挑战
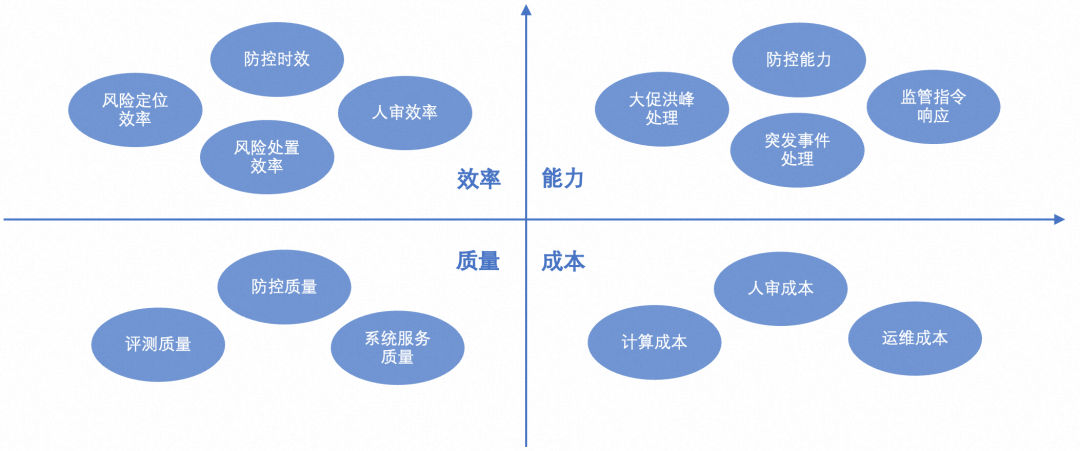
能力挑战:比如每次大促结束后,相关内容的素材会集中在凌晨修改去标,整个系统面临巨大压力;为降低涉嫌违规内容外漏的风险,需要具备对全量数据快速识别、清理的能力,及时响应下线。
效率挑战:AI交互式生成内容形式,需要在内容展示前进行风险拦截,对内容识别时效提出了更高的要求。
成本挑战:增量及存量内容数量急剧增加,图片、视频、直播内容风控计算成本较高,如何保障识别效率的同时,提升资源利用率、降低计算成本;部分风险机器识别准确率不高,需要人工进行审核,如何提高机器识别准确率,降低人审成本。
质量挑战:由于数据量大,涉及的业务众多,如何快速评价风控效果及判断漏出情况,如何评估整体风险防控质量。
二、AI驱动下的风控引擎演进
2013年开始,阿里妈妈在广告内容风险治理方面开始加大投入。持续迭代至今,内容风控建设主要经历了三个阶段,逐步从纯人工规则到算法辅助规则,再到数据和算法驱动的阶段演进。期间无论是在业务层面还是在技术层面,都经历了巨大的变化。接下来,我们将介绍风控技术体系演进过程中遇到的问题,并分享基于AI驱动下的风控引擎设计和思考。

2.1 业务抽象层面
第一阶段:快速从0-1搭建防控链路,采用规则作为主要的防控手段,其中包括配置管控词、黑名单/白名单以及根据商品信用、用户和店铺等信息进行风险防控。然而,这种防控手段相对单一,只能有效应对一些简单的风险。然而,风险是不断变异的,通过简单的变换就能轻松绕过规则的限制。例如,微信这个词可以通过各种方式进行变化(如VX、威信、徽信等),而图片上的风险更是难以在这个阶段进行有效的防控。
第二阶段:为了提升防控能力,我们逐步引入算法模型,对各类风险进行防控。如下图所示,我们提供了运营可以配置算法模型的功能,对应左上图中的规则配置中的操作符。这些表达式涉及到不同的模型防控能力。尽管我们引入了算法模型来进行风险防控,但整体流程仍然以规则驱动为主。然而,随着模型数量不断增加,通过手动调节阈值的方式很难使效果和计算成本达到最优。
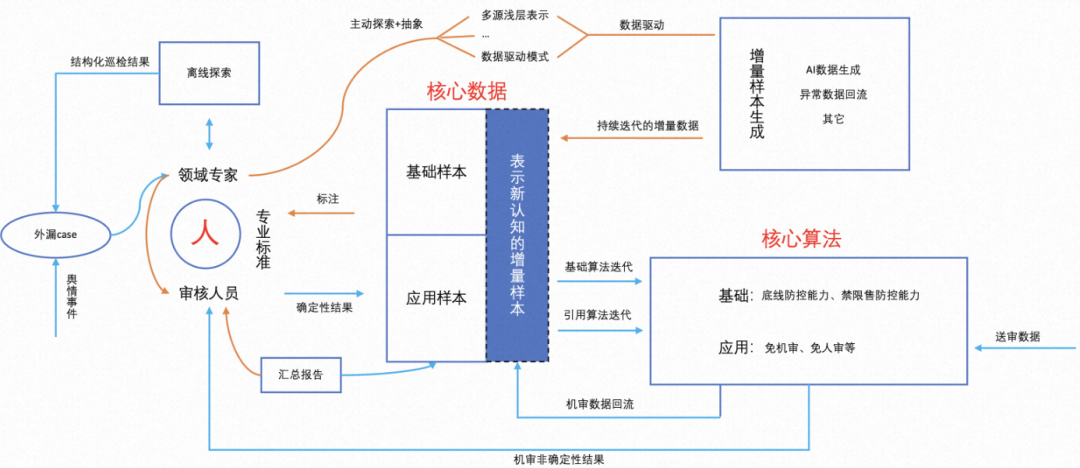
第三阶段:搭建通过数据+算法的方式驱动风险防控,人善于定义和发现问题,因此可以指导模型去解决问题及提供Base case辅助模型不断迭代及完善。针对业务定制化诉求及应急事件处理还需要人进行主动干预。下图是整个AI驱动流程,描述了样本、模型、领域专家在风控链路中的扮演的角色。
2.2 系统建设层面
第一阶段:主要涉及到词匹配、规则、及黑白名单系统,直接通过同步调用的方式,整体链路比较简单。
第二阶段:增加了模型及检索服务,模型服务由于RT较长采用异步(Metaq)调用方式,整个执行过程是以DAG形式表达,执行过程中需要读写状态。由于DAG节点较多(1000+)状态的管理已经成为性能瓶颈。而且异步链路无法保障返回时效,在强交互式的AI业务风控场景下,没法满足业务诉求。同时由于设计之初离线方面考虑较少,导致在离线表达和执行存在较大差异。为了解决以上问题且满足新的业务诉求,我们进行第三阶段的重构。
第三阶段:引入Serverless思想,将服务能力进行明确拆分,区分DataFlow和ControlFlow不同的职责,所有服务通过网关进行输出。DataFlow负责纯粹的样本构建工作,ControlFlow控制样本消费及最终结果流程。DataFlow中以DAG的方式并发的调度下游基础服务(模型、词匹配、检索等),在离线在逻辑及结果层面统一。
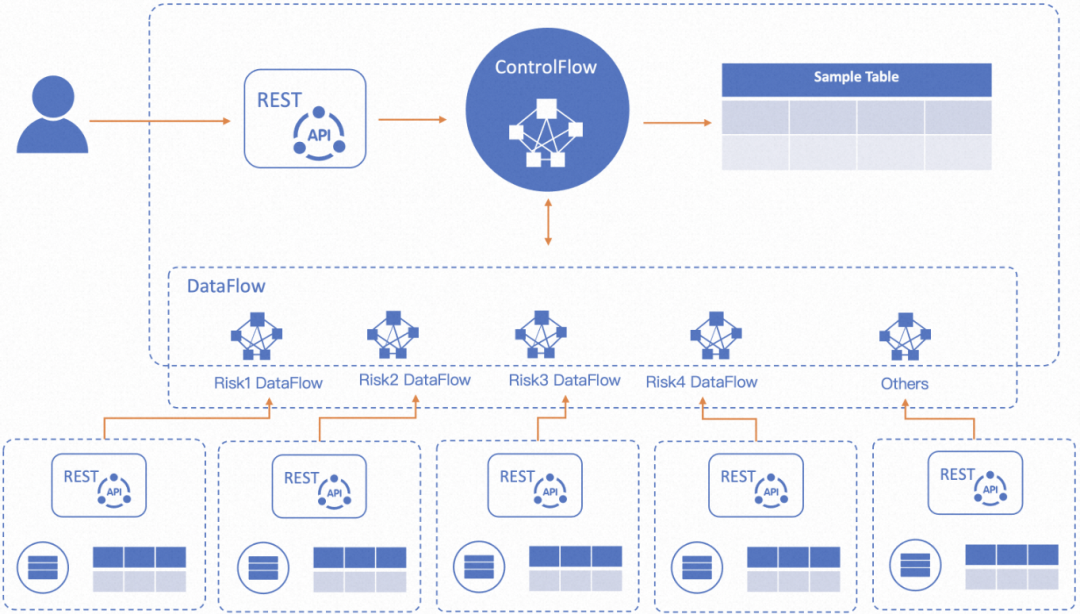
上面简要介绍了整体框架流程,没有做太详细的展开,后续可以专门介绍整体框架设计细节。本文主要重心在基础服务能力建设上,接下来的内容将重点介绍内容风控涉及的模型、检索、词匹配引擎建设过程,及整体叶子节点运维管控相关内容。
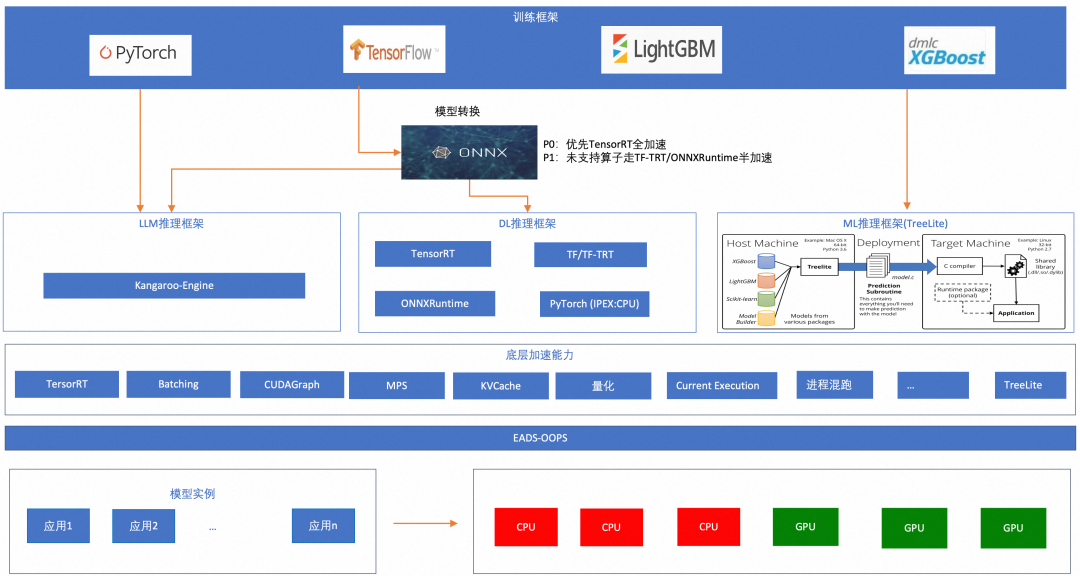
三、大模型时代的风控基础服务能力建设
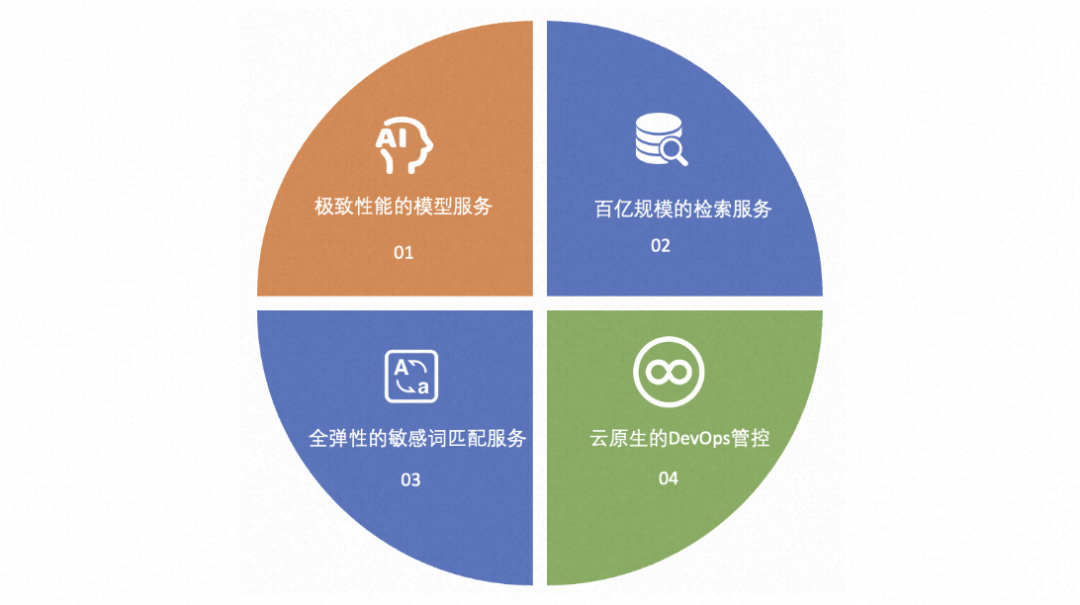
前面介绍了业务背景、挑战以及阿里妈妈内容风控演进的思路和整体方案,接下来重点介绍整体方案中涉及到的基础服务能力演进过程。内容风控核心建设的能力包括模型、检索、词匹配及Ops管控等。下面着重介绍这几个能力的建设过程。
3.1 极致性能的模型服务
去年我们重构了初版的模型服务能力,详见:阿里妈妈内容风控模型预估引擎的探索和建设。随着新一轮AI技术浪潮兴起,风控业务场景也在尝试“用魔法打败魔法”(如通过大模型识别图片中的内容转成文本,能够更好的理解图片中的内容),引入BLIP、CLIP等大模型进行风险防控。大模型对资源消耗较大,我们希望过滤掉一些确定没风险的内容以减少计算成本,因此启动了RiskFree项目,通过提取各个维度的特征采用XGB模型过滤掉没有风险的内容,从而减低模型计算量。针对以上业务诉求,我们在加速方面新增了大语言模型及传统机器学习两个方向的能力建设。
3.1.1 大语言模型加速
内容风控场景也在不断探索大模型在业务场景上的落地,应用大语言模型的认知解决深度模型难以解决的问题。在落地过程中遇到RT高,计算成本高等问题,我们调研了业界主流加速方案并进行对比,综合考虑,我们最终选择了基于CUDA Graph技术的自研加速方案。
3.1.1.1 主流加速方案简介
大语言模型加速方案也如雨后春笋般不断涌现,我们调研了市面上主流的大语言模型加速方案并进行对比如下表所示:
| 对比项 | vLLM | TensorRT-LLM | PLL.LLM | DeepSpeed-MII | AIACC-LLM |
|---|---|---|---|---|---|
| Github | https://github.com/vllm-project/vllm | https://github.com/NVIDIA/TensorRT-LLM | https://github.com/openppl-public/ppl.nn.llm | https://github.com/microsoft/DeepSpeed-MII | 暂无 |
| 公司 | UC伯克利 | NVIDIA | 商汤 | MicroSoft | 阿里云 |
| Batch | 是 | 是 | 是 | 是 | - |
| KVCache | 是 | 是 | 是 | 否 | 是 |
| INT8 | 是 | 是 | 是 | 是 | 是 |
| FP8 | 否 | 是 | 否 | 否 | 否 |
| 多卡并发 | 是 | 是 | - | 是 | - |
3.1.1.2 基于CUDA Graph的自研加速方案Kangaroo-Engine
TensorRT-LLM有望成为行业标准,但一方面正式发布较晚,不能满足业务的急切需求,另一方面从TensorRT-LLM对运行环境、镜像、驱动等要求较严格,像我们主流在用的T4、P100卡不在其支持范围之内。综合考虑我们自研了一套加速引擎Kangaroo-Engine。
Kangaroo-Engine是一个基于CUDAGraph对大语言模型进行优化的推理引擎,它的设计优势在于保留原生PyTorch易用性的同时,支持高性能的推理加速方案。下图将一组 CUDA 算子调用和其他 CUDA 操作组合在一起,并使用指定的依赖树执行。通过结合与 CUDA 内核启动和 CUDA API 调用相关的驱动程序活动来加速工作流程。
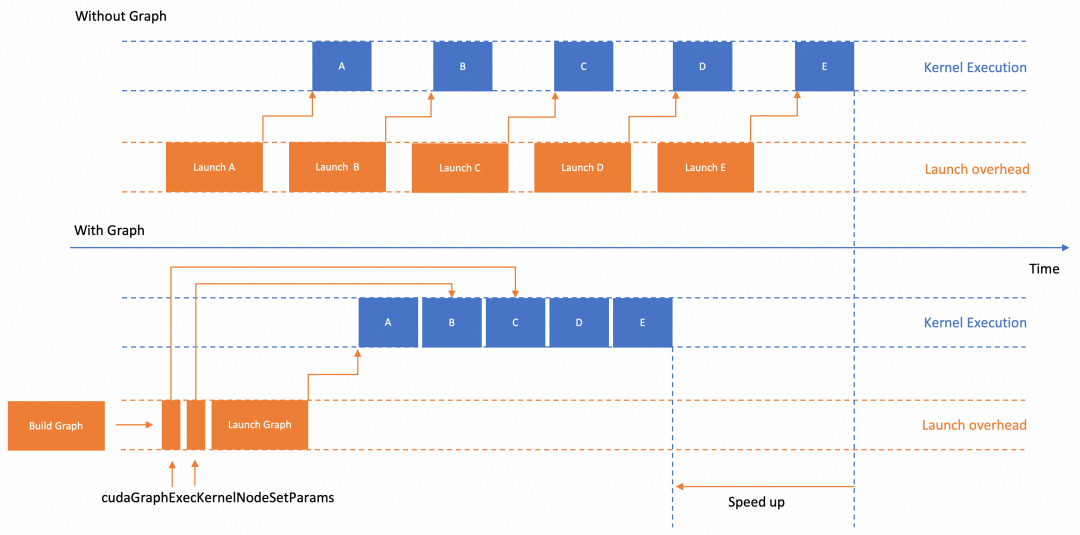
CUDAGraph没有广泛应用的核心因素是其苛刻的运行条件。模型必须是静态Shape,且输入输出的地址以及中间使用的地址都必须固定。如果上述变量有变化,要么需要重新Capture一个新的Graph,要么需要调用一个开销比较大的接口来修改CUDAGraph。而CUDAGraph会占用比较大量的GPU内存,导致不可用。
为了更加方便高效的使用CUDAGraph技术,Kangaroo-Engine实现了以下功能:
对动态Shape情况,进行多次CUDAGraph capture。
GPU内存复用。多个不同的Graph,复用GPU内存池,复用输入输出地址空间。
对不同Shape做分桶Padding,避免Graph过多,占用过多的GPU内存。
在对内容风控业务BLIP模型的优化过程中,Kangaroo-Engine可以将图生文BLIP模型在A10上的典型数据单并发单次推理RT降低约1倍,可以满足内容风控业务的需求。
3.1.1.3 在不同设备上的定制优化
针对内容风控P100板卡,无法使用MPS(Multi Process Service)来增加SM(Stream Processor)利用率的特点,我们利用不同Stream可以并行计算的特点,取得了约1/4的QPS提升。
针对Tesla T4计算卡相对来说带宽更低,FP16算力更高的特点,我们利用TensorRT 8.6 Engine充分利用TensorCore上的计算资源对矩阵乘进行优化,将ViT(Visual Transformer)的每个Block所需时间降低5倍。
3.1.1.4 优化效果
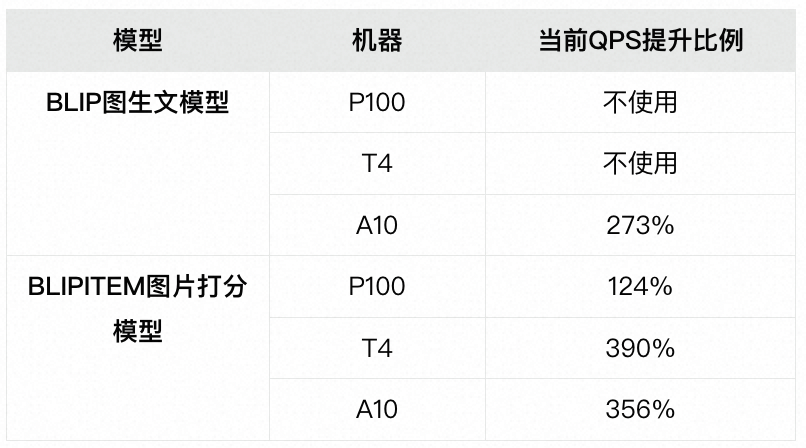 以上针对内容风控业务大模型,构造了服务优化 + 多进程多线程 + Kangaroo-Engine/TensorRT的优化方案。未来我们还将进一步尝试服务优化和低精度量化,为内容风控业务的大模型探索提供算力支持。
以上针对内容风控业务大模型,构造了服务优化 + 多进程多线程 + Kangaroo-Engine/TensorRT的优化方案。未来我们还将进一步尝试服务优化和低精度量化,为内容风控业务的大模型探索提供算力支持。
3.1.2 神经网络模型加速
针对神经网络模型的优化,我们在《阿里妈妈内容风控模型预估引擎的探索和建设》的工作基础上,增加了CPU、GPU分离能力,具体方案是将模型计算过程中依赖的CPU计算和GPU计算进行进程分离。可以避免因CPU计算瓶颈影响GPU性能,同时避免GPU内存大小限制了CPU进程数量导致性能瓶颈。缺点在于,CPU、GPU的通信需要通过共享内存,CPU和GPU进程通信需要序列化反序列化。对于较小的模型,这部分开销占比较大效果不佳,需采样原方案。详细设计如下图所示:
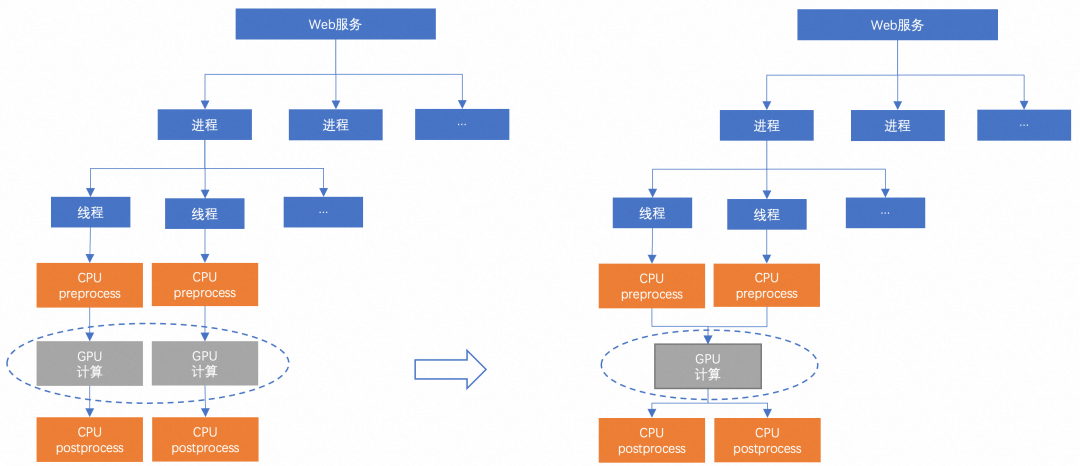
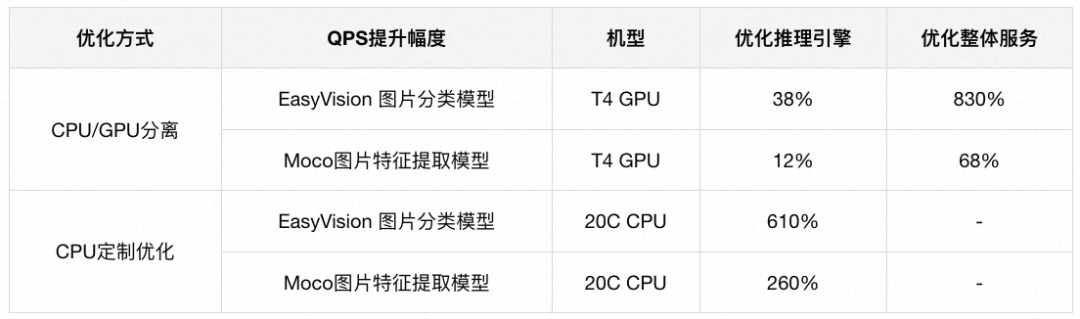
此外,由于内容风控业务经常会利用CPU资源来弥补GPU资源的资源缺口,我们针对CPU做了定制化优化。对于PyTorch模型,我们使用Intel提供的IPEX(Intel Pytorch Extension)进行自动转换和加速。对于Tensorflow模型,我们使用RTP自研Tensorflow版本,利用其中的Eigen以及MKL库进行加速。对于ONNX格式的模型,我们使用ONNXruntime进行加速。对人脸特征提取模型、涉政Logo模型、OCR模型、Easyvision图片分类模型、Moco图片特征提取模型,本地20 Core CPU压测QPS分别提升3~13倍。离线压测有约18倍的提升,方案细节如下图所示。
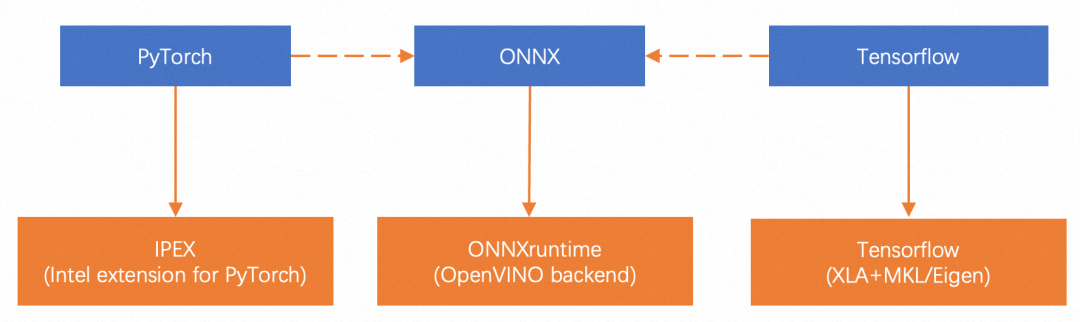
该功能用于以下两类模型,取得非常显著的优化效果:
3.1.3 传统机器学习模型加速
内容风控有很多特征数据,这些数据无法通过人工配置阈值的方式使用,需要借助传统的机器学习模型来辅助进行决策。这些决策场景对延迟较敏感,直接通过官方协议部署无法满足业务诉求,我们针对多种业界决策树推理方案进行了深入实验,最终我们选择了对于业务场景来说性能最好且最合适的决策树推理工具Treelite。
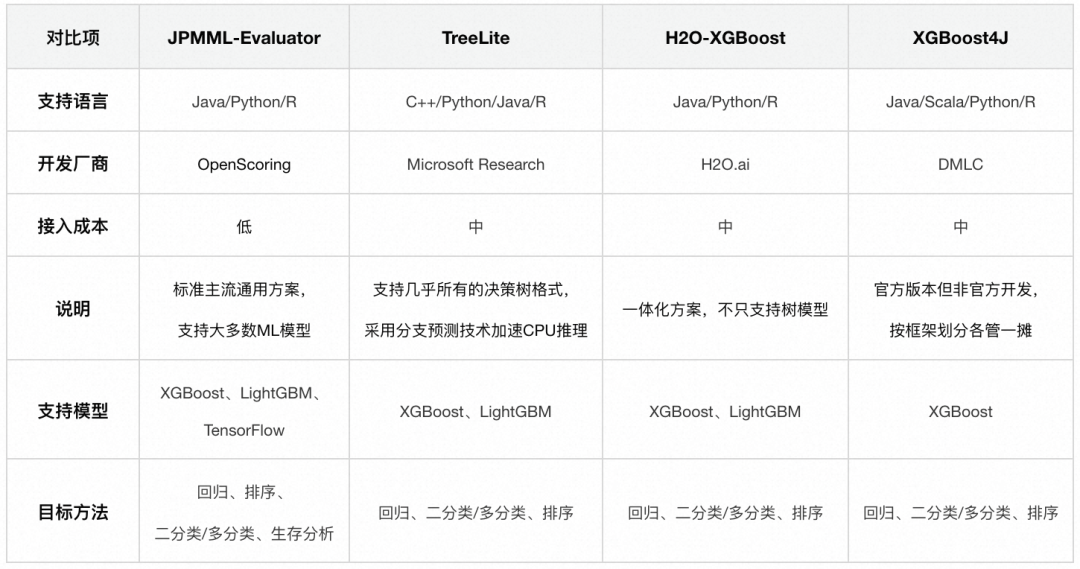
Treelite是一个决策树推理库,可以支持XGBoost、LightGBM、Scikit learn格式的决策树推理。可以把Treelite类比为决策树领域的ONNX。它也包括Treelite格式和Treelite runtime两部分。此外Treelite还集成了NVIDIA的FIL加速库,虽然当前业务用不到,未来还可以支持GPU加速。
Treelite在加速CPU推理的时候,会将决策树结构编译成.so文件,在指令层面对决策树的分支进行分支预测等优化,加快推理速度,在我们实测过程中,它的推理速度可以比XGBoost、PMML快一个数量级,我们采用Treelite作为通用的机器学习模型部署方案。
3.2 百亿规模的检索服务
3.2.1 业务背景
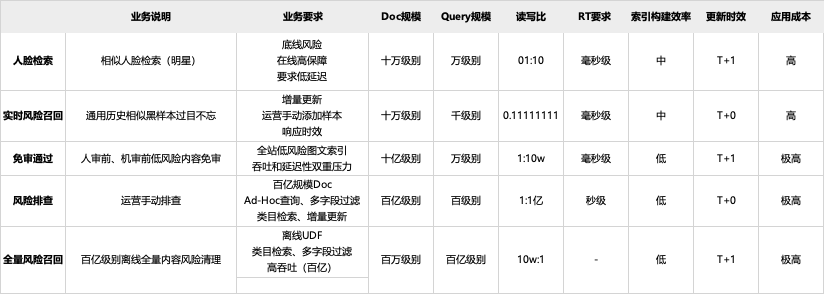
内容风控经过多年的发展,逐步形成了基于音、视、图、文模型的风险识别能力。但是由于风险变异快、对抗强,某些突发风险无法在短时间内积累足够多的样本来训练和升级模型,因此我们探索了类似拍立淘“以图搜图”能力,通过相似图文内容召回风险,满足快速响应、泛化识别的要求。下图展示了线上部分使用的内容风险相似检索用例:业务说明 业务要求 Doc规模 Query规模 读写比 RT要求 索引构建效率 更新时效 应用成本 人脸检索 相似人脸检索(明星) "底线风险 在线高保障 要求低延迟" 十万级别 万级别 01:10 毫秒级 中 T+1 高
实时风险召回 通用历史相似黑样本过目不忘 "增量更新 运营手动添加样本 响应时效" 十万级别 千级别 0.111111111 毫秒级 中 T+0 高 免审通过 人审前、机审前低风险内容免审 "全站低风险图文索引 吞吐和延迟性双重压力" 十亿级别 万级别 1:10w 毫秒级 低 T+1 极高 风险排查 运营手动排查 "百亿规模Doc Ad-Hoc查询、多字段过滤 类目检索、增量更新" 百亿级别 百级别 1:1亿 秒级 低 T+0 极高 全量风险召回 百亿级别离线全量内容风险清理 "离线UDF 类目检索、多字段过滤 高吞吐(百亿)" 百万级别 百亿级别 10w:1 - 低 T+1 极高
为了更好解决业务问题,我们对主流的检索方案进行调研,希望通过一套方案解决以上不同的业务问题
3.2.3 方案选型
早期在建设检索引擎的过程中,我们面向解决线上业务问题进行方案选型,采用了淘宝搜索的DII引擎。随着业务发展,遇到外漏Case需要紧急处理时,很难排查到具体问题,因为我们建设了北斗风险排查功能,将全量的图、文提取向量进行索引,能够通过外部截图等快速定位到问题。由于DII不支持实时更新,我们采用了淘宝搜索的BE引擎。遇到紧急管控事件时,需要对全量数据进行清理,与北斗功能的差异在于全量清理需要进行相当复杂的计算,部分任务依赖检索功能,我们采用ProximaCE进行离线检索计算。业务发展至今我们在解决检索相关问题用了三套方案,这也给我们服务质量、运维、开发等带来很多问题,主要有:
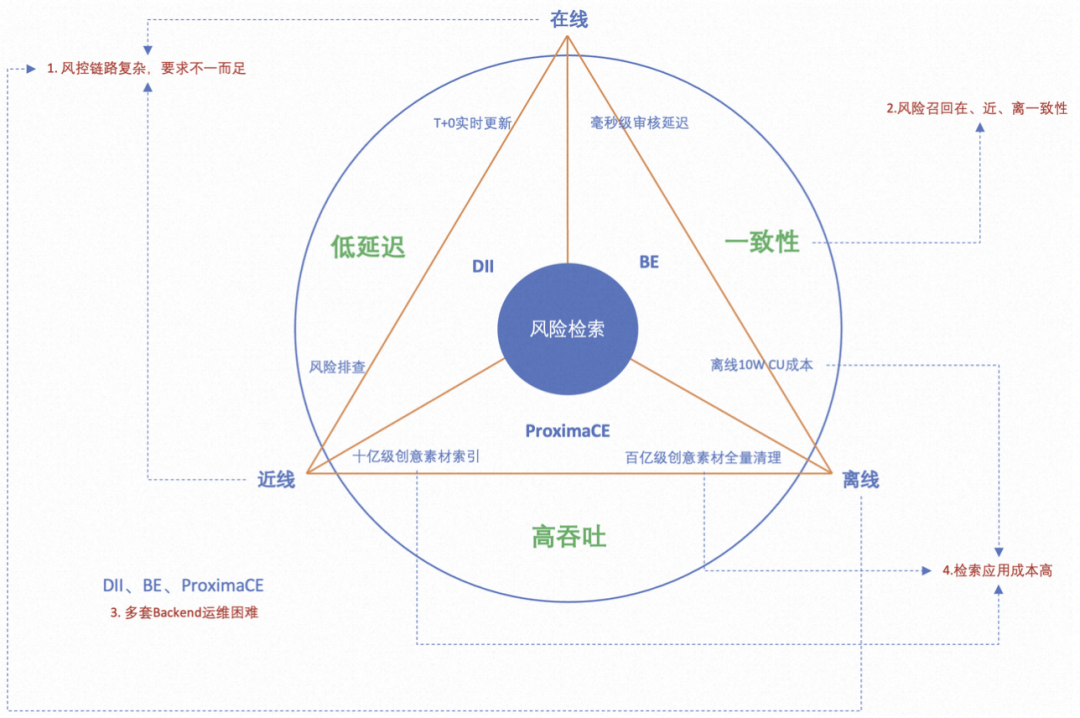
能力问题:多套引擎在离线一致性无法保障。在线基于BE或DII实现,离线基于ProximaCE实现,引擎在线和离线完全割裂,没有统一的Backend及索引,导致在离线检索结果无法完全对齐。
效率问题:多套系统操作和使用方式不一样,导致解决问题的效率降低
质量问题:检索服务稳定性问题。主要体现在DII版本较老,过去曾出现因为请求参数的向量维度与DOC不一致导致DII CoreDump的问题,不同的业务场景对检索系统的要求有较大差别。
成本问题:引擎接入使用方式不一致导致开发、运维成本上升
我们希望通过一套引擎能够解决检索在离线所有问题,通过调研发现内部的阿里妈妈自研超融合多模智能引擎Dolphin具备在离线一体的基础能力,因此我们与Dolphin团队同学合作共建,解决风控引擎遇到的问题。
3.2.4 检索核心方案
在线及离线的业务通过统一的引擎进行支持,在线、离线管控及运行环境存在一些差异,但底层的Dolphin VectorDB方案是统一的。在离线能够复用相同的索引文件,使用同一套Core执行逻辑,最终在原理上保障在离线统一,详见下图。
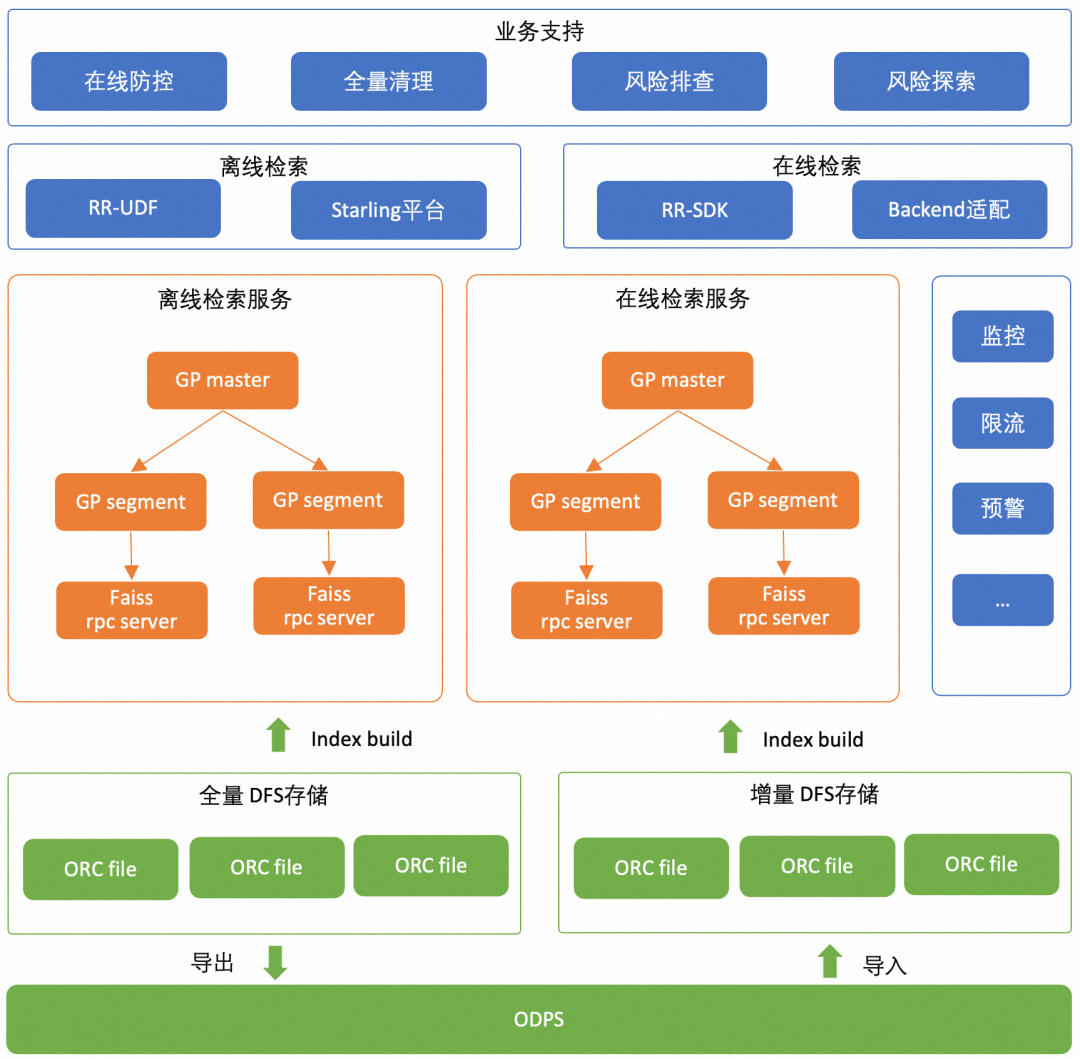
上图是业务整体框架,其中具体Dolphin VectorDB具体内核实现,详见《Dolphin :面向营销场景超融合智能引擎》。
3.2.5 业务效果
升级Dolphin VectorDB后我们在多个维度对系统进行效果评测及验证,如下:
在线检索能力:在小规模索引场景在线检索性能与BE相当,但在RiskFree超大规模10亿级索引业务场景存在显著成本和性能优势。
在离线一体:实现了真正的在离线一体,使用的索引一体、引擎一体,评测结果表明在离线检索结果精确到小数点后5位的数据一致率为100% ,业务一致率100%。
统一检索协议:统一基于RR协议接入业务,打通Dolphin作为Backend引擎,用户接入不同平台仅需掌握一种协议,大幅降低接入门槛。
统一管控平台:打通Dolphin管控和索引构建接口,业务接入效率由小时级提升至分钟级。
统一监控告警:构建统一的实时Dashboard,一个大盘即可对所有业务的核心指标(如: 错误量、吞吐、RT、机器水位)和配置(如: 是否黑库、表示算法、索引算法、距离算法)一目了然。
实时业务报表:一个页面展示所有业务数量、引擎分布、索引数量、详细配置等信息。
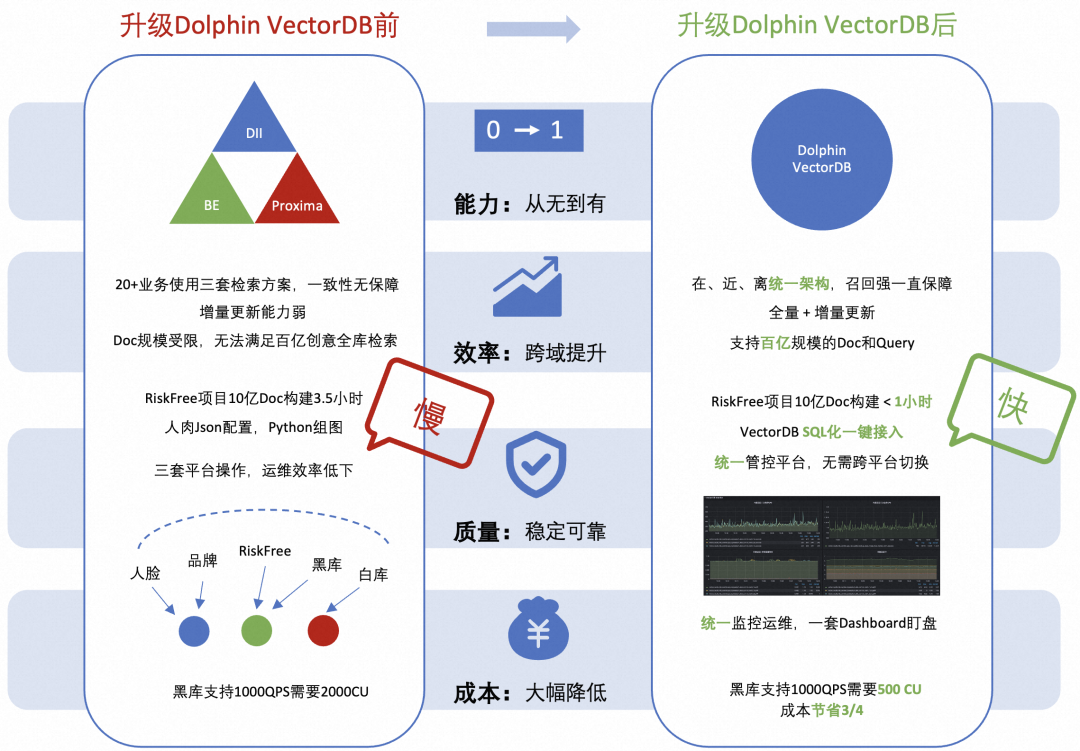
此外在开发成本方面,Dolphin VectorDB提供SQL数据库查询语法和产品化索引导入平台,新业务接入时效从小时到天级别提升到分钟级,开发效率提升非常大。
3.3 全弹性的敏感词匹配服务
词匹配服务是风控最古老也是最直接有效的系统之一,它的功能主要检测输入文本中是否存在风险词,匹配方式包括模糊和精确两种,类似字符串的Contains和Equals,当然真实使用的时候还包括加减词、通配等逻辑。具体管控的词由运营配置,按照词包的方式管理,如红线词包,敏感词词包等。
3.3.1 业务背景及遇到的问题
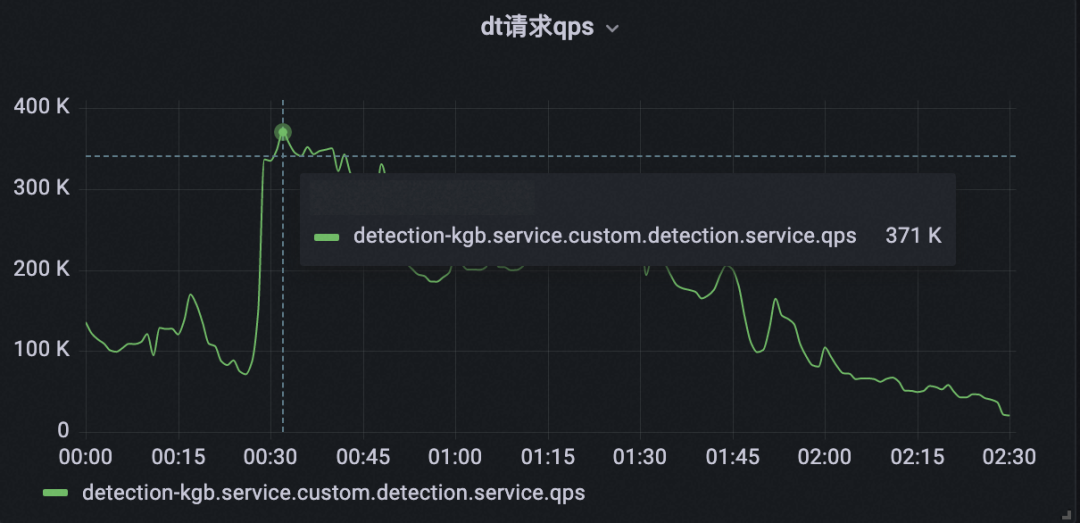
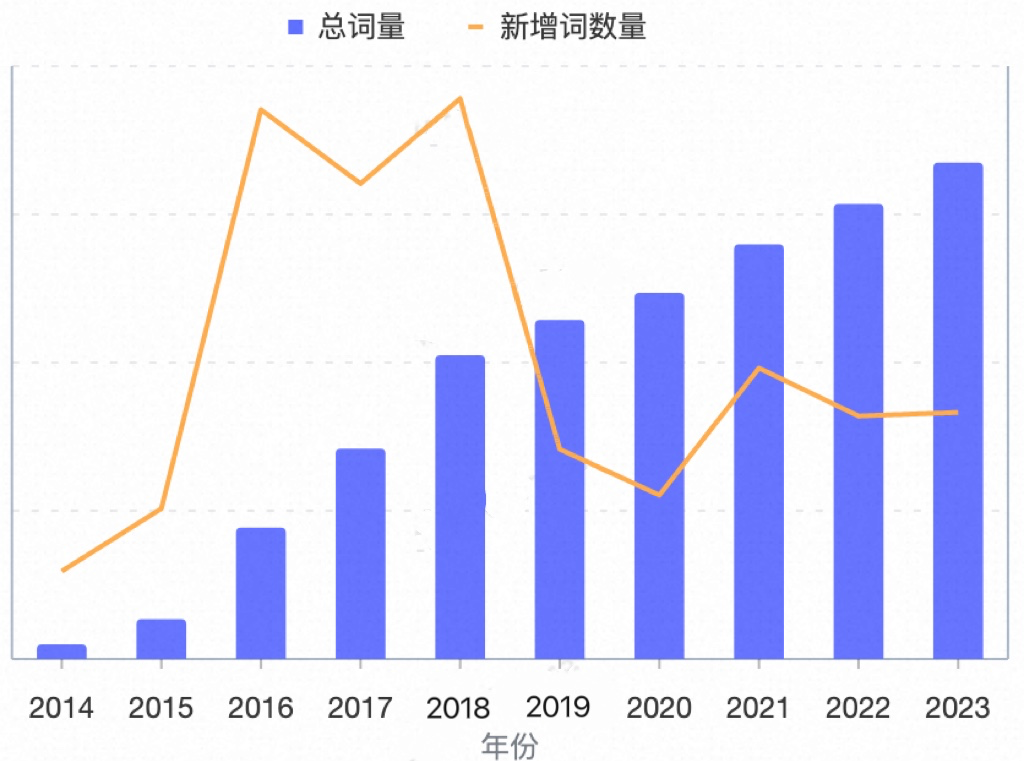
由于词匹配服务承载的QPS较高(峰值40W QPS),且加载的词表逐渐增大(超过100万词),我们对其做了多次优化,包括解决输入文本归一化瓶颈问题,升级底层匹配算法等。还存在以下几类问题。
| 峰值QPS | 敏感词增长趋势 |
|---|---|
 |
|
能力问题:文本预处理能力较弱,只是简单列举,没有引入文本还原,字音字形相近字匹配能力;
效率问题:词数量超过多大,人工运维效率低。词表大加载出现FullGC导致时效问题;
质量问题:词管理混乱,出现大量重复配置的词内容,在离线代码存在不一致问题,导致计算存在差异;词表过大,系统加载时出现FullGC,DB经常出现慢SQL影响服务质量;
成本问题:历史原因运营管控词和算法产出词,由于匹配逻辑存在差异实现两套系统,导致开发、运维成本增加。
之前优化思路是面向解决现有问题出发,没有从更长远的角度考虑未来可能出现的问题,如词超过1000万单机无法承载;词匹配除了功能之外的服务及运维特性等。今年我们从现有问题出发的同时,跳出线性优化的思路对词匹配服务进行整体重构。
3.3.2 词匹配算法对比
我们调研了主流的词匹配相关算法,从多个维度对比算法性能,如下:
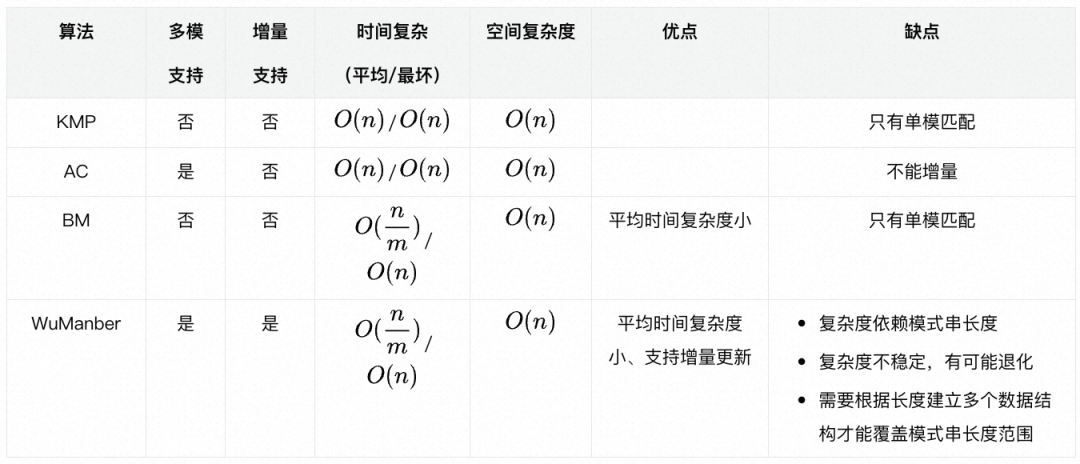
由于KMP和BM只支持单模匹配,我们选取AC和WuManber算法进行实验对比,相关指标如下图所示:

Wumanber内存占用更小,且支持词表增量更新,我们采用Wumanber算法作为默认算法。
3.3.3 词匹配与向量检索方案融合
对比发现检索和词匹配在功能上有很多相似之处,例如都依赖一份检索文件,都需要Build索引、分发加载索引、通过匹配算法获取结果。主要的差异在于索引的内容及匹配算法。因此我们希望能够复用检索引擎索引管理、分发、分布式分行分列执行的能力。
3.3.4 优化效果
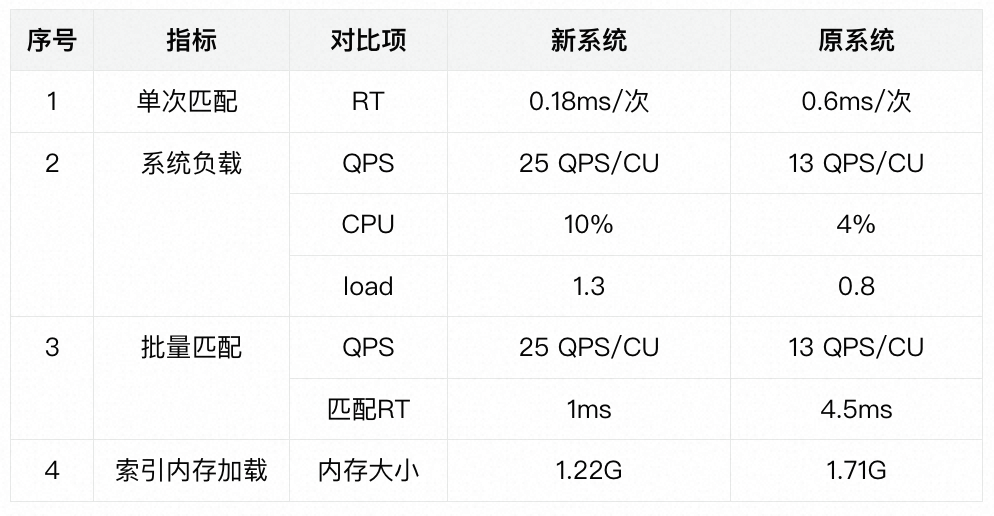
系统升级后,我们从匹配RT、QPS、系统负载、内存占用等多个维度进行评估,可以看到新系统在多个指标上都有成倍提升,详见:
3.4 云原生的DevOps管控
随着底层基础服务能力建设逐渐完善,我们遇到了新的问题。目前,有上百个模型服务、检索、词服务等都需要对应开发、测试和运维。尤其大促期间需要扩容,而GPU资源紧俏,缩扩容时可能会面临资源会被抢占或没有资源。即使有资源支持,手动对100多个服务进行资源调节也是非常繁琐的事情,更别提调节资源后还需要手动修改对应服务的限流值。
因此我们考虑建设Ops相关能力,解决我们服务及运维遇到的问题。我们通过与阿里妈妈DevOps团队合作共建,将服务托管并且带来以下增益:
同时为模型、检索、词服务提供统一的运维管控方案;
面向研发插件的发布链路;
区别于传统的面向应用的整体发布方案,改一行代码也需要重新构建和发布镜像。我们提供了类似插件的版本管理和发布的能力。从而,可以实现:面向业务/算法代码做发布;发布更高效;高效的共享资源池的管理;
规划建设逻辑资源池来缓存释放走的资源,方便资源在逻辑上共享的几组服务之间腾挪。以避免大池子资源紧张时,释放的资源无法快速申请。
四、业务支持
基于基础服务能力,我们支撑了多个新业务场景的落地,及大幅提升老业务场景的性能及效果。下面分别从在线和离线两个维度介绍典型支持的业务场景及相关效果。
4.1 在线业务支持
4.1.1 AI创新业务支持
今年在线最大的变化就是新增了AI创新业务风控场景,AI创新业务风控与现有业务的差异点在于与用户是强交互特性。其它业务提交之后承诺在小时或者天级别返回最终结果(可能需要人审),然而AI无论是生文、还是生图,都需要在秒级返回。并且AI生成的内容与我们传统的内容也存在差异。
目前我们支持了万相实验室在内的多个全新AI业务及应用,底层依托于全新的基础服务建设,无论是上线、迭代速度,还是服务性能及稳定性都有非常大的提升,实现文本审核RT在100ms以内,图像RT在1s以内。
4.1.2 双十一大促表现
风控大促峰值流量与大部分业务是错峰的,每次活动结束后,带活动相关标识的内容都需要集中变更,这时候风控承载的流量是之前的几倍。
往年大促基础服务压力都很大,今年整体服务升级后,大促峰值期间服务整体水位稳定,基本没有明显的瓶颈。
4.2 离线业务支持
离线最核心的场景包括全量风险的清理及算法、运营同学基于历史数据进行效果回测。基础服务能力升级之后,已经支持部分场景的落地。针对离线核心解决在、离线一致性问题,确保每个服务在线、离线运行结果一样。这里以全量清理为例,下图是具体流程(黄色部分是基础能力在流程中应用的位置):
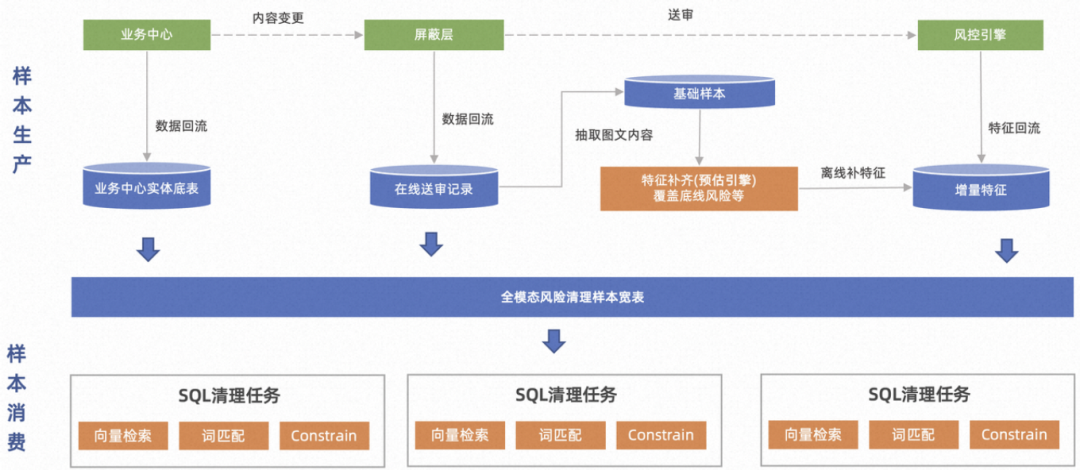
基础能力上线后,我们解决了在离线一致性问题,提升了系统性能及资源使用率,更好的为整体业务保驾护航。
五、未来展望
阿里妈妈内容风控基础服务能力已进行全新升级,并在风控多个业务场景落地,取得了显著的业务效果。但随着未来技术的不断演进,我们还需要持续迭代,现阶段我们已从功能或者性能层面对各个基础服务能力进行完善,未来面向在线、离线计算一致性、基础能力的服务及运维特性等还需要进一步建设,具体包括:
5.1 能力方面
基础服务性能优化:持续优化模型、检索、词匹配、通用预处理等基础服务性能,后续大模型在风控场景上的应用会越来越多,对算力的要求也越来越高,需要持续进行性能优化。词匹配适配检索链路,分行分列能力还在持续建设中。检索支持十亿级别的实时更新和查询能力还在持续优化中。
在、近、离线统一:基于基础服务能力,构建在、近、离线统一的服务能力。每个基础能力做的足够简单可复用之后,可以基于这些能力之上,经过简单的封装调用就可以在不同资源、环境下进行快速拉起运行,解决在、近、离线业务问题。
弹性伸缩:解决现有资源池GPU不足导致缩扩容困难,完善基础服务可观测性、可运维性,实现整体资源池合理隔离、按需分配,手动或自动进行资源伸缩。
5.2 效率方面
管控效率:管理所有基础服务,支持所有基础服务任意版本在线回滚加离线回放,提供完善的模型上线压测流程
运行时效:通过优化资源及系统,达到对业务透出时效减低的诉求,更好的服务低延迟应用场景
5.3 质量方面
服务质量:对基础服务上线提出标准SOP,必须经过完整的压测、评测、灰度流程才能发布到线上。发布后持续对服务进行检测,如果有问题支持快速恢复、回滚等应急措施。
代码质量:随着基础服务个数越来越多,对在、近、离线一致性要求也越来越高,需要将在、近、离线复用的代码逻辑进行统一管理,更新后在、近、离线能够确保都更新到最新代码。同时也支持指定任意版本进行发布和回放。
5.4 成本方面
计算成本:未来模型会越来越重,优化模型本身性能及资源弹性调度和隔离,是减低成本的重要手段。后续也会在PPU上做更多尝试,相对而言PPU的成本更低。
运维成本:目前有上百个模型,需要更好保障模型服务,管理模型完整生命周期,减低人工运维成本。需要结合前面提到的能力、效率、质量等综合落地。
六、写在最后
新一轮的技术浪潮兴起伴随着新的机遇与挑战,阿里妈妈内容风控团队无论在算法还是工程方向,都在积极探索前沿技术,以构建更全面的AI驱动的风控解决方案。期待与大家分享交流,同时也欢迎感兴趣的朋友加入我们~
✉️ 简历投递邮箱:alimama_tech@service.alibaba.com
七、附录
丨广告深度学习计算:多媒体AI推理服务加速利器high_service
END

关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”哦ღ~
↓欢迎留言参与讨论↓


















 612
612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









