







 本文介绍了阿里妈妈团队在电商领域利用人工智能和生成式内容创造技术,开发出的商品视频动效生成工具AtomoVideo,以及NoiseRectification技术,通过自动化将图片转为高质量视频,提升广告创意效率。
本文介绍了阿里妈妈团队在电商领域利用人工智能和生成式内容创造技术,开发出的商品视频动效生成工具AtomoVideo,以及NoiseRectification技术,通过自动化将图片转为高质量视频,提升广告创意效率。
✍🏻 本文作者:凌潼、依竹、桅桔、逾溪
1. 概述
当今电商领域,内容营销的形式正日趋多样化,视频内容以其生动鲜明的视觉体验和迅捷高效的信息传播能力,为商家创造了新的机遇。消费者对视频内容的偏好驱动了视频创意供给的持续增长,视觉内容作为连接消费者和商品的桥梁,在广告系统中正变得日益重要。
然而,与传统的图文内容相比,视频内容的制作难度和成本都要高得多。制作一个高质量的视频需要专业的技能、设备以及时间,这使得成品的质量层次不齐,且难以批量化生产。随着人工智能和生成式内容创造(AIGC)技术的进步,使得通过智能化手段批量制作优质视频创意成为可能,并且能够为客户带来显著价值。
近日,OpenAI Sora 的发布让人们看到了视频智能创作的曙光,如今各大团队也纷纷开始了“国产版 Sora”的探索之路,在 Sora 出现之前,阿里妈妈智能创作与AI应用团队在视频 AIGC 领域已有近一年的研究和探索,与业务相结合,我们孵化出了🔗 尺寸魔方、商品视频动效生成等基于扩散模型的视频生成和编辑工具。本文将聚焦于商品视频动效生成,介绍我们在视频 AIGC 应用于视频创意上的探索与实践。
借助自研的AtomoVideo 视频生成技术(中文:阿瞳木视频,项目地址:https://atomo-video.github.io/),我们探索出了一种自动化地将电商平台上现有的图片素材转换为高质量的视频动效的方法,并在万相实验室、广告投放平台等场景进行了落地和上线,服务于广大阿里妈妈广告客户。
 |
 |
|---|---|
|
 |

2. 核心技术
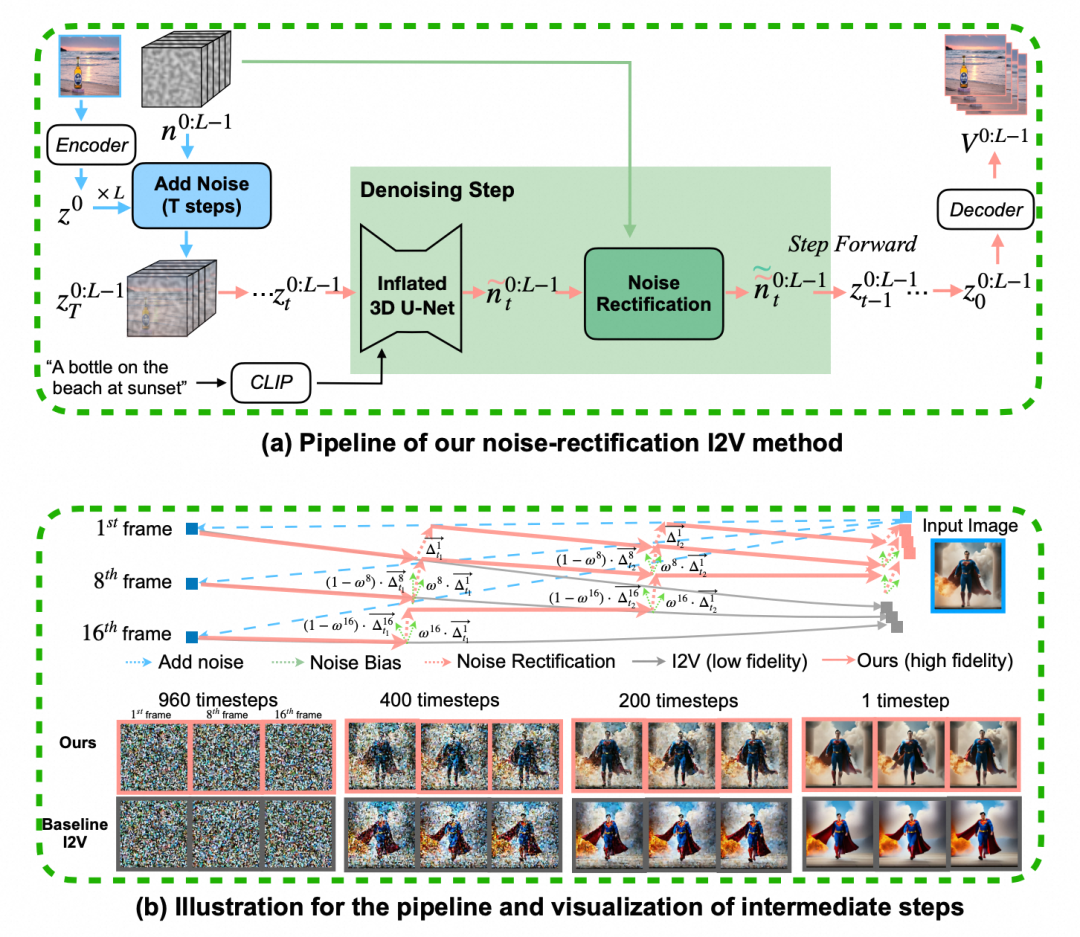
整个商品视频动效的生成过程面临诸多挑战,尤其是在电商场景下,商品主体的细节是不允许被改变的,也是商家非常在意的基本准则。因此,如何在保持商品外观准确性的同时进行更加合理的动效视频生成,是非常值得探索的问题。我们在现有T2V模型的基础上,提出使用 Noise Rectification(无需训练的噪声矫正器)来实现图像到视频的生成,为了进一步提升视频连贯性和保真度,进而提出 AtomoVideo(阿瞳木视频生成技术) 将基础模型进行升级,赋能电商视频动效生成。
2.1 Noise Rectification: 无需训练的噪声矫正器
文本到图像生成(T2I)在过去一年取得了飞速的发展,诸多设计行业从业者、科技爱好者利用 Stable Diffusion WebUI、ComfyUI 等开源工具已经可以生成摄影级图像和实现商业级落地应用。相比之下,受限于训练机器资源和数据集收集困难等挑战,视频生成远没有图像生成领域发展迅速,近半年,随着 Pika、Gen-2 等视频编辑工具的出现,社区中也涌现了许多文本到视频生成(T2V)的工作,为了将此类 T2V 的工作迁移至我们的商品动效生成中,我们提出了一种无需训练的噪声矫正器(Noise Rectification),可以自然地实现 T2V 到 I2V 的转变。
具体来说,我们对给定图片添加一定步数的噪声,以此来模拟训练过程中的加噪过程,这样我们便获得了含有输入图像信息的噪声先验,在此基础上进行降噪即可保留一定输入图片的风格等信息。然而,这种“垫图”式 T2V 生成方式在电商领域对给定图片做动效生成时,会丢失大量原图像中的细节信息,严重破坏原有图片的美观度。为此,我们专门设计了一个与“垫图”生成可以完美配合的噪声矫正器(Noise Rectification),噪声矫正器流程图如下所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









