






如果以大模型为Kernel, 形成一个新的操作系统,那么:
1. byzer-llm 是这个大模型操作系统的编程接口,有点类似Linux操作系统的C ABI。
2. byzer-retrieval 也被集成进 byzer- llm 接口里,算是大模型操作系统的文件系统,应用可以通过python API 使用这个文件系统。
3. byzer-agent 算是应用开发框架,并且支持分布式,跨多机。
3. auto-coder 则是开发IDE 。
4. byzer-sql 则作为系统自带可以带的批,流,交互分析的数据库。
然后我简单画了一个图:
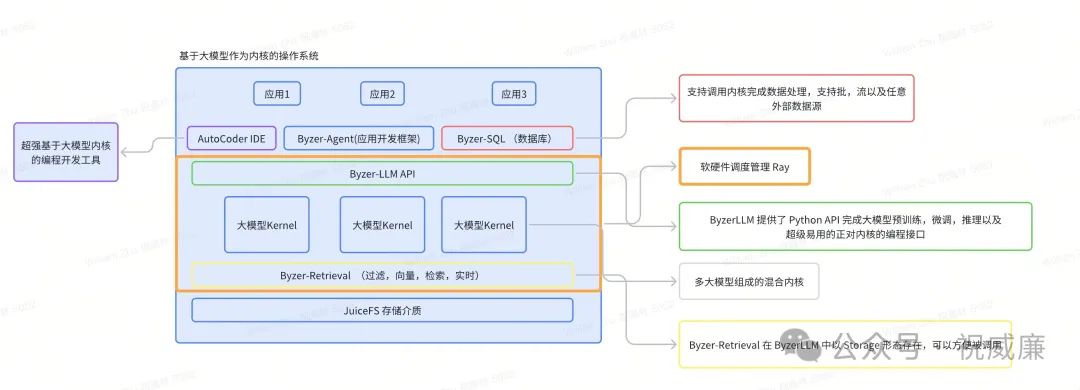
看起来还挺像回事,没想到竟然差不多都覆盖全了。
ByzerLLM 介绍
这个是我从去年打造的一款基于Ray的大模型交互软件,涵盖了模型的预训练,微调,以及部署,还有Python编程API。更多细节可以关注我们项目地址:https://github.com/allwefantasy/byzer-llm
这里我们简单介绍下他提供的基于大模型的编程API。
import byzerllm
byzerllm.connect_cluster()
@byzerllm.prompt(llm="gpt3_5_chat")
def hello_llm(name:str)->str:
'''
你好,我是{{ name }},你是谁?
'''
hello_llm("byzerllm")执行后输出:
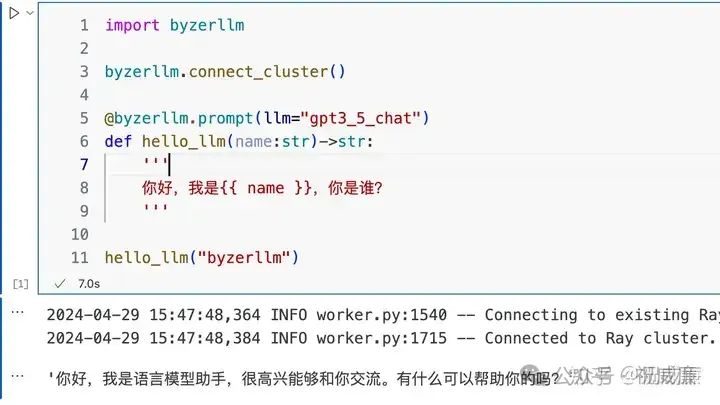
是不是很神奇?这就是 prompt 函数。可以看到,通过一个注解,所有和大模型的交互都被封装在一个函数里。你只要提供函数的 doc (prompt),并且支持使用 jinja2 语法渲染函数的参数。
如果你想知道发送给大模型的完整Prompt是啥?你可以这么用:
hello_llm.prompt("byzerllm")
你也可以换个模型去支持 hello_llm 函数:
hello_llm.with_llm("新模型").prompt("byzerllm")你是不是还经常被困扰的就是,因为大模型API一次输出有限制,而你正好要输出的内容又很长,该怎么办?byzerllm 也提供一个优雅的解决方案:
import byzerllm
from byzerllm import ByzerLLM
llm = ByzerLLM.from_default_model("deepseek_chat")
@byzerllm.prompt()
def tell_story() -> str:
"""
讲一个100字的故事。
"""
s = (
tell_story.with_llm(llm)
.with_response_markers()
.options({"llm_config": {"max_length": 10}})
.run()
)
print(s)输出为:
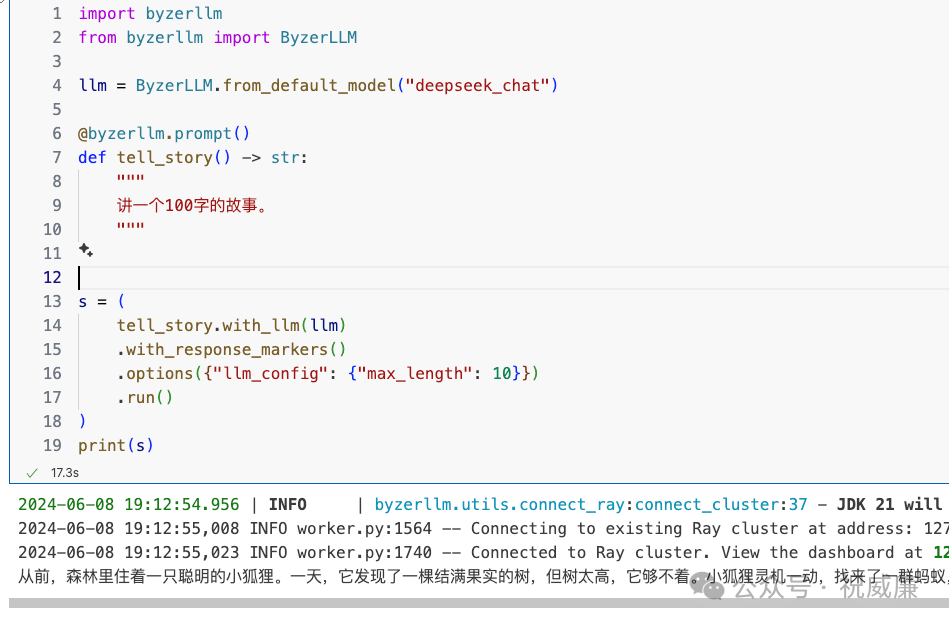
这里,我们让prompt 函数 tell_story 给我们讲个故事,我们人为的限制了模型每次最多只能回复 10个字,但是依然我们让他把故事讲完了。怎么实现的呢?秘密在于那个 with_response_markers,你只要设置这个值,那么就可以自动突破限制,并且能够自动完美的结束。
byzer-retrieval
算是大模型kernel 的外挂,也就是我们现在说的RAG存储。你可以通过一条命令就完成它的下载和安装:
byzerllm storage start现在,你就可以在多种情况使用它。比如你可以通过 byzerllm 提供的 Python API 直接和他交互,比如查找某个集群下的某个库表的数据,支持同时进行向量检索和全文检索,并且重排后返回新结果:
from byzerllm.records import SearchQuery
retrieval.search("cluster1",
[SearchQuery(database="db1",table="table1",keyword="c",fields=["content"], filters={},
vector=[1.0,2.0,3.0],vectorField="vector",
limit=10)])
## output: [{'name': 'a', 'raw_content': 'b c', '_id': 1, '_score': 0.033333335},
## {'name': 'd', 'raw_content': 'b e', '_id': 2, '_score': 0.016393442}]或者被比如编程工具auto-coder 使用,一键构建知识库:
auto-coder doc build --source_dir /Users/allwefantasy/projects/doc_repo \
--model gpt3_5_chat \
--emb_model gpt_emb然后查询:
auto-coder doc query --model gpt3_5_chat \
--emb_model gpt_emb \
--query "如何通过 byzerllm 部署 gpt 的向量模型,模型名字叫 gpt_emb "输出:
=============RESPONSE==================
2024-04-29 16:09:00.048 | INFO | autocoder.utils.llm_client_interceptors:token_counter_interceptor:16 - Input tokens count: 0, Generated tokens count: 0
通过 byzerllm 部署 gpt 的向量模型,模型名字叫 gpt_emb,需要使用以下命令:
```
byzerllm deploy --pretrained_model_type saas/openai \
--cpus_per_worker 0.001 \
--gpus_per_worker 0 \
--num_workers 1 \
--infer_params saas.api_key=${MODEL_OPENAI_TOKEN} saas.model=text-embedding-3-small \
--model gpt_emb
```
=============CONTEXTS==================
/Users/allwefantasy/projects/doc_repo/deploy_models/run.txtByzer-Agent
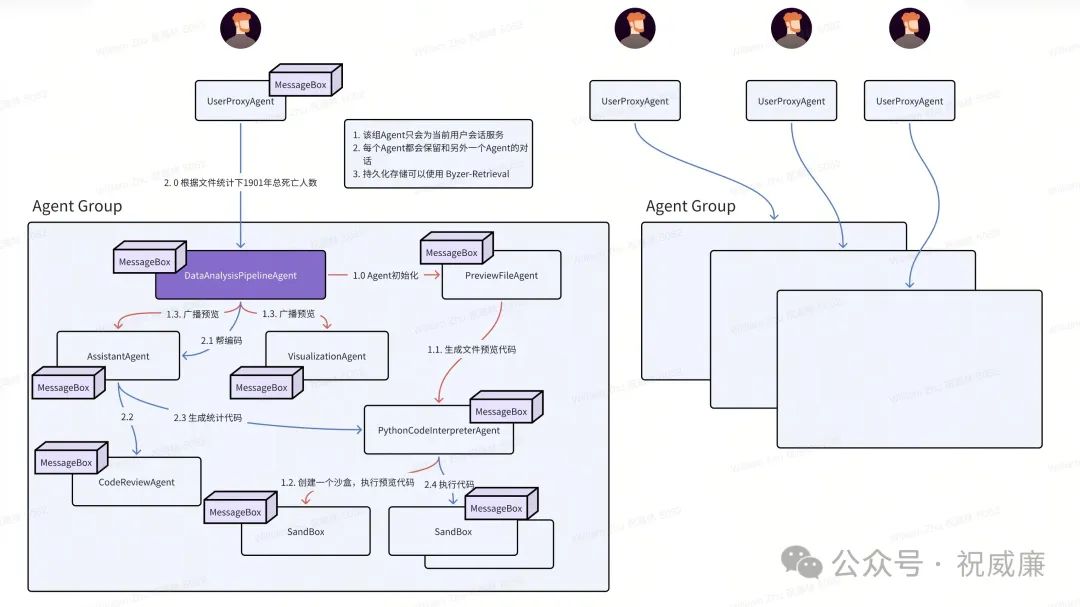
Byzer-Agent框架和其他框架相比,主要聚焦在分布式Agent上,也就是你可以让一组Agent 分布在不同的节点上,并且实现通讯。
下面是我们实现的一个例子,你可以在
https://github.com/allwefantasy/byzer-agent 这里看到。也就是你可以基于 byzer-agent 开发分布式agent应用。
auto-coder
auto-coder 是一款 命令行 + YAML 的编程辅助工具。你描述完需求后,他可以自动找到合适的文件尽心修改,修改后合并会你的项目,并且给你提交commit。比如下面我希望对一个项目做如下描述的修改,基本可以一次过,不需要人工干预。auto-coder 也是基于 byzerllm API 试下和大模型交互的。
byzer-sql
Byzer-SQL 支持使用SQL 进行数据分析,批处理,流式计算。并且通过 byzerllm, 它能够将任意主流大模型注册成 SQL 函数。
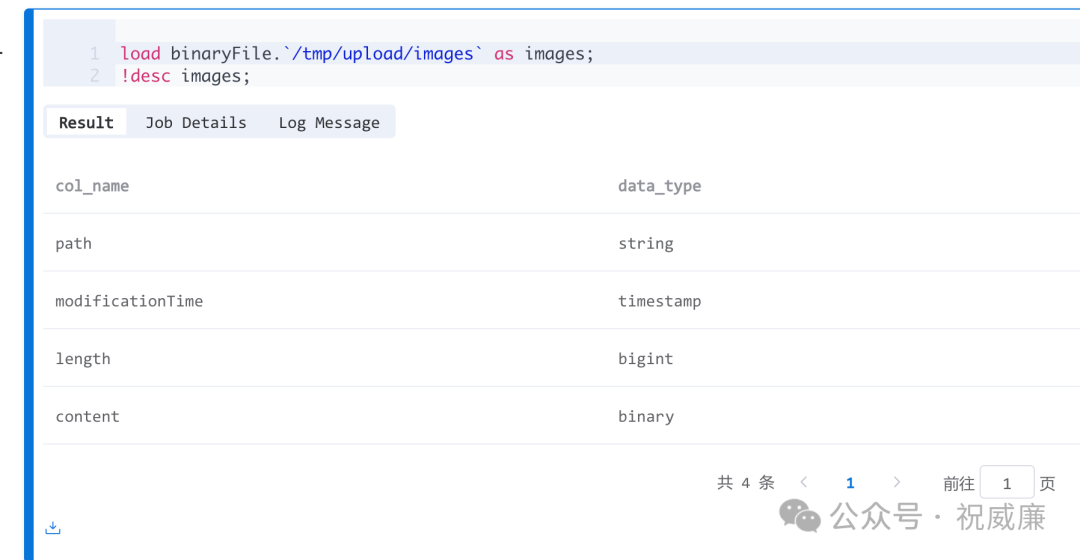
比如,我可以加载图片:
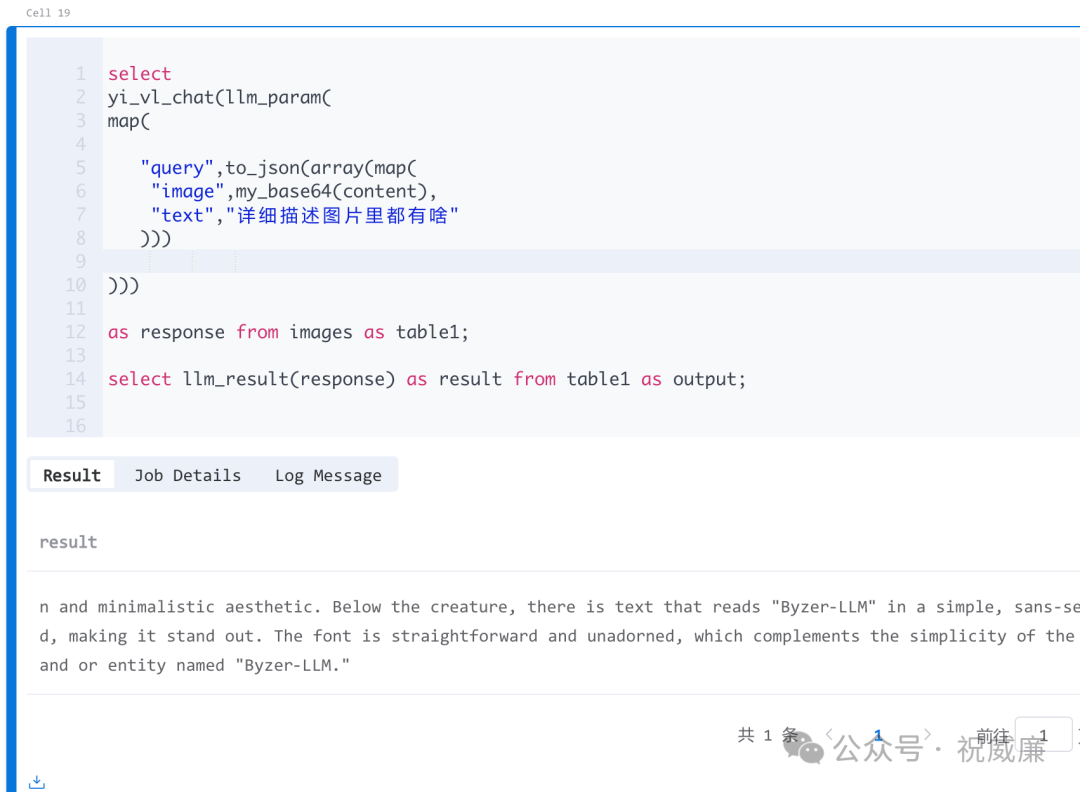
然后用一条SQL语句就把这些图片全部转换成文字:
通过 Byzer-SQL,你可以很方便的对数据使用大模型来处理,也可以助力你完成数据分析,比如通过SQL实时提取一些数据,然后提取的数据直接在SQL中让大模型做解读:
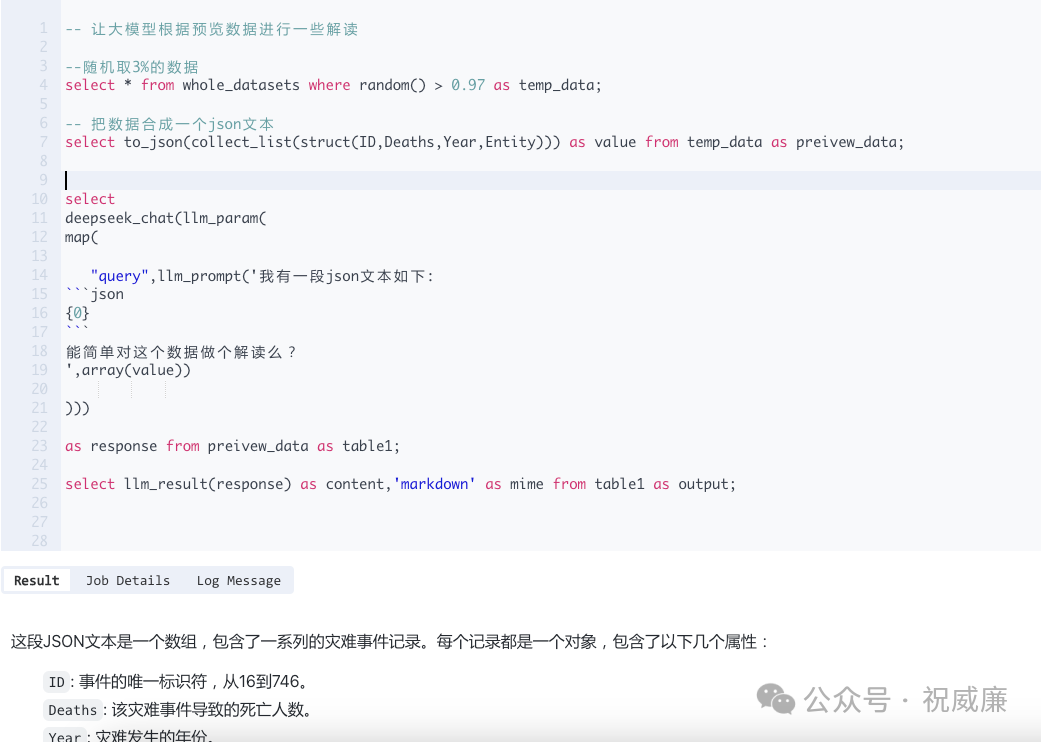
解读结果:

总结
欢迎大家组合使用。















 213
213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









