






导读:去年,我们提出了AIGB的初步设想与方案(延展阅读:Bidding模型训练新范式:阿里妈妈生成式出价模型(AIGB)详解)。经过一年的深入探索,我们完成了AIGB的完整方案,并在实际在线广告平台大规模预算AB测试中取得了显著效果。值得一提的是,AIGB的研究成果已被KDD 2024大会接收。在本文中,我们将基于KDD公开发表的论文,详细分享这一全新的自动出价优化范式。
论文:AIGB: Generative Auto-bidding via Diffusion Modeling
作者:Jiayan Guo, Yusen Huo, Zhilin Zhang, Tianyu Wang, Chuan Yu, Jian Xu, Yan Zhang, Bo Zheng
链接: https://arxiv.org/abs/2405.16141
▐ 摘要:
在2023年,在线广告市场的规模达到了6268亿美元,而自动出价已成为推动这一市场持续增长的关键因素。自动出价需要在顺序到来的海量展示机会中依次做出出价决策,这是一个典型的长序列决策问题。近年来,强化学习(RL)在自动出价中得到了广泛应用。然而,目前大多数基于RL的自动出价方法都采用马尔可夫决策过程(MDP)进行建模,但在面对较长序列决策时,这些方法受到了误差累积等因素的限制,效果表现受限。为了解决这些问题,本文提出了一种新范式AIGB——基于生成式模型的自动出价。在具体实现上,该方法基于条件生成模型,将出价决策轨迹与优化目标直接建模在一起,从而有效避免在长序列决策时跨时间步的误差传播。在应用中,只需设定要达成的优化目标及特定约束,即可生成能够最大化给定目标的出价轨迹,依托此轨迹可以得到具体的出价决策动作。我们将该方法在阿里巴巴广告平台进行大规模部署,并通过预算AB实验进行了长达一个月的效果观察,充分验证了该方法的有效性。在总交易额(GMV)和投资回报率(ROI)上分别实现了4.2%和5.6%的增长,同时显著提升了广告主的投放体验。并且我们对该范式进行了深入细致的分析,在出价轨迹规划及出价动作的有效性上都展现出了不错的潜力,对该范式的深入研究可以带来持续的效果提升。
一、背景
1.1 自动出价建模
广告主的目标是在满足各个约束的条件下在整个投放周期内部获取最多的流量价值。考虑到广告目标、预算和𝑀 个KPI约束,自动出价问题可以被定义为一个带约束的优化问题:
其中,表示是否竞得流量,和 分别表示流量的价值(流量产生购买或GMV的可能性)和成本。是是第个约束的上界。表示效果指标,例如CPC、ROI等,第个约束所关联的流量消耗。如果只有预算进行约束,我们称为Max Return Bidding。如果同时考虑预算约束和CPC约束,我们称为Target-CPC bidding。
如果假设已经知道整个投放周期内流量集合的全部信息,包括能够触达的每条流量以及其流量价值和成本,那么可以通过解决线性规划问题来获得最优 。为了求解这一优化问题,我们一般通过对偶变换,构造一个最优出价公式,将原问题转化为求解最优参数的问题,从而大大降低在线情况下求解此问题的难度。
最优的出价公式为:
其中,是常数项,是参数,其范围为:。证明过程详见论文[1]。最优出价公式共包含 m+1 个核心参数, 𝑘 ∈ [0, ..., 𝑀],公式中其余项为在线流量竞价时可获得的流量信息。由于最优出价公式存在,对于具有M+1个约束、且希望最大化赢得流量的总价值的问题,最优解可以通过找到 M+1 个最优参数并根据公式进行出价,而不是分别为每个流量寻找最优出价。理想情况下,通过求解最优参数 ,即能直接获得每个广告计划的最优出价。
1.2 自动出价中的决策问题
然而,在实际投放过程中,我们无法提前获知整个投放周期的流量分布,需要在流量集合未知的情况下进行实时竞价。因此,由于无法直接计算出最优参数,常规的线性规划解决方法并不完全适用。在实践中我们往往需要根据历史信息对进行预估,并得到预估值。由于环境随机性大,进行实时动态调整以适应环境的变化。基于这一视角,我们可以将自动出价被看作一个序列决策问题。为了对这个问题进行建模,我们引入状态变量 描述实时投放状态,自动出价模型基于输出出价动作,环境将动态变迁至下一状态 ,并获取到相应的奖励 。接下来我们进行详细的定义:
状态 :描述在时间段的实时广告投放状态,包含一下方面的信息:1) 剩余投放时间;2) 剩余预算;3) 预算消耗速率;4) 实时点击成本(Cost Per Click);5) 平均点击成本(CPC)。
动作:描述在时间段对出价参数的调整,其维度与竞价参数的数量相符,并用向量形式 表达。
奖励:在时间段内获取的收益。
轨迹:表示整个投放周期内一系列状态、动作和奖励的序列。
1.3 生成式模型
生成式模型近年来得到了迅速的发展,在图像生成、文本生成、计算机视觉等领域取得了重大突破,并催生出了近期大热的ChatGPT等。生成式模型主要从分布的角度去理解数据,通过拟合训练数据集中的样本分布来进行特征提取,最终生成符合数据集分布的新样本。目前常用的生成式模型包括Transformer[3]、Diffusion Model[4]等。Transformer主要基于自注意力机制,能够对样本中跨时序和分层信息进行提取和关联,擅长处理长序列和高维特征数据,如图像、文本和对话等。而Diffusion Model则将数据生成看作一个分阶段去噪的过程,将生成任务分解为多个步骤,逐步加入越来越多的信息,从而生成目标分布中的样本。这一过程与人类进行绘画过程较为相似,由此可见,Diffusion Model擅长处理图像生成等任务。
依靠生成式模型强大的信息生成能力,我们也可以引入生成式模型将序列决策问题建模为一个序列动作生成问题。模型通过拟合历史轨迹数据中的行为模式,达到策略输出的目标。Decision Transformer(DT)[5] 和 Decision Diffuser(DD)[6] 分别将Transformer以及Diffusion Model应用于序列决策,在通用数据集中,相比主流的RL方法[7,8]取得了较好的效果提升。这一结果为我们的Bidding建模提供了一个很好的思路。
二、AIGB(AI Generated Bidding)建模方案
AIGB是一种利用生成式模型构造的出价优化方案。与以往解决序列决策问题的RL视角不同,AIGB将自动竞价视为一个轨迹生成问题,直接捕捉优化目标和整个投放轨迹之间的相关性,从而克服RL在处理线上环境高随机性、长序列稀疏回报和有限数据覆盖时的性能瓶颈。在此基础上,我们进一步发挥生成模型的优势,尝试通过多任务的方式解决出价问题。在训练过程中,对约束进行条件化,使得推断时的行为可以同时满足多个约束组合。我们的研究结果表明,使用条件生成模型来解决出价问题中的序列决策问题是一个好的选择。
从生成式模型的角度来看,我们可以将出价、优化目标和约束等具备相关性的指标视为一个联合概率分布,从而将出价问题转化为条件分布生成问题。这意味着我们可以以优化目标和约束项为条件,生成相应出价策略的条件分布。图1直观地展示了生成式出价(AIGB)模型的流程:在训练阶段,模型将历史投放轨迹数据作为训练样本,以最大似然估计的方式拟合轨迹数据中的分布特征。这使得模型能够自动学习出价策略、状态间转移概率、优化目标和约束项之间的相关性。在线上推断阶段,生成式模型可以基于约束和优化目标,以符合分布规律的方式输出出价策略。 总的来说,生成式模型的优势在于:
训练阶段,条件生成式模型通过最大似然估计进行训练,通过监督学习的方式优化策略,可解释性更强。
推断阶段,条件生成式模型可以根据不同的出价类型生成不同的出价轨迹,以实现不同约束项的满足。具备多任务能力。
2.1 模型结构
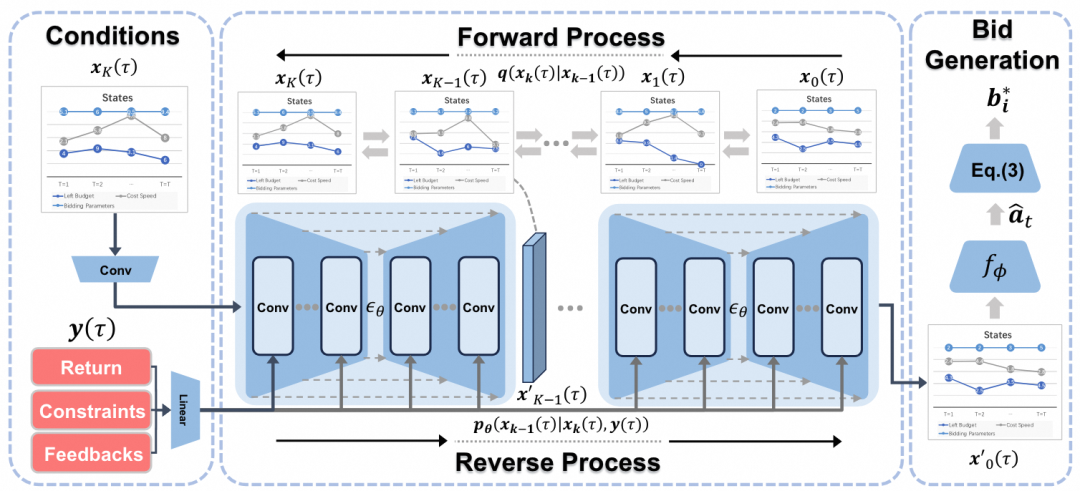
如图2,给定当前轨迹信息 和策略生成条件,AIGB模型可以逐个生成未来的出价策略:
其中出价策略 是由未来的最优状态和与之对应的最优出价组成的序列。生成条件包括了优化目标(购买量最大化、点击量最大化)以及约束项(PPC、ROI、投放平滑性)等。被用来估计条件概率分布。模型基于当前的投放状态信息以及策略生成条件输出未来的投放策略,相比于以往的RL策略仅仅黑盒输出单步action,AIGB策略可以被理解为在规划的基础上进行决策,更擅长处理长序列问题。这一优点有利于我们在实践中进一步减小出价间隔,提升策略的快速反馈能力。与此同时,基于规划的出价策略也具备更好的可解释性,能够帮助我们更好地进行离线策略评估,方便专家经验与模型深度融合。
2.2 生成式建模
我们提出一种基于AIGB范式的出价算法——DiffBid。在训练阶段,DiffBid模型通过最大似然估计历史数据集D中轨迹 和策略生成条件 所对应的轨迹信息进行训练,从而最大限度拟合历史轨迹的分布信息:
拟合历史分布的过程可以通过引入 Diffusion Model 或 Transformer 等生成式模型来完成。以我们真实使用的扩散模型为例,我们将序列决策问题看作一个条件扩散过程,包括正向过程 和反向过程 。表示正向过程的迭代步,在正向过程,从 转变为 的过程,每一次 到 的转换均通过加入高斯扰动实现;反向过程则表示高斯噪声 转化为历史投放轨迹分布 。每一次 到 的转换均通过加入含有一定信息的高斯扰动实现。除此之外,在反向过程中,我们还希望能够表达与的相关性,因此可以引入DD模型中使用的Classifier-free方法,利用
提取数据集中与 相关度最高的部分。其中 为噪声模型,通过神经网络生成每一个时间步所增加的噪声。步所对应的高斯扰动可以表示为:
其中表示不同的目标或者约束,用来调节 的权重。Classifier-free方法可以较为优雅地处理多种优化目标和约束条件,避免以往RL训练过程中由于约束信号稀疏而效果下降的问题。在此基础上,我们可以计算每一个step的重构误差,也就是:
然后通过最小化误差的方式进行训练。 DiffBid模型的策略生成阶段通过给定生成条件生成符合要求的出价轨迹。具体过程如下:

2.3 策略生成条件
对于只有预算约束的单约束bidding问题,我们利用策略生成条件来表示优化目标。我们将每一条投放轨迹在整个投放周期内的总奖励定义为Return,为了方便模型进行训练,我们沿用DD中的处理方式,也就是:
其中和分别表示数据集中Return的最小和最大值。其中表示数据集中最好的轨迹,能够更好地服务于广告主的效果提升。表示数据集中最差的轨迹。接下来我们把作为condition合并进中并进行训练。
对于具有多约束的bidding问题,需要要求每一个约束变量都不能超过设定的阈值。我们在此基础上将更多约束相关信息合并进中,并维护一个二进制变量 来指示最终CPC是否超过给定的约束 :
其中,由上文计算得到。当时代表出价不会导致超限发生。我们将合并进中进行训练。对于多约束变量,除了业内普遍的CPC、ROI等约束以外,利用扩散模型的强大能力,我们得以加入更多个性化的约束,我们称为人类反馈约束。例如,广告主可能会希望预算消耗尽可能均匀,进一步减小爆量发生的概率。我们可以通过定义约束相来实现。其中表示广告计划在时刻的总消耗。广告主可能希望将特定时间段消耗更多的预算以应对促销活动,我们通过来表示。
三、实验结果
为了对AIGB的效果进行验证,我们通过仿真平台和真实线上做了大规模的实验。在离线实验中,我们进行了多维度的实验,包括在Max Return Bidding、Target-CPC Bidding、广告主反馈等。在此基础上,我们将模型部署到线上场景进行了线上的Max-Return场景进行了实验。
3.1 仿真实验结果
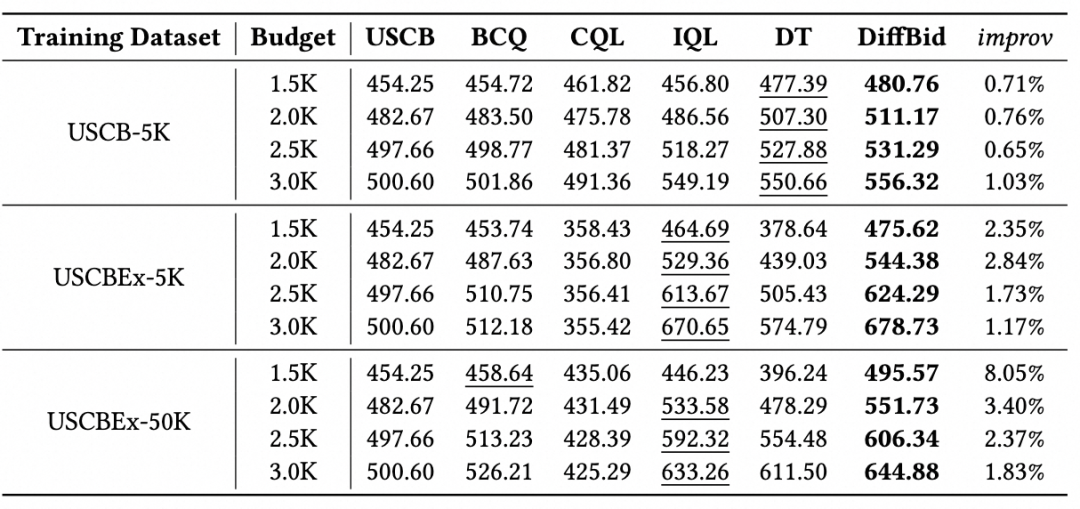
表1展示了DiffBid与基准模型在Max Return Bidding的效果对比。在这个表中,DiffBid作为评估的所有方法中表现最好的方法脱颖而出。在所有预算场景和训练数据集中,DIffBid模型始终获得最高的累计奖励。这一显著的表现突显了AIGB在优化出价策略方面的能力,展示了将出价过程进行生成式建模的优势——能够做出更具有全局性的出价策略。另外一个关于AIGB性能的方面是其对探索数据具有更好的融合能力。AIGB比强化学习基线方法能够更有效从探索数据中提取出更好的策略。
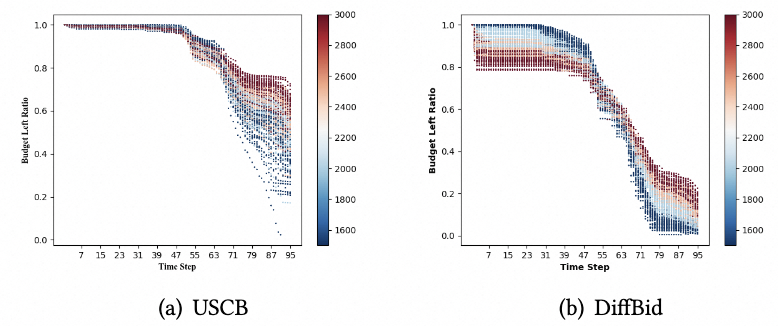
我们进一步研究AIGB策略的特点,我们比较了基准方法USCB和DIffBid的分时消耗情况。在图3中,我们绘制了一天中剩余预算比例随时间步的变化。从图中我们可以观察到,在USCB下,大部分广告商的消费未能耗尽他们的预算。这归因于USCB面临的线下虚拟环境和真实线上环境之间的不一致性。相反,在AIGB下,预算完成情况有所改善,大部分广告商花费了超过80%的预算。一个可能的原因是DiffBid发现高预算完成比例的轨迹同样会有高累积奖励,因此倾向于生成预算完成比例高的轨迹。此外,小预算的广告商倾向于在下午消费。这是因为下午的流量平均性价比更高。
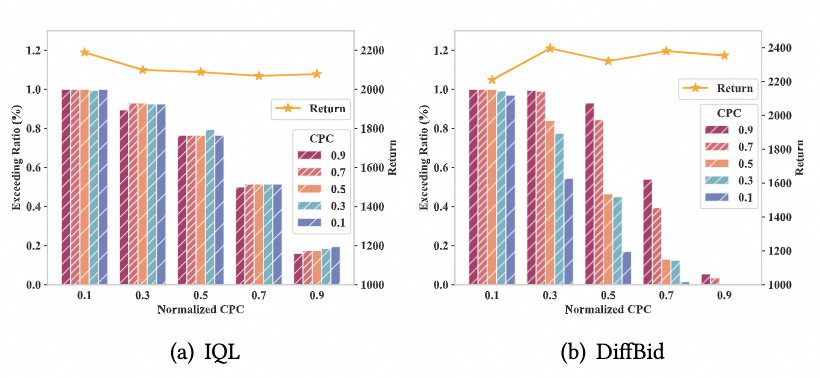
我们还研究了AIGB应对多约束的能力,并将其性能与离线强化学习(IQL)进行了比较。具体来说,我们检查DiffBid和IQL控制整体CPC超额比例的能力,同时最大化总回报。在训练期间,我们设置不同的CPC阈值。然后在测试时,我们让AIGB生成满足期望CPC下的轨迹。在图4中,我们展示了在不同CPC约束和训练设置下的超限比例和总回报。从图中发现,AIGB能够在保持完整回报的同时,控制不同水平的超限比例,显著优于IQL。因此,AIGB在有效解决MCB问题上占据了明显优势。
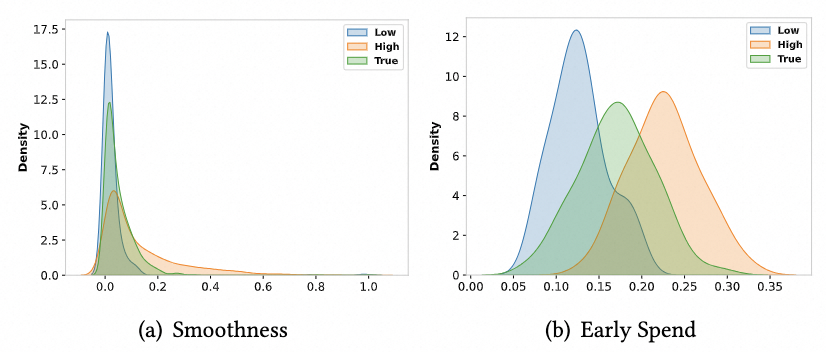
我们还研究了在不同广告商反馈下的性能。在训练期间,我们将阈值将轨迹分为高低两个水平,并学习不同水平下的条件分布。在生成期间,我们调整条件并生成相应的样本,并总结指标。图5显示了低水平、高水平和原始轨迹的指标的统计分布结果。我们发现,部署AIGB获得的轨迹能够很好地受到条件的控制。
3.2 线上实验结果:
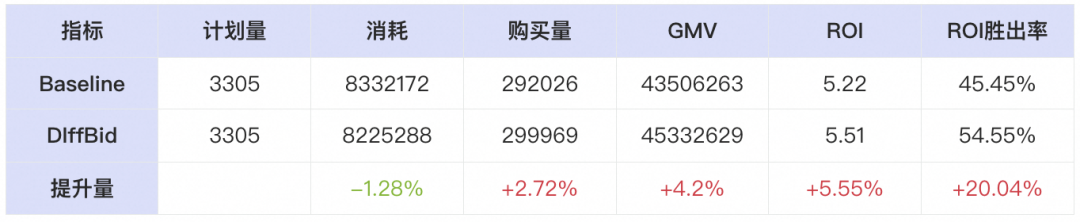
为了进一步证实AIGB的有效性,我们已经在阿里巴巴广告平台上与表现最优的自动出价方法之一IQL方法进行了比较。通过较长周期的在线A/B测试,实验结果表明(如表2),DiffBid可以将购买次数(Buycnt)提高2.72%,总商品交易额(GMV)提高4.2%,投资回报率(ROI)提高5.55%,ROI胜出率提升20.04%,展示了其在优化整体性能方面的有效性。在效率方面,经过GPU加速,AIGB可以很好地保证计算延时不增加太多。
四、总结及未来展望
AIGB方案有诸多优势,包括解决困扰RL Bidding在离线不一致问题,更好地训练多约束出价模型,更好的可解释性以及更为顺畅的与专家经验的结合能力等,这些优势可以帮助我们进一步提升的模型迭代效率和效果上限。基于AIGB的出价方案目前已经在阿里妈妈线上广告场景落地。可以看出,生成式模型驱动的AIGB已经在以完全不同的方式重构自动出价的技术体系。但是,这仅仅是一个开始。阿里妈妈沉淀了亿级广告投放轨迹数据,是业界为数不多具备超大规模决策类数据资源储备的平台。这些海量数据资源可以成为营销决策大模型训练的有力保证,从而推动AIGA技术的发展。与此同时,用户和互联网产品的交互方式也将发生深刻的变化。重塑广告营销模式的机会之门已经在变化之中逐步显现,我们需要做的就是通过持续不断的探索和尝试来迎接变化。期待后续有机会与大家分享和交流我们的进展与实践。
🌟NeurIPS Competition 2024 重磅开启—— 阿里妈妈邀你共赴大规模博弈下自动出价的挑战!

🔍 首次公开:5亿条广告博弈数据,独家出价模型训练框架——为你的研究和实践提供强大支持;
🔧 领域聚焦:决策智能、计算广告、强化学习、博弈论、生成式模型——不容错过的实践与研究机遇;
🏆 荣誉与奖金:在国际舞台上展现才华,赢取6000美元奖金,更有阿里巴巴实习、校招直通及访问学者机会。
💡 立即报名参赛>> ,让世界见证你的创新与智慧!报名截至2024年8月8日

👉🏻 联系我们
▐ 参考文献
[1] He Y, Chen X, Wu D, et al. A unified solution to constrained bidding in online display advertising[C]//Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2021: 2993-3001.
[2] Mou Z, Huo Y, Bai R, et al. Sustainable Online Reinforcement Learning for Auto-bidding[J]. arXiv preprint arXiv:2210.07006, 2022.
[3] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[4] Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models[J]. Advances in Neural Information Processing Systems, 2020, 33: 6840-6851.
[5] Chen L, Lu K, Rajeswaran A, et al. Decision transformer: Reinforcement learning via sequence modeling[J]. Advances in neural information processing systems, 2021, 34: 15084-15097.
[6] Ajay A, Du Y, Gupta A, et al. Is Conditional Generative Modeling all you need for Decision-Making?[J]. arXiv preprint arXiv:2211.15657, 2022.
[7] Kumar A, Zhou A, Tucker G, et al. Conservative q-learning for offline reinforcement learning[J]. Advances in Neural Information Processing Systems, 2020, 33: 1179-1191.
[8] Kostrikov I, Nair A, Levine S. Offline reinforcement learning with implicit q-learning[J]. arXiv preprint arXiv:2110.06169, 2021.
[9] Li H, Huo Y, Dou S, et al. Trajectory-wise Iterative Reinforcement Learning Framework for Auto-bidding[J]. in Proceedings of the World Wide Web Conference (WWW 2024).
[10] Kostrikov I, Nair A, Levine S. Offline reinforcement learning with implicit q-learning[J]. arXiv preprint arXiv:2110.06169, 2021. [11] Fujimoto S, Meger D, Precup D. Off-policy deep reinforcement learning without exploration[C]//International conference on machine learning. PMLR, 2019: 2052-2062.
END

关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”哦ღ~


















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









