






每天上下班的路上,总有暖心的声音为你化解堵车时的焦躁情绪;每段外出的旅行,都有贴心的耳语陪你探索陌生的风景。在这一系列体验的背后,是高德语音技术从“标准化服务”到“场景化适配”的深度进化。通过自定义语音包复刻家人和爱人声音,导航不再是冰冷的指令,而是情感的延伸,让最重要的“他/她”时刻陪伴左右。临近端午和六一,你是否也想将自家的萌娃装进地图里,每日陪伴旅程呢?欢迎来试用高德自定义语音包功能。
在本期技术分享中,我们将向大家介绍高德地图用户自定义语音包功能的核心技术细节,展示语音大模型在高德地图出行领域的实际应用。
01
核心技术揭秘
TTS技术的前世今生
语音合成(Text-to-Speech, TTS)技术的发展历程,是一部人类与机器“说话”能力不断演进的历史。从最初的机械发声装置到如今的深度学习模型,TTS技术经历了从机械模拟到人工智能驱动的跨越,逐步实现了语音合成的自然化、个性化和智能化。在人工智能时代,TTS技术也从传统的声学特征生成式模型过渡到了现在基于Token+LLM based大模型方案,用户对于语音的需求也朝着个性化定制和多模态交互方向发展。本期我们将向大家揭秘高德地图在个性化定制用户声音上的技术创新,揭秘高德地图自定义语音包技术的黑科技,为大家呈现如何仅仅使用3句用户的录音即可高效、逼真的还原用户的音色。
技术选型-支持亿级设备部署的极致端模型
高德作为国民出行软件,服务于大家的日常出行,而其中导航是语音的最大使用时长场景。保证在各类配置的手机和复杂网络环境(地库、隧道、无人区等)都能稳定合成是我们面临的独特挑战。这就要求我们有一套极致的端模型方案,既可以满足复杂多样音色的定制能力,又能够以较低性能要求在各类端侧运行。因此,在技术选型上我们采用了一种极轻量级的端侧声学模型作为主体,在后文我们也会介绍如何通过TTS大模型数据增强进一步提高效果。
具体来讲,端侧模型的训练分为预训练、蒸馏和微调三个阶段。
第一阶段,我们首先会基于数千位高质量录音人的数据训练一个声学基础模型,模型在训练时,会对语义信息和说话人信息进行特征分离,以确保我们通过大规模数据进行预训练时可以充分实现说话人信息和语义信息的解耦,确保模型在微调阶段仅需调整少量的参数,加速模型产出的速度。
第二阶段,我们会对第一阶段的预训练模型进行Teacher - Force蒸馏。具体实现上,我们会对模型的Encoder中间层引入一个Hubert-Feature Map损失函数,确保蒸馏模型的中间层保留足够充足的语义信息,实现语义和说话人的特征分离。此外,蒸馏模型由于参数量较少,因此会比较难直接的去学习真实声学特征所包含的复杂的分布信息。因此,我们设计了Teacher - Force蒸馏的方案,通过同时约束蒸馏模型预测的声学特征和真实声学特征及基础模型预测的声学特征之间的误差,确保模型既可以较低难度的学习基础模型的声学输出,也可以同时保证蒸馏模型尽可能接近真实声学特征输出。
模型架构可以参考下图:
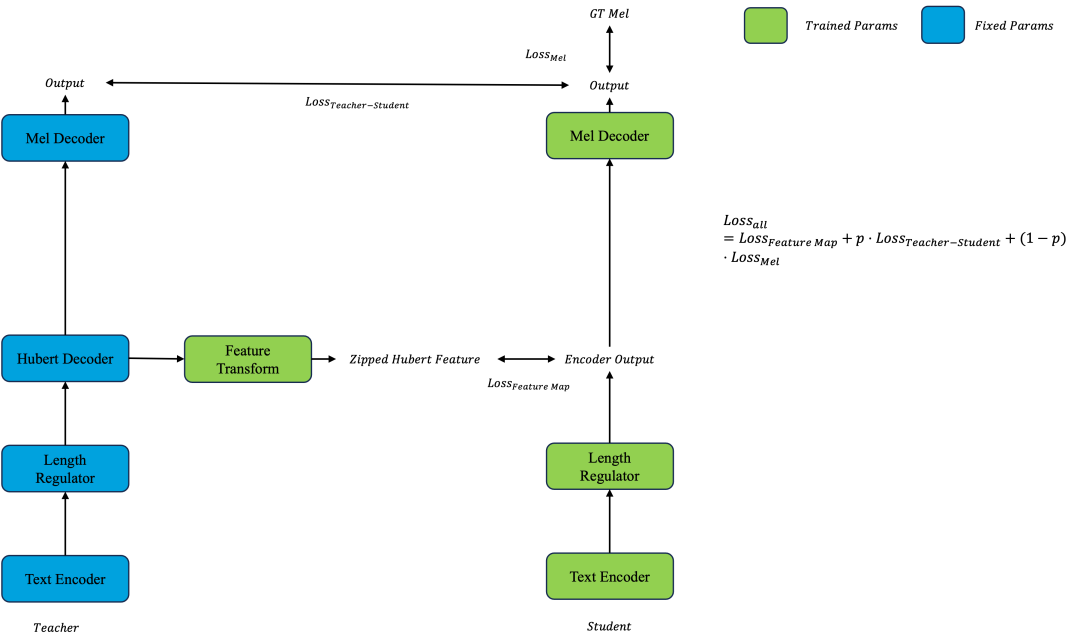
第三阶段,我们将对第二阶段产出的极轻量级声学模型进行微调,微调时仅对说话相关的参数进行参数更新,确保模型可以快速完成微调过程。模型微调完成后,我们会对高德用户的高频导航话术进行推理,实现第一级缓存机制。
经过上述模型训练后,我们会将声学模型及一个通用的源-滤波器架构的声码器下发到用户的设备上,所有模型的总参数量小于5M,属于目前业界内极小的全神经网络的端侧模型,在音质和性能上明显领先同行业的相同技术方案。
以下为我们端侧模型的实际上线效果展示,每位用户仅录制10s左右的音频:
| 原声 | 合成音频 |
|---|---|
数据增广:双自回归架构TTS大模型
为了避免端侧模型微调时数据不足引发的效果下降,我们采用了数据增强的策略。通过自研的双自回归TTS大模型对用户录制的3句话进行zeroshot复刻和增广。相较基于单码本的方法来说,双自回归结构可以更好地捕捉到音色与韵律细节,并获得更高的音质,模型结构参考下图:
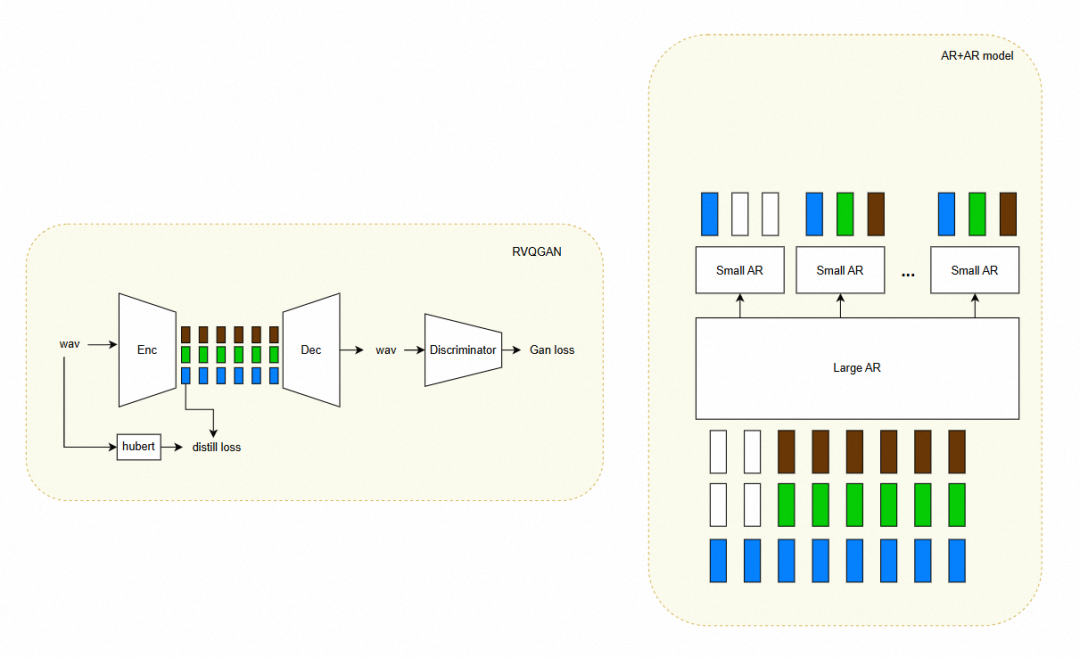
在音频编码上,我们使用了基于dac的rvq编码,码表大小为8码本25Hz,并使用CNhubert对第一个码本进行了蒸馏,以这种方式进行编码可以兼顾语义信息以及声学信息,实现高音色相似度与稳定性,同时可以避免发音咬字错误。我们的码表设计在保证低码率的优势下,同时也实现了音频音质的高保证还原。
在进行合成时,首先对用户音频进行编码得到音频的离散编码,将离散编码输入到模型中作为参考音频进行续写合成,这里会使用预设好的文本进行合成。相关工作会在之后进行开源,敬请期待。
从录音到模型发布:全栈声学能力加持
语音包生产链路也是自定义语音包的重要一环,需要全栈的声学能力进行加持。从用户录制三句话语音,到用户使用上语音包,是一个逻辑上“串联”的流程,中间需要经过录音检测、音质检测、语音降噪、语音标准化、排队数据增广、排队后训练等级联过程。语音信号处理领域涉及到的音频基础能力多且琐碎,分散于生产链路的全过程,例如:信噪比检测、MOS 打分、WER 打分、音色相似度检测、降噪、音量标准化等。为了保证分散的音频基础能力敏捷性、统一性、可迭代性,我们设计了一套用于“编排”音频原子能力的生产服务。配置式“编排”一张音频处理的有向无环图,以音频基础能力为图节点,以处理先后顺序为有向边,可以编排出多样复杂的音频处理综合能力。例如,在音频前处理阶段,需要在音量标准化后检测信噪比和 MOS 分,判断是否需要对音频进行降噪去混响操作,再对音频静音部分进行截断。这样一个复杂过程,我们仅需要通过配置的方式编排一张音频流水线有向无环图,即可完成业务处理逻辑,实现“零代码”。

其优势在于:
(1)敏捷性:快速编排音频处理能力,迅速验证是否达到业务标准。
(2)统一性:收容琐碎的音频处理基础能力,规避因实现方式差异导致的效果差异。
(3)可迭代性:实现音频处理节点的业务无感迭代,如,实现了更优降噪模型后,升级降噪节点即可,对业务无侵入。
02
快速体验
极简操作|录制3句话,10分钟内定制用户专属声纹语音包
场景丰富|可在开始导航、电子眼提醒等场景补充录制趣味导航语音,埋藏“搞笑彩蛋”或“暖心提醒”
个性化领航员|以用户照片生成多种风格的数字人形象,在导航等场景与用户进行AI智能问答交互
社交传播|个人录制的优质语音包,可自行上架为商品,分享给更多人使用,流量变现
03
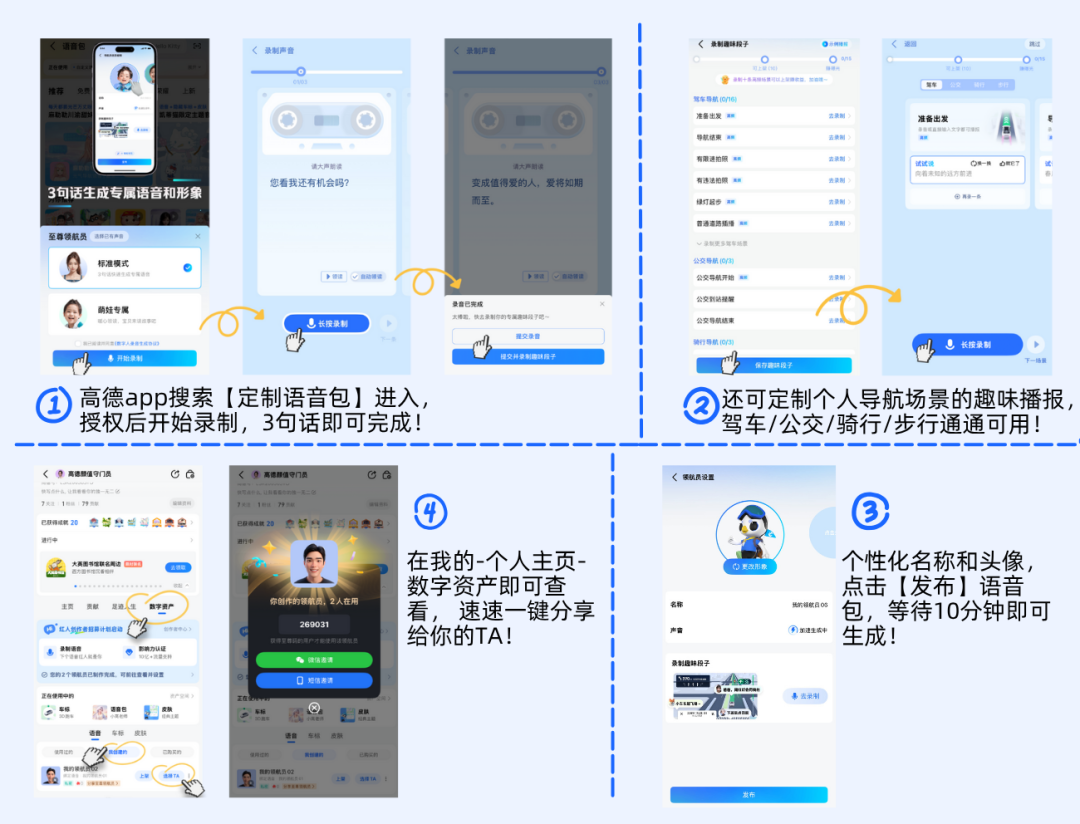
用户操作示意图
04
未来迭代规划
更加高效|录制效率更快,减少用户的录制时长和语音包生产速度;
更极致的语音表现力|追求更加活灵活现的语音效果和多样化表达;
更棒的交互体验|更多地图场景下接入个性化语音服务,做好一张活地图。


















 923
923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









