










splunk的使用
在安全服务的多种场景下,我们都离不开日志分析这项工作,特别是在应急与溯源的过程中,日志分析成为快速定位问题的重要方式。轻量级的日志分析我们通常使用文本编辑器或者excel等具备简单筛选功能的工具进行查看,但是对于大量级的日志分析,在很多场景下这些工具不再适用,下面我将介绍splunk这款工具在日常应急及溯源工作中使用的一些思路。
splunk配置
打开splunk选择search&reporting应用
 在设置中选择添加数据选项,选择离线上传方式。
在设置中选择添加数据选项,选择离线上传方式。
 选择数据来源
选择数据来源
splunk自带了很多日志类型,如果没有与我们需要分析的日志匹配的,我们点击下一步。

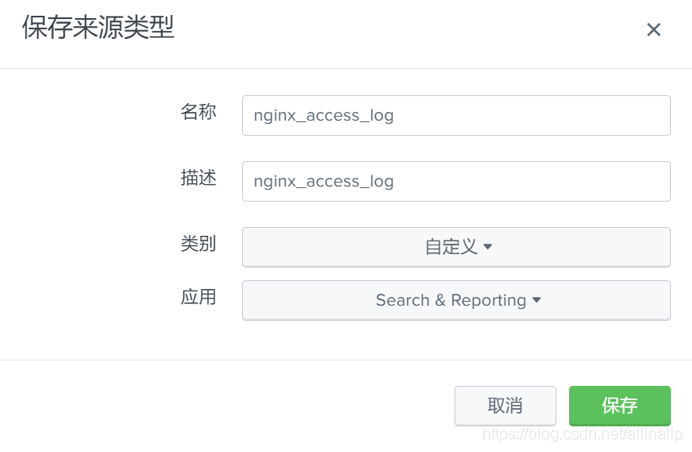
自定义来源类型
填写来源类型、名称及描述
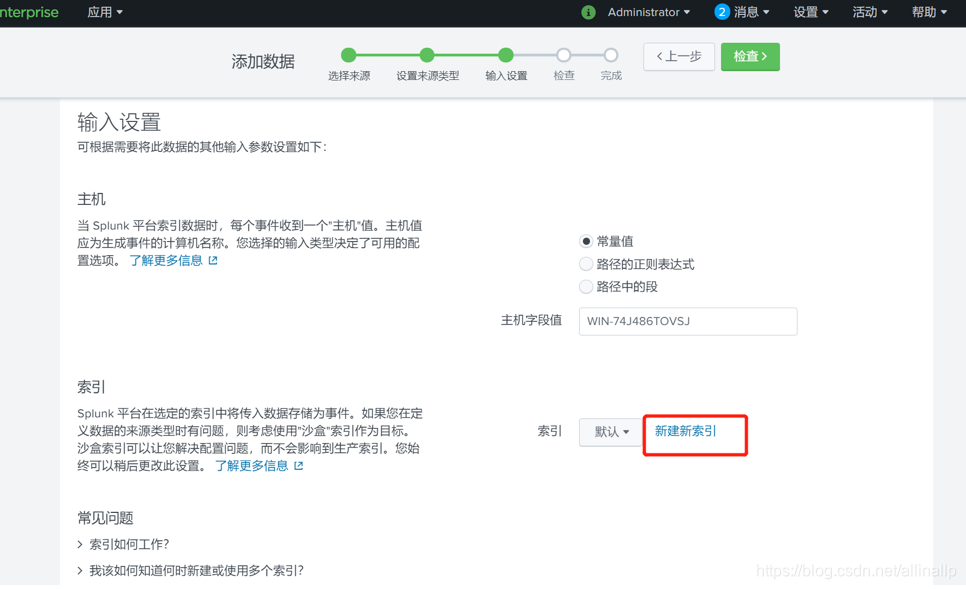
输入设置:
新建索引:Splunk 平台在选定的索引中将传入数据存储为事件,方便我们后期搜索。
这里设置索引为”2021nginx_access”
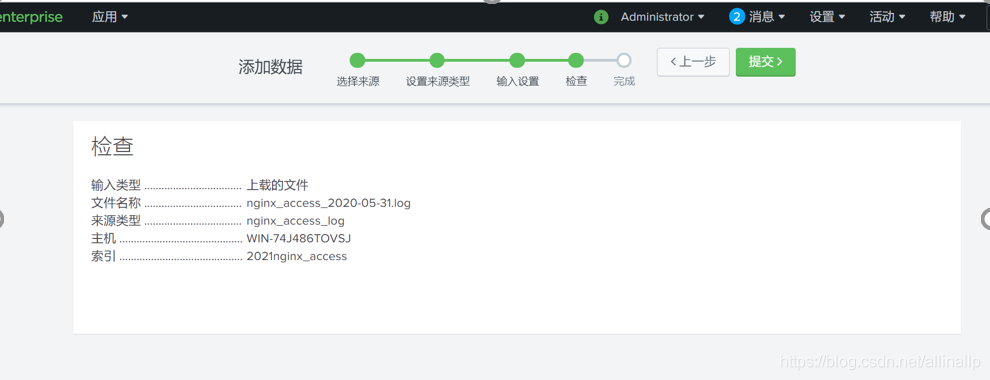
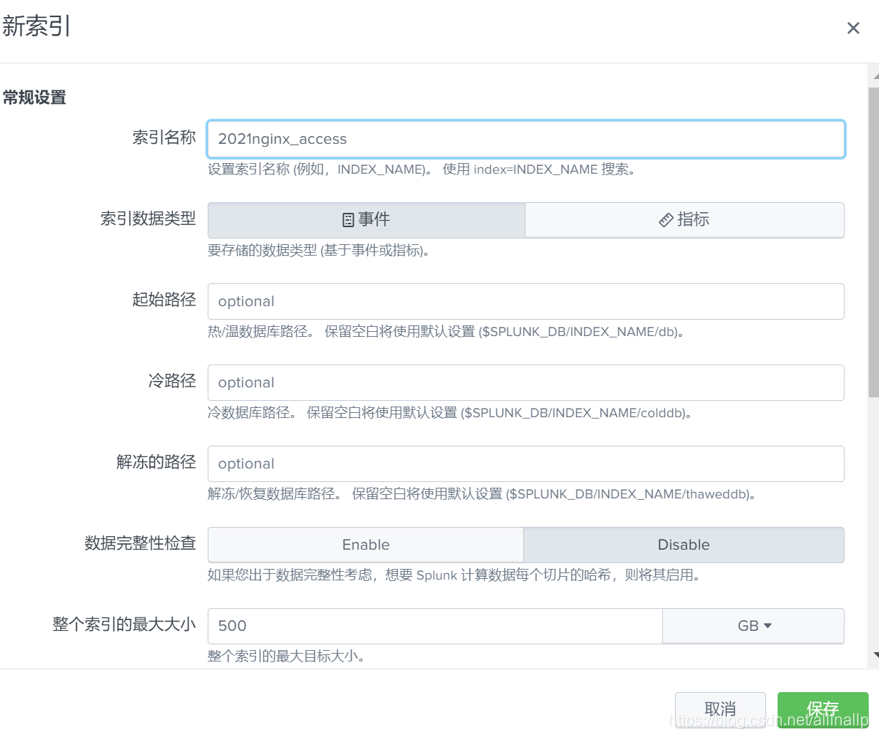 检查我们添加的数据信息:
检查我们添加的数据信息:
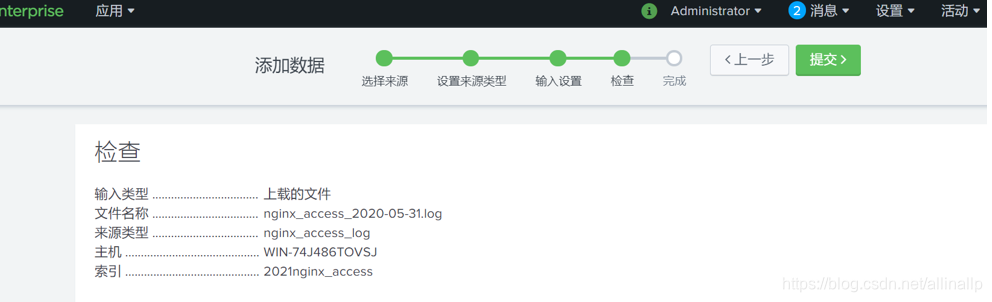 提交成功,进行搜索
提交成功,进行搜索
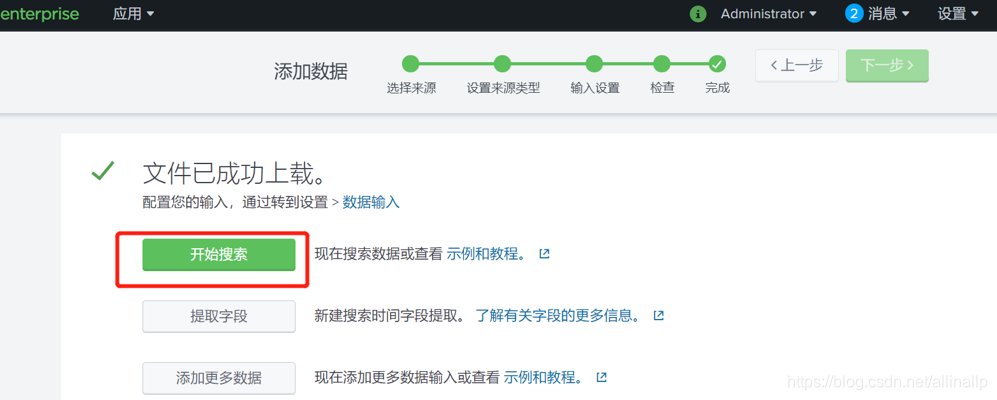 source=“nginx_access_2020-05-31.log” host=“WIN-74J486TOVSJ” index=“2021nginx_access” sourcetype=“nginx_access_log”
source=“nginx_access_2020-05-31.log” host=“WIN-74J486TOVSJ” index=“2021nginx_access” sourcetype=“nginx_access_log”
可以看到搜索匹配日志的重要参数,由于我们设置了索引,只需要保留index字段即可。
日志字段提取
接下来介绍一下,当splunk无法识别我们的日志类型时,无法自动提取我们想要的字段,平台提供了两种方式进行自定义的字段提取
在这一条记录中我们发现只有host、source、sourcetype三个字段,我们需要将日志内容字段进行提取
 在字段设置区域点击提取新字段
在字段设置区域点击提取新字段
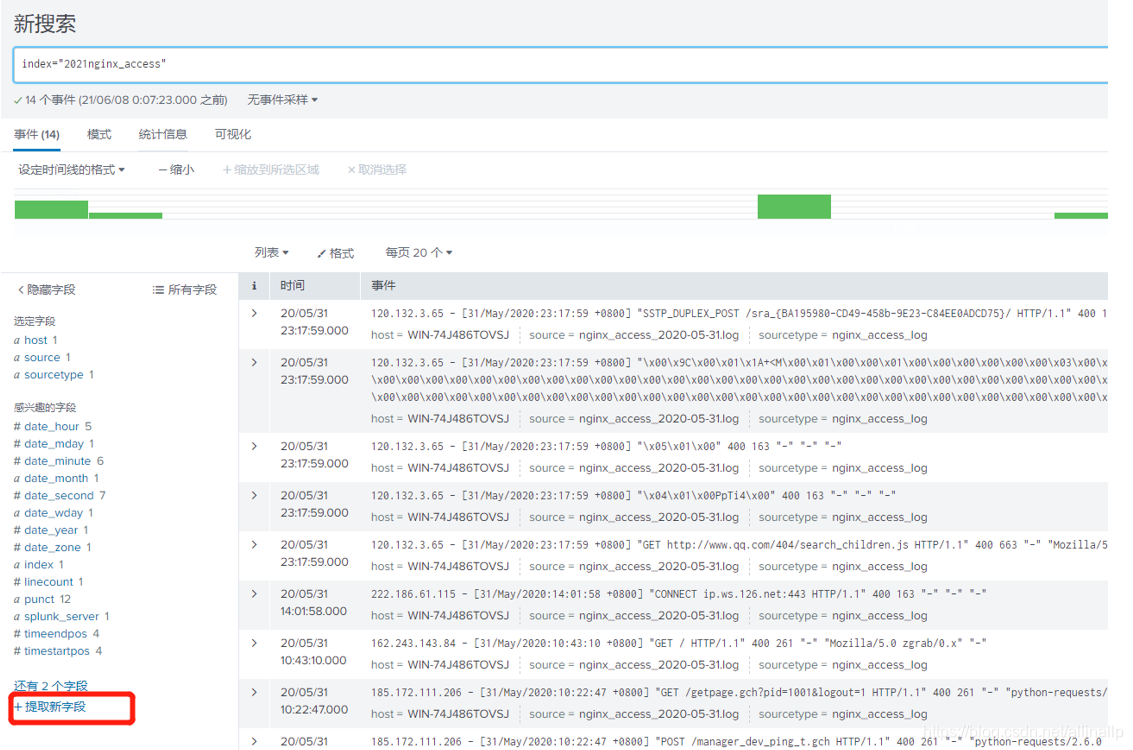
选择一条内容完整的日志作为提取的样例
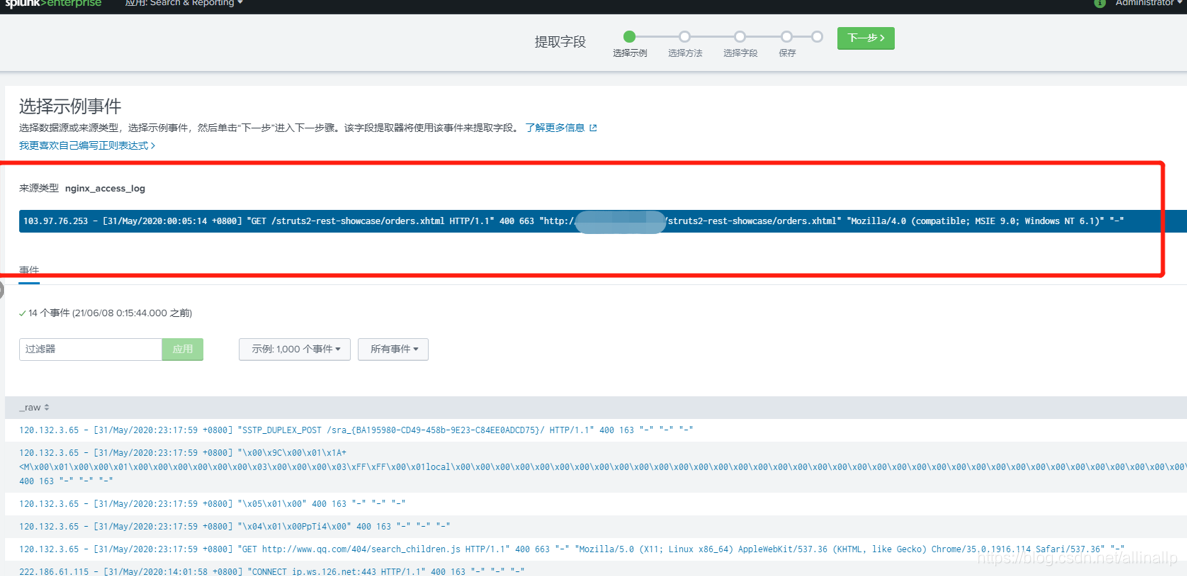
选择方法
Splunk提供了两种提取的方式,一种是正则表达,一种是分隔符,由于大部分日志记录没有明显的分隔符且日志字段复杂,所以一般情况下选择正则表达式。Splunk具有强大的自动生成正则表达式的功能,一般情况下不需要我们自己去写正则。
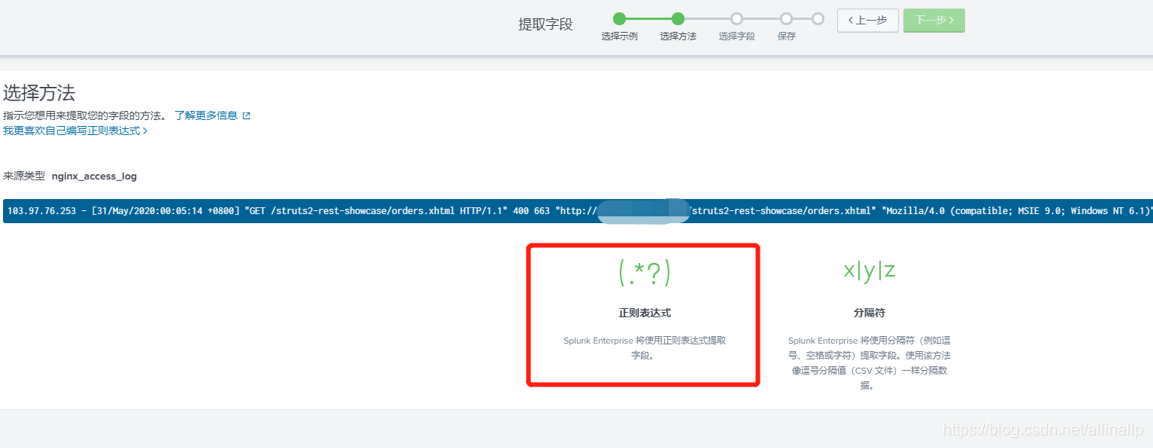
我们只需要勾选对应的字段,并设置字段名称,splunk会为我们自动生产正则表达式,并同将正则同步到所有的日志。
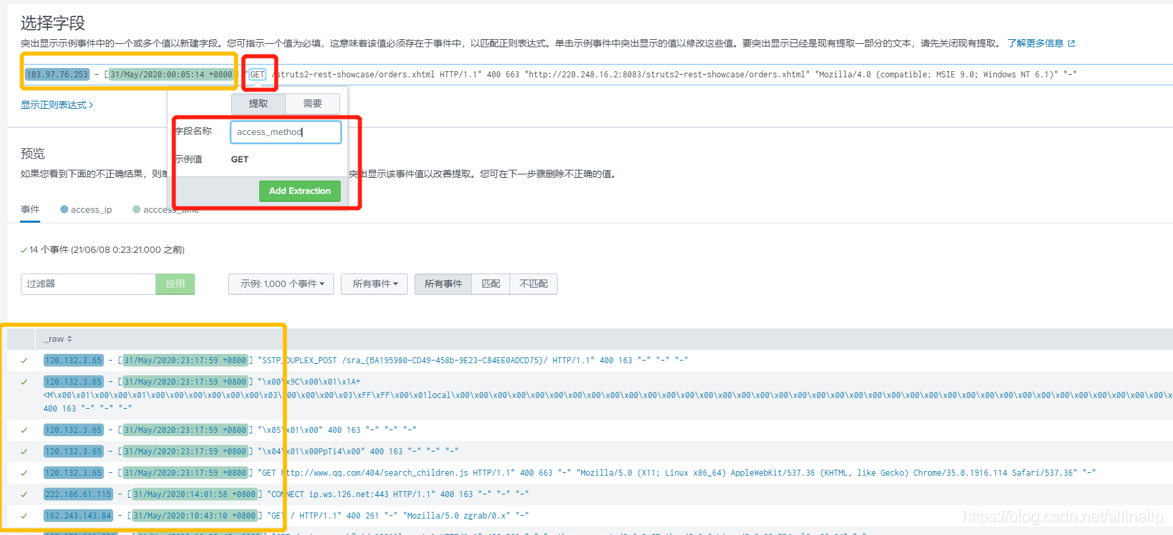
提取了7个重要的字段
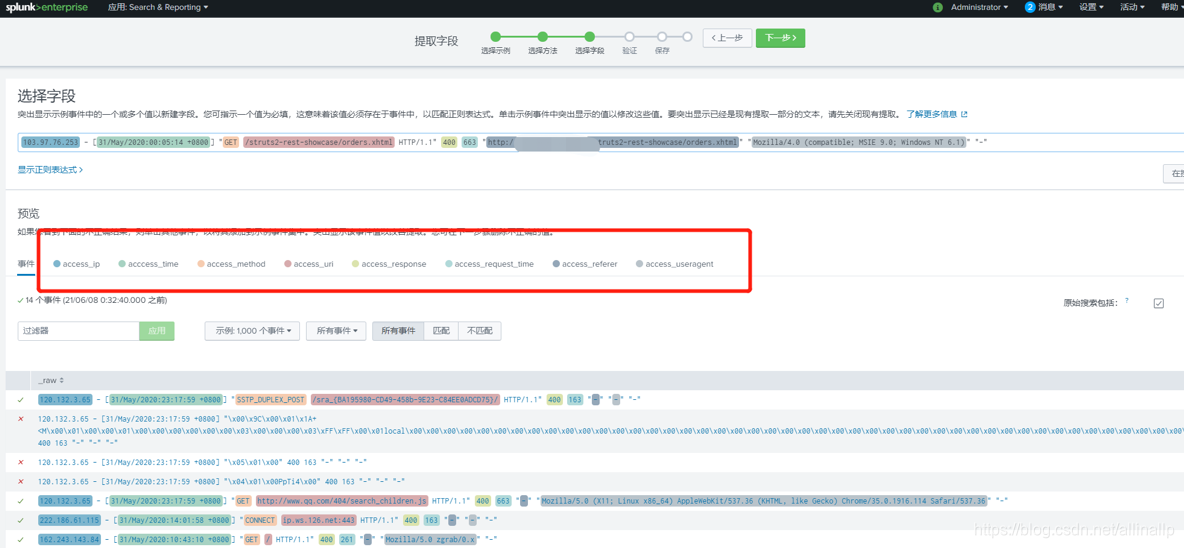
保存后对我们的正则进行验证,查看是否达到我们想要的提取效果
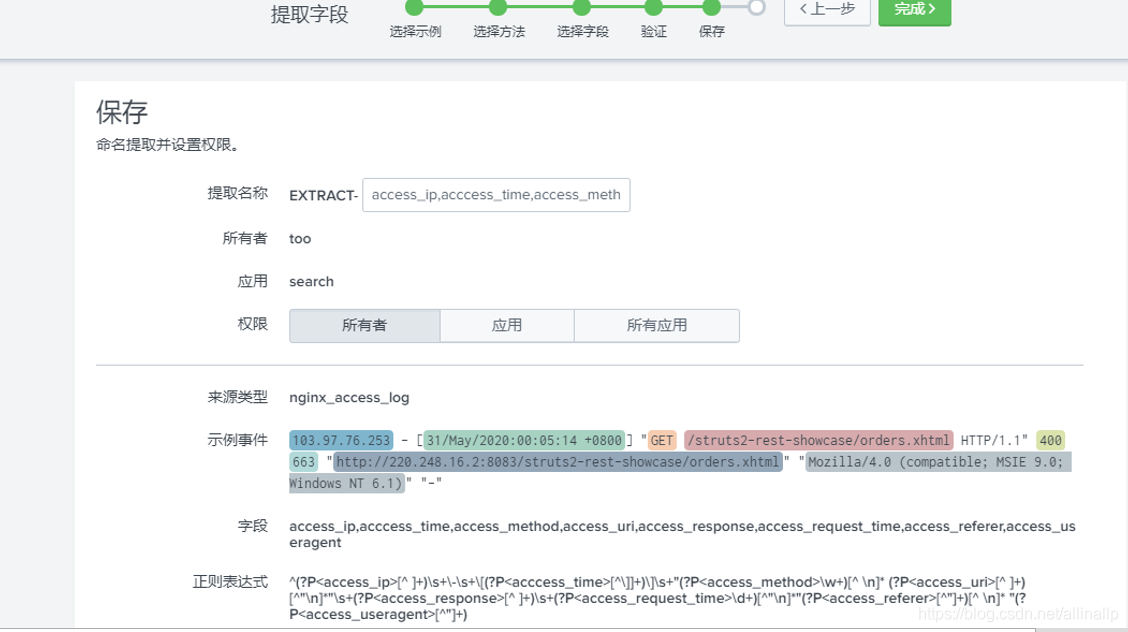
nginx access日志格式详解
time_local 本地时间戳
host 请求host地址
remote_addr 远程请求地址
request 请求uri
request_time 整个请求的总时间
body_bytes_sent 请求文件内容大小
status http请求状态
upstream_addr 后台提供服务的地址(即转发处理的目标地址)
upstream_reponse_time 请求时,upstream的响应时间
upstream_status upstream状态
http_refer url跳转来源
http_user_agent 用户终端浏览器的UserAgent
到此我们完成了日志的前期处理,接下来我们返回到搜索功能,定位我们的日志,选择提取的字段,发现所有字段提取成功。

日志分析场景
这里使用tomcat的access日志进行分析
已知ip,查看行为
使用语句进行筛选
index=“tomcat_log” tomcat_access_ip=xxx.165.152.167
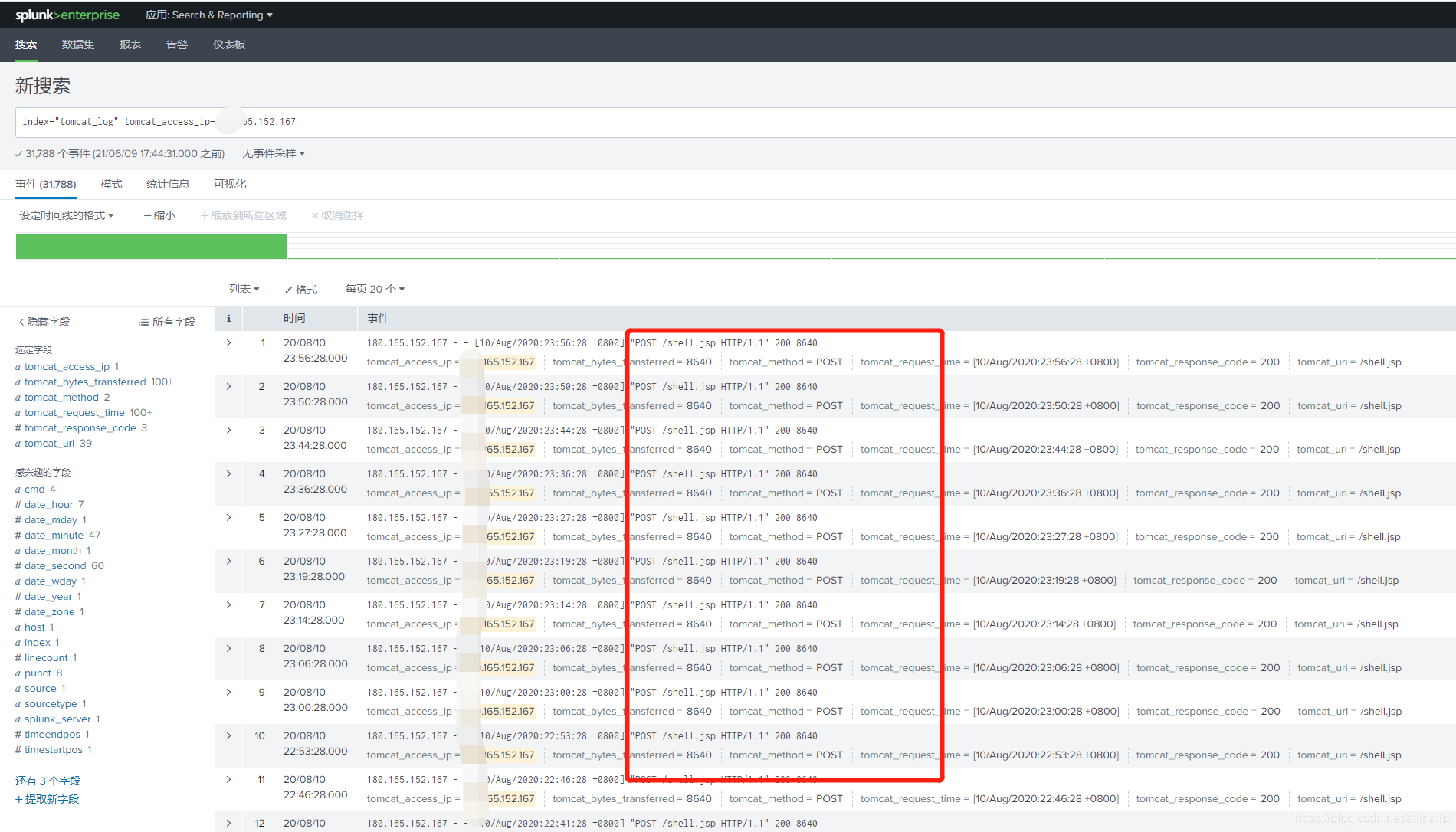 使用splunk语句查看该ip所有访问情况,可以快速查到该ip的行为
使用splunk语句查看该ip所有访问情况,可以快速查到该ip的行为
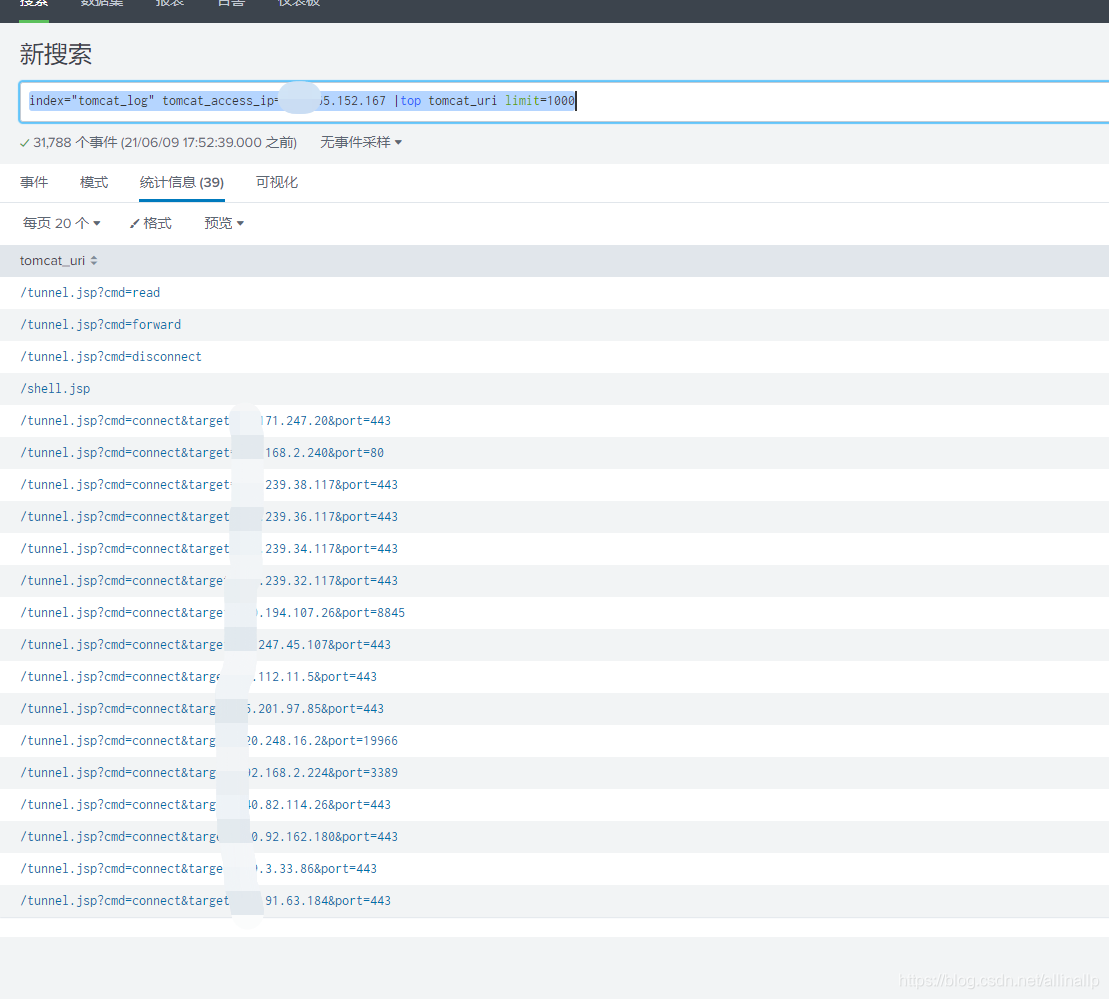
index=“tomcat_log” tomcat_access_ip=xxx.165.152.167 |top tomcat_uri limit=1000
 之后会继续更新splunk在安全服务场景中的使用情况,更多的splunk语句参考官方使用手册:https://docs.splunk.com/Documentation/Splunk/7.2.4/Translated/SimplifiedChinesemanuals
之后会继续更新splunk在安全服务场景中的使用情况,更多的splunk语句参考官方使用手册:https://docs.splunk.com/Documentation/Splunk/7.2.4/Translated/SimplifiedChinesemanuals

















 114
114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









