







ReFT: Reasoning with Reinforced Fine-Tuning
这篇论文主要讲如何使用SFT的数据做 更好,更聪明的微调,在同样SFT CoT数据情况下,我们看到用ReFT 的效果要远远好于 SFT,至少是在数学解题的这个领域上。
论文链接:https://arxiv.org/pdf/2401.08967.pdf

Motivation
SFT 在CoT的数据上进行微调:
- x \boldsymbol{x} x: 表示问题输入
- e \boldsymbol{e} e: 表示思维链Chain-of-Thought (CoT)
- y \boldsymbol{y} y: 表示输出, 在数学里面就是解题的答案
SFT在 CoT的数据中微调,最终得到的模型,大概率是overfit 我们的训练数据的,也就是说会更偏向于我们的CoT结果。
但是往往在推理过程中,自然语言不仅仅只有一种CoT,我们很容易的就能写出不一样的CoT。
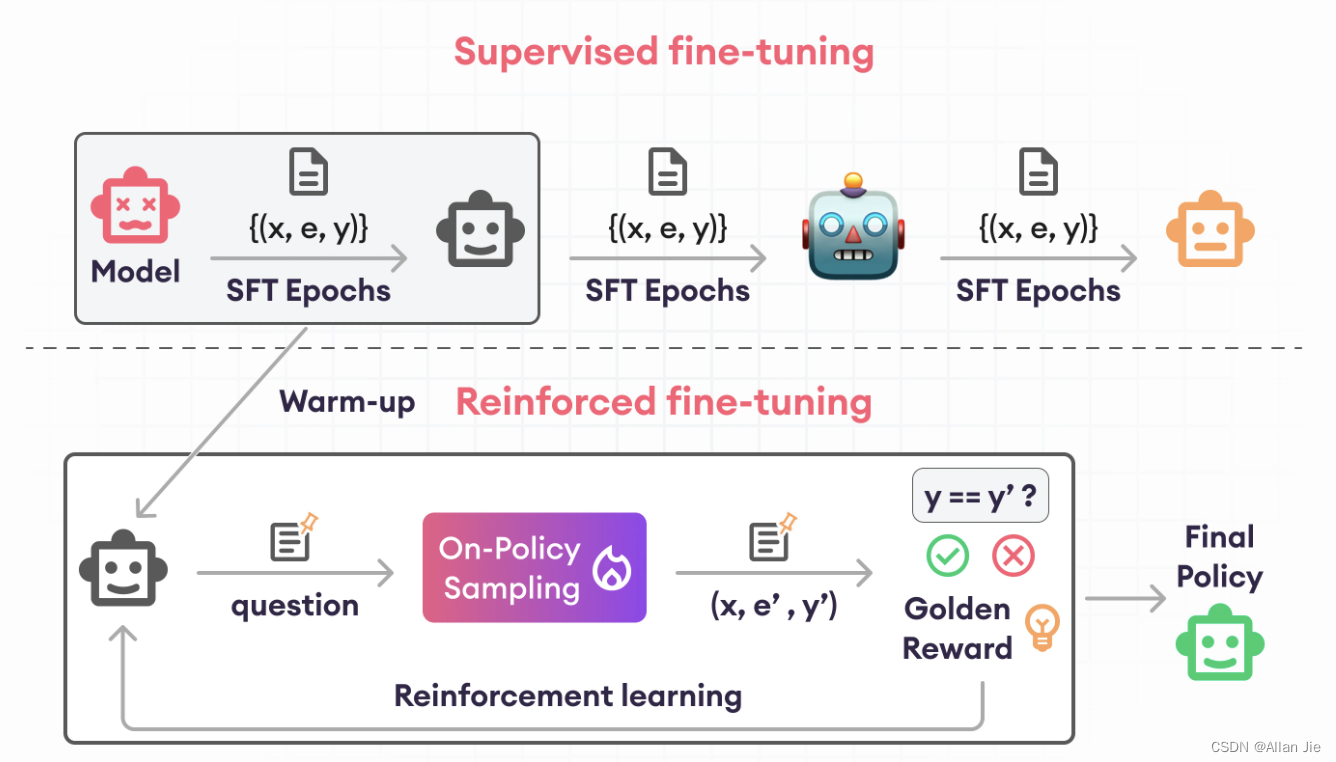
图片来源于 https://www.superannotate.com/blog/reinforced-fine-tuning#results
ReFT
在ReFT中,解决这个问题的办法,也是非常显而易见,主要通过采样。如上图所示,这个方法主要有两个阶段。
- 第一个阶段 Warm-up:这个时候主要是让模型熟悉如何生成 数学解题的方案,让模型有一个大概的思路,但不需要太准确。具体到实现的时候,我们只需要让模型在CoT 数据上Fine-Tune 1 ~ 2 epoch 即可
- 第二个阶段 Reinforcement Learning: 这个阶段就是让 policy
π
\pi
π (或者叫模型)自己去采样生成一些答案,在这个阶段我们还是用SFT CoT 本身的训练数据。并没有任何额外的数据。
- Reward: 这个阶段的reward,我们可以直接用数据中的 y \boldsymbol{y} y 来判断结果是否正确。从而得到reward, 我们不需要额外训练reward model,这里的reward 是一个groundtruth reward.
- 整个过程使用PPO的方法进行训练。最后得到更好的policy
- 总的来说:我们是用SFT的数据,希望得到一个比SFT更好的policy。
ReFT的一些优势
- 更好的泛化性能:因为我们在后面的训练,完全不需要用到 CoT e \boldsymbol{e} e的标注数据,完全依赖模型自己去探索 怎么样的CoT 是正确的。
- 相比常规RLHF训练简单: 不需要标注额外数据训练Reward Model, 不需要额外数据提高policy. 当然这里作者也认为更多的数据能提高效果,但这并不是这个文章的目的。
- 可用性: 这个方法没有一些特定的restriction,在其他任务上也是可以用到的,适用于大家SFT数据少的时候,我们做一些效果上的性能提升。
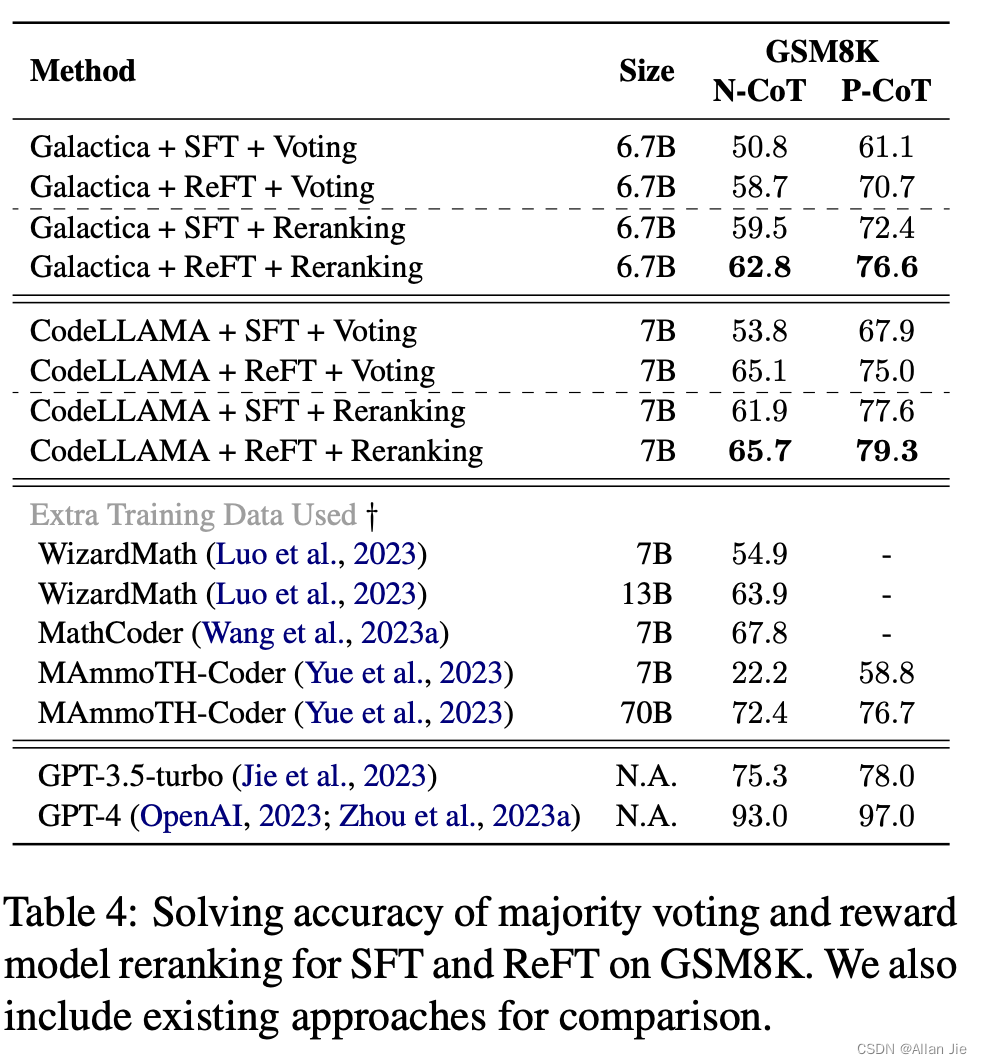
- 更好的效果:最后作者也在GSM8K上做实验,证明更好的policy也能在Majority Voting和进一步Reranking上面有效果的提升,而且也是非常的明显。
实验效果
感觉方法上还是比较直接的,没有太多细节需要讲。这里贴一下主要的结果,作者主要在GSM8K, MathQA 和SVAMP上面进行实验。
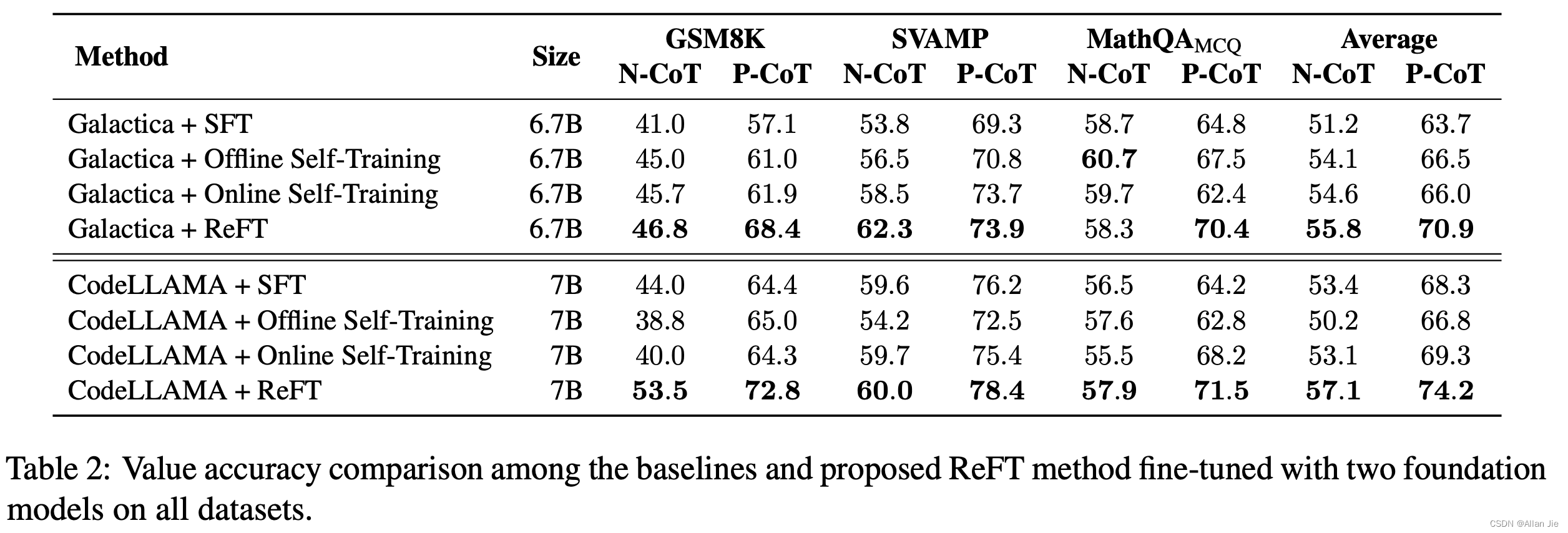
- 我们直接看最后的Average,用CodeLLAMA或者Galactica,ReFT 相比SFT,都有一个非常大幅度的提升,并不是1-2个点左右的提升而已。
- 相比Self-Training, self-training训练过程更加复杂,而且提升并不大。
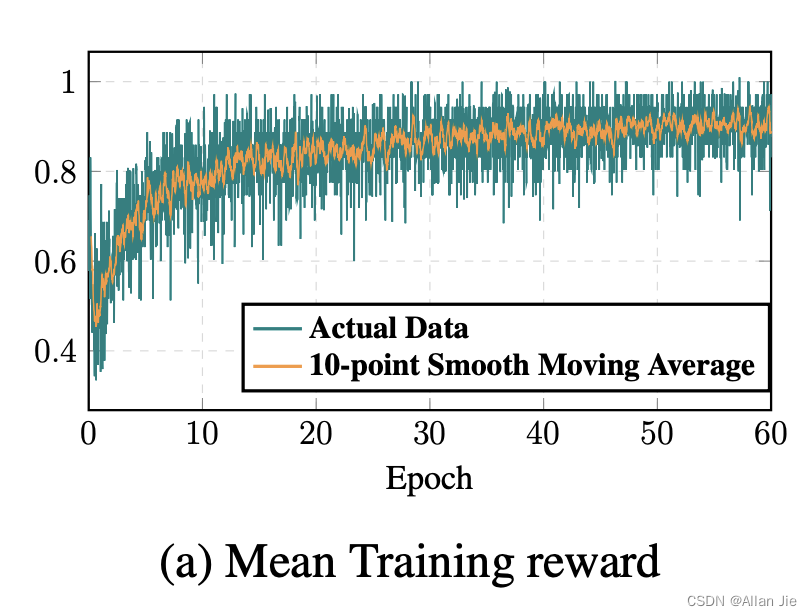
泛化性能
SFT大约在30个epoch的时候training accuracy就已经95左右,overfit了,但是ReFT在30 epoch,training reward 也就大概80+, 还在继续学习。
根本原因主要是 我们没有主动去优化CoT,而是最终的答案。
Majority Voting and Reranking
Insight
- 期待更多的实验 使用ReFT 在其他的下游任务,这样能够更加充分证明
- 作者提到了ReFT的训练时间可能是非常长的,因为需要policy自己去explore整个空间,怎么加快训练也是一个问题。
- 还能提升?目前作者光使用了PPO,但还没有close 和 reranking的gap,这个地方感觉还是有空间提升,使用更好的强化学习算法。
其他一些线上讨论
- https://www.superannotate.com/blog/reinforced-fine-tuning
- https://www.marktechpost.com/2024/01/21/bytedance-ai-research-unveils-reinforced-fine-tuning-reft-method-to-enhance-the-generalizability-of-learning-llms-for-reasoning-with-math-problem-solving-as-an-example/
- https://gsanjeewa1111.medium.com/llm-paper-facts-2-16e3dccf1724
- https://bdtechtalks.com/2024/01/22/llm-reasoning-reft-fine-tuning/
- https://www.linkedin.com/posts/pascalbiese_reft-a-new-way-of-finetuning-llms-activity-7153711087438245889-QPeC
- https://twitter.com/arankomatsuzaki/status/1747817708446417058
- https://www.linkedin.com/posts/petr-kazar_reft-sft-cot-activity-7153733220235161602-gS1Z/
- https://twitter.com/_akhaliq/status/1747820246268887199
- https://www.superannotate.com/blog/reinforced-fine-tuning
- https://www.linkedin.com/posts/zara-dana_reft-reasoning-with-reinforced-fine-tuning-activity-7155315581867511808-ORMm/
- https://gsanjeewa1111.medium.com/llm-paper-facts-2-16e3dccf1724
- https://huggingface.co/papers/2401.08967
- https://twitter.com/dair_ai/status/1749103962152661428


















 787
787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











