







驱动设计的硬件基础
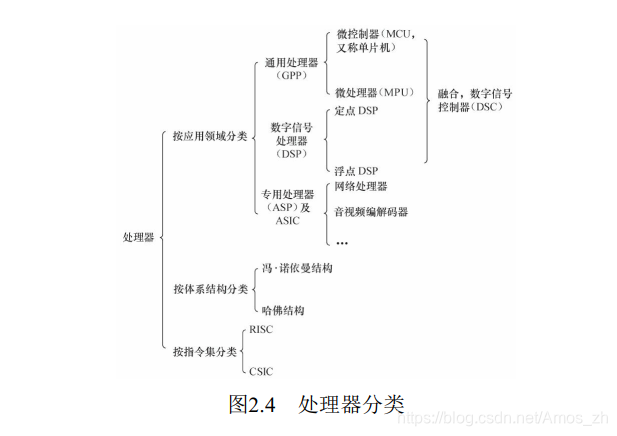
一、处理器
1.通用处理器(GPP)
目前主流的通用处理器(GPP) 多采用SoC(片上系统) 的芯片设计方法, 集成了各种功能模块, 每一种功能都是由硬件描述语言设计程序, 然后在SoC内由电路实现的。
在SoC中, 每一个模块不是一个已经设计成熟的ASIC器件, 而是利用芯片的一部分资源去实现某种传统的功能, 将各种组件采用类似搭积木的方法组合在一起。
ARM的功耗很低, 在当今最活跃的无线局域网、 3G、 手机终端、 手持设备、 有线网络通信设备等中应用非常广泛。
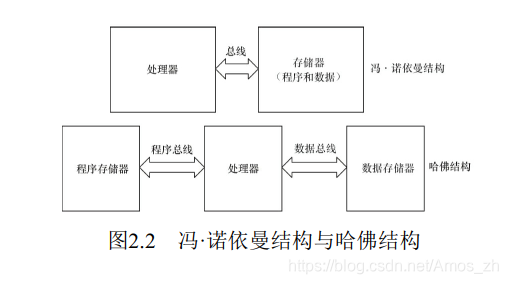
中央处理器的体系结构可以分为两类, 一类为冯·诺依曼结构, 另一类为哈佛结构。
冯·诺依曼结构也称普林斯顿结构, 是一种将程序指令存储器和数据存储器合并在一起的存储器结构。 程序指令存储地址和数据存储地址指向同一个存储器的不同物理位置, 因此程序指令和数据的宽度相同。
哈佛结构将程序指令和数据分开存储, 指令和数据可以有不同的数据宽度。 此外, 哈佛结构还采用了独立的程序总线和数据总线, 分别作为CPU与每个存储器之间的专用通信路径, 具有较高的执行效率。图2.2描述了冯·诺依曼结构和哈佛结构的区别。
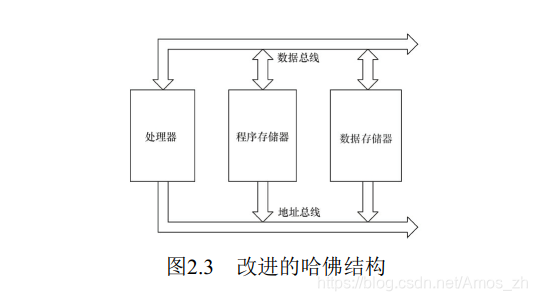
 许多芯片采用的是如图2.3所示的
许多芯片采用的是如图2.3所示的改进的哈佛架构, 它具有独立的地址总线和数据总线, 两条总线由程序存储器和数据存储器分时共用。 因此, 改进的哈佛结构针对程序和数据, 其实没有独立的总线, 而是使用公用数据总线来完成程序存储模块或数据存储模块与CPU之间的数据传输, 公用的地址总线来寻址程序和数据。
 从指令集的角度来讲, 中央处理器也可以分为两类, 即RISC(精简指令集计算机) 和CISC(复杂指令集计算机) 。
从指令集的角度来讲, 中央处理器也可以分为两类, 即RISC(精简指令集计算机) 和CISC(复杂指令集计算机) 。 CSIC强调增强指令的能力、 减少目标代码的数量, 但是指令复杂, 指令周期长; 而RISC强调尽量减少指令集、 指令单周期执行, 但是目标代码会更大。 ARM、 MIPS、 PowerPC等CPU内核都采用了RISC指令集。 目前, RISC和CSIC两者的融合非常明显。
2.数字信号处理器
数字信号处理器(DSP) 针对通信、 图像、 语音和视频处理等领域的算法而设计。它包含独立的硬件乘法器。 DSP的乘法指令一般在单周期内完成, 且优化了卷积、 数字滤波、 FFT(快速傅里叶变换) 、 相关矩阵运算等算法中的大量重复乘法。
DSP分为两类, 一类是定点DSP, 另一类是浮点DSP。 浮点DSP的浮点运算用硬件来实现, 可以在单周期内完成, 因而其浮点运算处理速度高于定点DSP。 而定点DSP只能用定点运算模拟浮点运算。
德州仪器(TI) 、 美国模拟器件公司(ADI) 是全球DSP的两大主要厂商。
除了上面讲述的通用微控制器和数字信号处理器外, 还有一些针对特定领域而设计的专用处理器(ASP) , 它们都是针对一些特定应用而设计的, 如用于HDTV、 ADSL、 Cable Modem等的专用处理器。
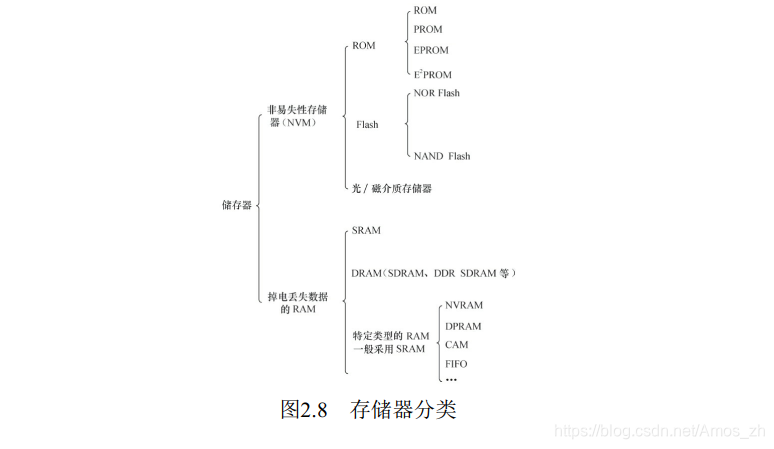
二、存储器
存储器主要可分类为只读储存器(ROM) 、 闪存(Flash) 、 随机存取存储器(RAM) 、 光/磁介质储存器。
ROM还可再细分为不可编程ROM、 可编程ROM(PROM) 、 可擦除可编程ROM(EPROM) 和电可擦除可编程ROM(E2PROM) , E2PROM完全可以用软件来擦写, 已经非常方便了。
NOR(或非) 和NAND(与非) 是市场上两种主要的Flash闪存技术。 Intel于1988年首先开发出NOR Flash技术, 彻底改变了原先由EPROM和EEPROM一统天下的局面。 紧接着, 1989年, 东芝公司发表了NAND Flash结构, 每位的成本被大大降低。
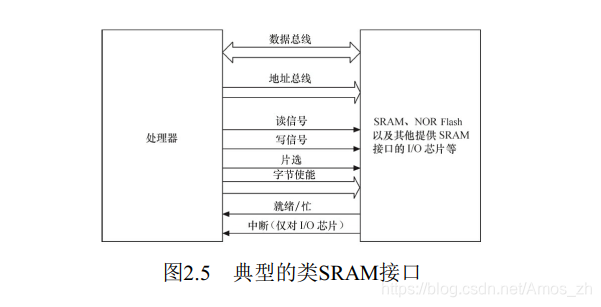
NOR Flash和CPU的接口属于典型的类SRAM接口(如图2.5所示) , 不需要增加额外的控制电路。NOR Flash的特点是可芯片内执行(eXecute In Place, XIP) , 程序可以直接在NOR内运行。
NAND Flash和CPU的接口必须由相应的控制电路进行转换, 当然也可以通过地址线或GPIO产生NAND Flash接口的信号。 NAND Flash以块方式进行访问, 不支持芯片内执行。
与NOR Flash的类SRAM接口不同, 一个NAND Flash的接口主要包含如下信号:
- I/O总线: 地址、 指令和数据通过这组总线传输, 一般为8位或16位。
- 芯片启动(Chip Enable, CE#) : 如果没有检测到CE信号, NAND器件就保持待机模式, 不对任何控制信号做出响应。
- 写使能(Write Enable, WE#) : WE#负责将数据、 地址或指令写入NAND之中。
- 读使能(Read Enable, RE#) : RE#允许数据输出。
- 指令锁存使能(Command Latch Enable, CLE) : 当CLE为高电平时, 在WE#信号的上升沿, 指令将被锁存到NAND指令寄存器中。
- 地址锁存使能(Address Latch Enable, ALE) : 当ALE为高电平时, 在WE#信号的上升沿, 地址将被锁存到NAND地址寄存器中。
- 就绪/忙(Ready/Busy, R/B#) : 如果NAND器件忙, R/B#信号将变为低电平。 该信号是漏极开路,需要采用上拉电阻。
NAND Flash较NOR Flash容量大, 价格低; NAND Flash中每个块的最大擦写次数是100万次, 而NOR的擦写次数是10万次; NAND Flash的擦除、 编程速度远超过NOR Flash。
由于Flash固有的电器特性, 在读写数据过程中, 偶然会产生1位或几位数据错误, 即位反转, NANDFlash发生位反转的概率要远大于NOR Flash。 位反转无法避免, 因此, 使用NAND Flash的同时, 应采用错误探测/错误更正(EDC/ECC) 算法。
Flash的编程原理都是只能将1写为0, 而不能将0写为1。 因此在Flash编程之前, 必须将对应的块擦除, 而擦除的过程就是把所有位都写为1的过程, 块内的所有字节变为0xFF。 另外, Flash还存在一个负载均衡的问题, 不能老是在同一块位置进行擦除和写的动作, 这样容易导致坏块。
值得一提的是, 目前NOR Flash可以使用SPI接口进行访问以节省引脚。 相对于传统的并行NOR Flash而言, SPI NOR Flash只需要6个引脚就能够实现单I/O、 双I/O和4个I/O口的接口通信, 有的SPI NOR Flash还支持DDR模式, 能进一步提高访问速度到80MB/s。
以上所述的各种ROM、 Flash和磁介质存储器都属于非易失性存储器(NVM) 的范畴, 掉电时信息不会丢失, 而RAM则与此相反。
RAM也可再分为静态RAM(SRAM) 和动态RAM(DRAM) 。 DRAM以电荷形式进行存储, 数据存储在电容器中。 由于电容器会因漏电而出现电荷丢失, 所以DRAM器件需要定期刷新。 SRAM是静态的,只要供电它就会保持一个值, SRAM没有刷新周期。
针对许多特定场合的应用, 嵌入式系统中往往还使用了一些特定类型的RAM。
1.DPRAM: 双端口RAM
DPRAM的特点是可以通过两个端口同时访问, 具有两套完全独立的数据总线、 地址总线和读写控制线, 通常用于两个处理器之间交互数据, 如图2.6所示。 当一端被写入数据后, 另一端可以通过轮询或中断获知, 并读取其写入的数据。
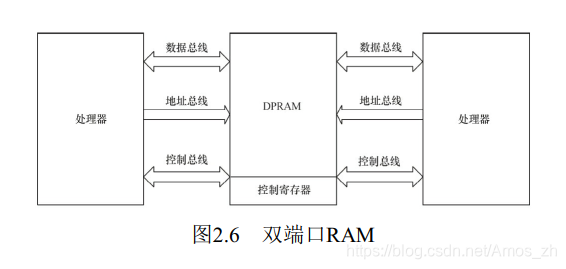 DPRAM的优点是通信速度快、 实时性强、 接口简单, 而且两边处理器都可主动进行数据传输。 除了双端口RAM以外, 目前IDT等芯片厂商还推出了多端口RAM, 可以供3个以上的处理器互通数据。
DPRAM的优点是通信速度快、 实时性强、 接口简单, 而且两边处理器都可主动进行数据传输。 除了双端口RAM以外, 目前IDT等芯片厂商还推出了多端口RAM, 可以供3个以上的处理器互通数据。
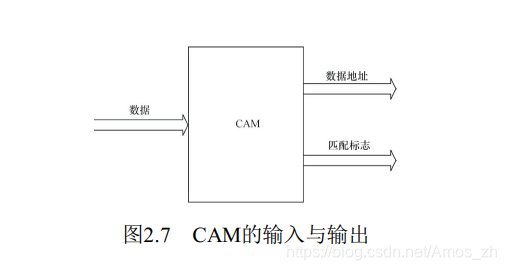
2.CAM: 内容寻址RAM
CAM是以内容进行寻址的存储器, 是一种特殊的存储阵列RAM, 它的主要工作机制就是同时将一个输入数据项与存储在CAM中的所有数据项自动进行比较, 判别该输入数据项与CAM中存储的数据项是否相匹配, 并输出该数据项对应的匹配信息。
如图2.7所示, 在CAM中, 输入的是所要查询的数据, 输出的是数据地址和匹配标志。 若匹配(即搜寻到数据) , 则输出数据地址。 CAM用于数据检索的优势是软件无法比拟的, 它可以极大地提高系统性能。
3.FIFO: 先进先出队列
FIFO存储器的特点是先进先出, 进出有序, FIFO多用于数据缓冲。 FIFO和DPRAM类似, 具有两个访问端口, 但是FIFO两边的端口并不对等, 某一时刻只能设置为一边作为输入, 一边作为输出。
如果FIFO的区域共有n个字节, 我们只能通过循环n次读取同一个地址才能将该片区域读出, 不能指定偏移地址。 对于有n个数据的FIFO, 当循环读取m次之后, 下一次读时会自动读取到第m+1个数据, 这是由FIFO本身的特性决定的。
三、接口与总线
1.串口
1969年发布的RS-232修改版RS-232C是嵌入式系统中应用最广泛的串行接口, 它为连接DTE(数据终端设备) 与DCE(数据通信设备) 而制定。 RS-232C标准接口有25条线(4条数据线、 11条控制线、 3条定时线、 7条备用和未定义线) , 常用的只有9根, 它们是RTS/CTS(请求发送/清除发送流控制) 、RxD/TxD(数据收发) 、 DSR/DTR(数据终端就绪/数据设置就绪流控制) 、 DCD(数据载波检测, 也称RLSD, 即接收线信号检出) 、 Ringing-RI(振铃指示) 、 SG(信号地) 信号。 RTS/CTS、 RxD/TxD、DSR/DTR等信号的定义如下。
- RTS: 用来表示DTE请求DCE发送数据, 当终端要发送数据时, 使该信号有效。
- CTS: 用来表示DCE准备好接收DTE发来的数据, 是对RTS的响应信号。
- RxD: DTE通过RxD接收从DCE发来的串行数据。
- TxD: DTE通过TxD将串行数据发送到DCE。
- DSR: 有效(ON状态) 表明DCE可以使用。
- DTR: 有效(ON状态) 表明DTE可以使用。
- DCD: 当本地DCE设备收到对方DCE设备送来的载波信号时, 使DCD有效, 通知DTE准备接收,并且由DCE将接收到的载波信号解调为数字信号, 经RxD线送给DTE。
- Ringing-RI: 当调制解调器收到交换台送来的振铃呼叫信号时, 使该信号有效(ON状态) , 通知终端, 已被呼叫。
最简单的RS-232C串口只需要连接RxD、 TxD、 SG这3个信号, 并使用XON/XOFF软件流控。
组成一个RS-232C串口的硬件原理如图2.9所示, 从CPU到连接器依次为CPU、 UART(通用异步接收器发送器, 作用是完成并/串转换) 、CMOS/TTL电平与RS-232C电平转换、 DB9/DB25或自定义连接器。

2.I²C
I²C是内部整合电路的称呼,是一种串行通讯总线,使用多主从架构。
3.SPI
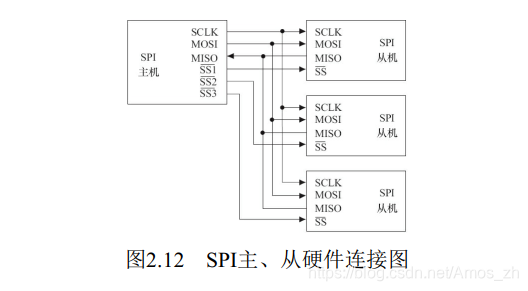
SPI( Serial Peripheral Interface, 串行外设接口) 总线系统是一种同步串行外设接口, 它可以使CPU与各种外围设备以串行方式进行通信以交换信息。 一般主控SoC作为SPI的“主”, 而外设作为SPI的“从”。
SPI接口一般使用4条线: 串行时钟线( SCLK) 、 主机输入/从机输出数据线MISO、 主机输出/从机输入数据线MOSI和低电平有效的从机选择线SS。图2.12演示了1个主机连接3个SPI外设的硬件连接图。
 在SPI总线的传输中, SS信号是低电平有效的, 当我们要与某外设通信的时候, 需要将该外设上的SS线置低。
在SPI总线的传输中, SS信号是低电平有效的, 当我们要与某外设通信的时候, 需要将该外设上的SS线置低。
SPI模块为了和外设进行数据交换, 根据外设工作要求, 其输出串行同步时钟极性( CPOL) 和相位( CPHA) 可以进行配置。 如果CPOL=0, 串行同步时钟的空闲状态为低电平; 如果CPOL=1, 串行同步时钟的空闲状态为高电平。 如果CPHA=0, 在串行同步时钟的第一个跳变沿( 上升或下降) 数据被采样; 如果CPHA=1, 在串行同步时钟的第二个跳变沿( 上升或下降) 数据被采样。
4.USB
USB( 通用串行总线) 是Intel、 Microsoft等厂商为解决计算机外设种类的日益增加与有限的主板插槽和端口之间的矛盾而于1995年提出的, 它具有数据传输率高、 易扩展、 支持即插即用和热插拔的优点,目前已得到广泛应用。
USB 1.1包含全速和低速两种模式, 低速方式的速率为1.5Mbit/s, 支持一些不需要很大数据吞吐量和很高实时性的设备, 如鼠标等。 全速模式为12Mbit/s, 可以外接速率更高的外设。
在USB 2.0中, 增加了一种高速方式, 数据传输率达到480Mbit/s, 半双工, 可以满足更高速外设的需要。
USB 3.0( 也被认为是Super Speed USB) 的最大传输带宽高达5.0Gbit/s( 即640MB/s) , 全双工。
5.以太网接口
6.PCI和PCI-E
PCI(外围部件互连) 是一种局部总线, 作为一种通用的总线接口标准, 它在目前的计算机系统中得到了非常广泛应用。 PCI总线具有如下特点:
- 数据总线为32位, 可扩充到64位。
- 可进行突发(Burst) 模式传输。 突发方式传输是指取得总线控制权后连续进行多个数据的传输。 突发传输时, 只需要给出目的地的首地址, 访问第1个数据后, 第2~n个数据会在首地址的基础上按一定规
则自动寻址和传输。 与突发方式对应的是单周期方式, 它在1个总线周期只传送1个数据。 - 总线操作与处理器—存储器子系统操作并行。
- 采用中央集中式总线仲裁。
- 支持全自动配置、 资源分配, PCI卡内有设备信息寄存器组为系统提供卡的信息, 可实现即插即用。
- PCI总线规范独立于微处理器, 通用性好。
- PCI设备可以完全作为主控设备控制总线
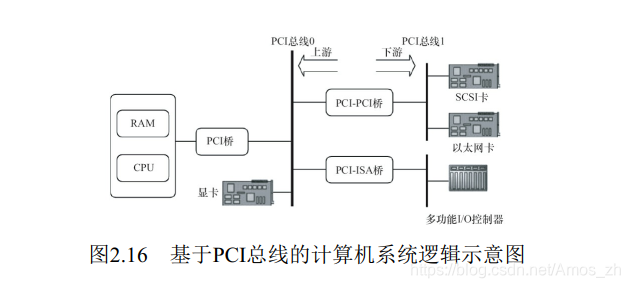
图2.16给出了一个典型的基于PCI总线的计算机系统逻辑示意图, 系统的各个部分通过PCI总线和PCIPCI桥连接在一起。 CPU和RAM通过PCI桥连接到PCI总线0(即主PCI总线) , 而具有PCI接口的显卡则可以直接连接到主PCI总线上。 PCI-PCI桥是一个特殊的PCI设备, 它负责将PCI总线0和PCI总线1(即从PCI主线) 连接在一起, 通常PCI总线1称为PCI-PCI桥的下游(Downstream) , 而PCI总线0则称为PCI-PCI桥的上游(Upstream) 。 为了兼容旧的ISA总线标准, PCI总线还可以通过PCI-ISA桥来连接ISA总线, 从而支持以前的ISA设备。
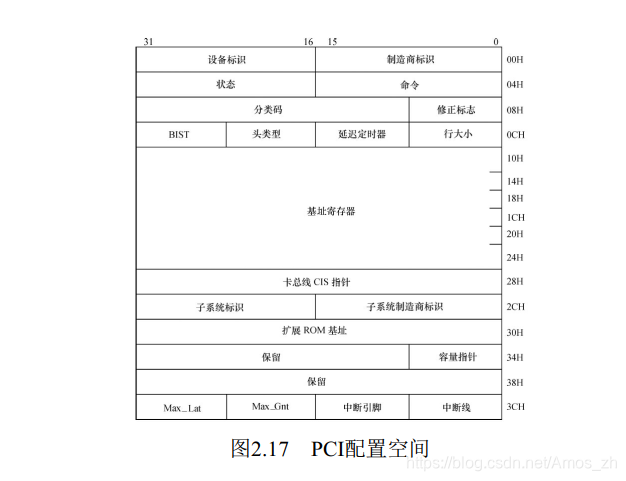
 当PCI卡刚加电时, 卡上配置空间即可以被访问。 PCI配置空间保存着该卡工作时所需的所有信息,如厂家、 卡功能、 资源要求、 处理能力、 功能模块数量、 主控卡能力等。 通过对这个空间信息的读取与编程, 可完成对PCI卡的配置。 如图2.17所示, PCI配置空间共为256字节, 主要包括如下信息:
当PCI卡刚加电时, 卡上配置空间即可以被访问。 PCI配置空间保存着该卡工作时所需的所有信息,如厂家、 卡功能、 资源要求、 处理能力、 功能模块数量、 主控卡能力等。 通过对这个空间信息的读取与编程, 可完成对PCI卡的配置。 如图2.17所示, PCI配置空间共为256字节, 主要包括如下信息:
- 制造商标识(Vendor ID) : 由PCI组织分配给厂家。
- 设备标识(Device ID) : 按产品分类给本卡的编号。
- 分类码(Class Code) : 本卡功能的分类码, 如图卡、 显示卡、 解压卡等。
- 申请存储器空间: PCI卡内有存储器或以存储器编址的寄存器和I/O空间, 为使驱动程序和应用程序能访问它们,
需申请CPU的一段存储区域以进行定位。 配置空间的基地址寄存器用于此目的。 - 申请I/O空间: 配置空间中的基地址寄存器用来进行系统I/O空间的申请。
- 中断资源申请: 配置空间中的中断引脚和中断线用来向系统申请中断资源。
 PCI-E(PCI Express) 是Intel公司提出的新一代的总线接口, PCI Express采用了目前业内流行的点对点串行连接, 比起PCI以及更早的计算机总线的共享并行架构, 每个设备都有自己的专用连接, 采用串行方式传输数据, 不需要向整个总线请求带宽, 并可以把数据传输率提高到一个很高的频率, 达到PCI所不能提供的高带宽。
PCI-E(PCI Express) 是Intel公司提出的新一代的总线接口, PCI Express采用了目前业内流行的点对点串行连接, 比起PCI以及更早的计算机总线的共享并行架构, 每个设备都有自己的专用连接, 采用串行方式传输数据, 不需要向整个总线请求带宽, 并可以把数据传输率提高到一个很高的频率, 达到PCI所不能提供的高带宽。














 776
776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









