






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:新智元 | 编辑:昕朋 David
【导读】AI顶会ICML征稿日在即,关于道德准则的新政策却引来网友不满!规则要求作者不能使用大型语言模型,网友评论区刷屏询问:为什么?
昨天,国际机器学习会议(ICML)发布了2023论文征稿公告。

论文提交日期为1月9日至1月26日。
然而,本次会议中关于「道德准则」的要求却引来了众多不满。
LLM不可控,还是ban掉吧
根据大会的政策,所有作者和程序委员会成员,包括审稿人,应遵循标准的道德准则。
严禁任何形式的抄袭,以及审稿人、领域主席(AC)和高级领域主席(SAC)对特权信息的不道德使用,例如共享此信息,或将其用于评审过程以外的任何其他目的。
禁止包含从大规模语言模型(LLM)(如ChatGPT)生成的文本的论文,除非这些生成的文本作为论文实验分析的一部分呈现。
所有可疑的不道德行为都将由道德委员会进行调查,被发现违反规则的个人可能会面临制裁。今年,我们将收集被发现违反这些标准的个人姓名;如果代表会议、期刊或其他组织的个人出于决策目的要求提供此列表,我们可能会向他们提供此信息。

其中,「禁止使用大型语言模型写论文」一条要求被网友热议。
此消息已发布,网友纷纷在ICML推特下评论:「为啥不能用大型语言模型?」
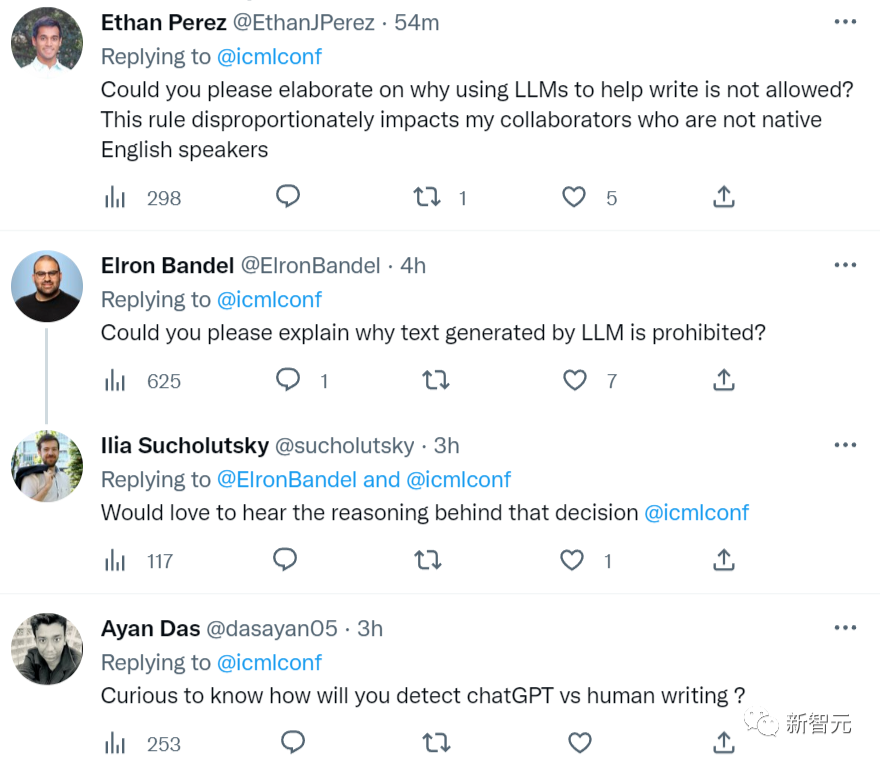
AI论文不能用AI,合理吗
Yann LeCun转发并评价:「大型语言模型不能用,意思是中型和小型语言模型还可以用。」

他解释说:「因为拼写检查应用和文本预测也是语言模型。」
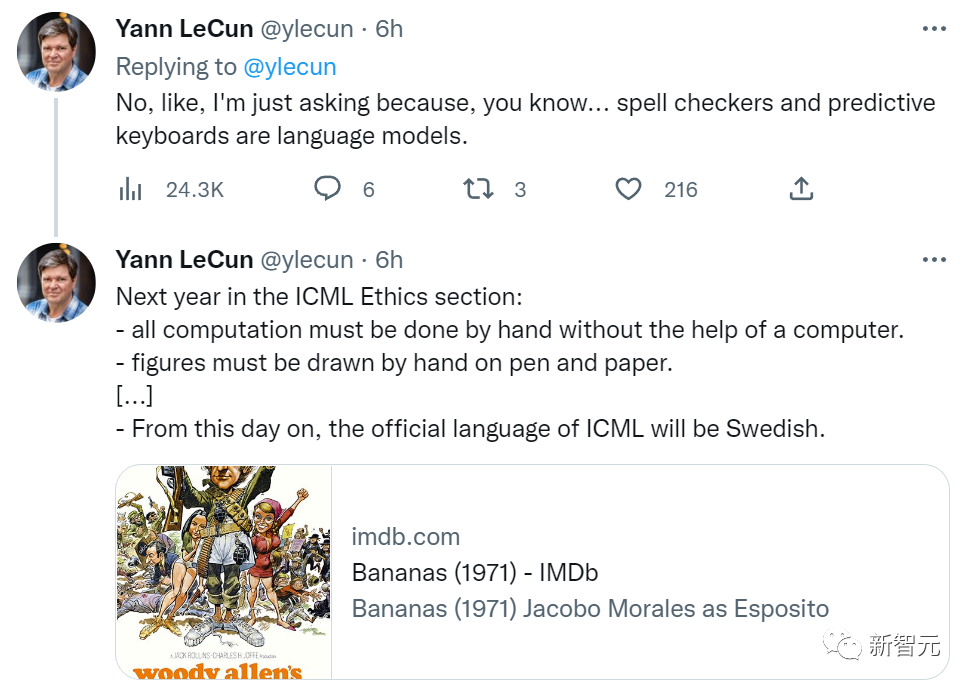
最后,LeCun阴阳道:「明年的ICML道德准则应该变成:研究人员必须徒手完成各种计算,不能借助计算机;各类图形必须用笔和纸手绘;从今天起,ICML的官方语言变为瑞典语(瑞典:?)。」
最后,还不忘转发一部电影《疯了》,总结自己对ICML政策的评价。
在LeCun的帖子下,网友们各显神通,纷纷整活。
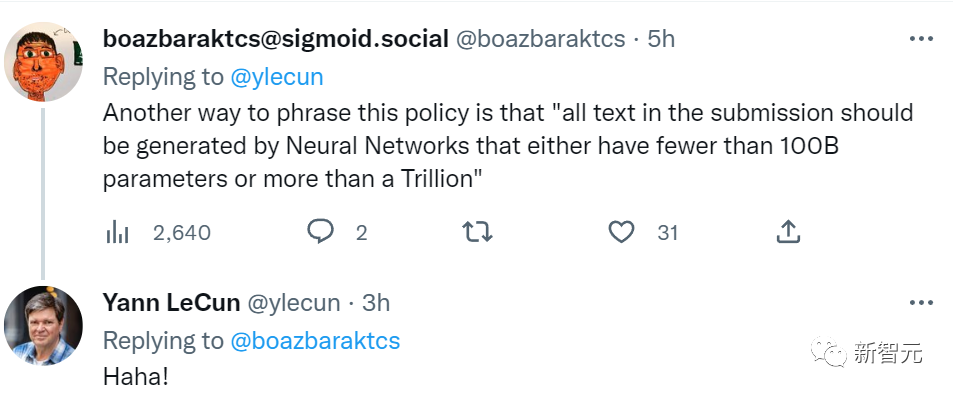
一位网友给ICML提供了新的思路:「另一种表述此策略的方式是‘提交中的所有文本都应由参数小于100B或超过1万亿的神经网络生成’。」
还有人假装是ICML的评审,给ChatGPT打广告:「作为ICML和其他会议的评审 ,我很欣赏作者们使用ChatGP等工具润色文章。这会让他们的论文更加清晰易读。(该帖已经过ChatGPT的修改)」

对于该规则,MIT教授Erik Brynjolfsson简单概括:「这是场必败之仗。」
除了整活玩梗,也有人认真表达了自己对ICML规定的想法。
AAAI前主席Thomas Dietterich说:「这个规定很怪,对于一个人工智能会议来说更是如此。我们应该欢迎所有为科学技术做出贡献的文章,不论作者是否接受了AI的辅助。」
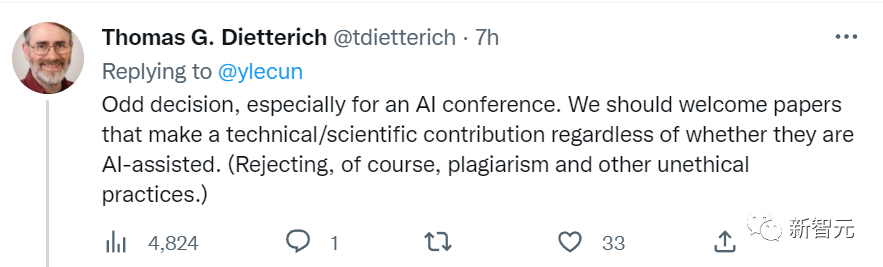
也有人给ICML改进建议:
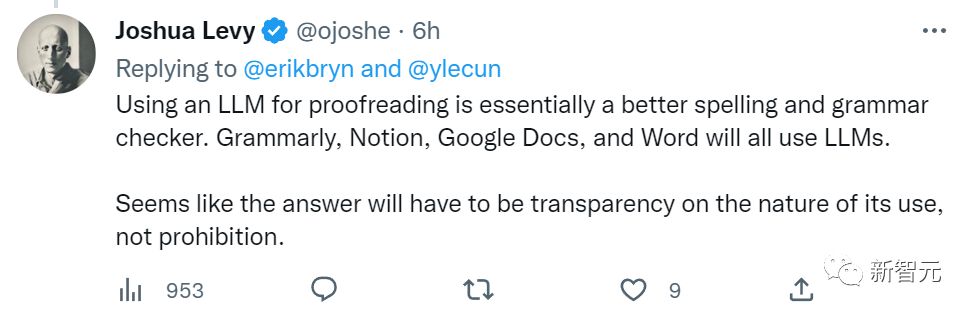
使用大型语言模型来进行审校对于改善拼写和语法很有裨益。Grammarly,Notion,Google Docs甚至Word都会用到大型语言模型。
看起来,解决方法是解释清楚使用大型语言模型的原因和用途,而非一味禁止。
原来不止我用Grammarly检查拼写和语法(doge)。
当然,也有网友对此表示了理解,认为此举是为了保护评审的权威。
网友Anurag Ghosh评论道:「我认为ICML的要求是为了防止那些看似正确的论文发表。例如机器学习领域发表的5篇编造/AI生成的论文。这会暴露同行评审的缺陷。」

也有人认为,「大型语言模型只是工具,如果它们就可以生成质量更高的论文,那又如何?这些研究的主要贡献不来自于大型语言模型,而来自那些研究人员。难道我们要禁止研究人员接受任何形式的帮助,比如谷歌搜索,或是不能和没有利害关系的人谈论此事吗?」
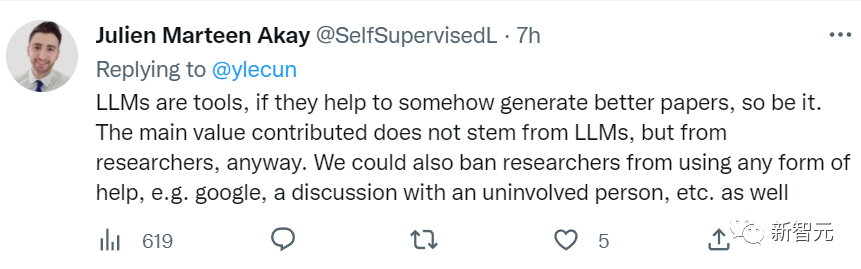
由于最近几年大语言模型的热度始终不减,这次ICML提出的禁令引发的学者和网友热烈讨论,想必还会持续一段时间。
不过目前看下来,有一个问题似乎还没人讨论,如何判断一篇文章的片段是不是大语言模型生成的?如何验证,靠查重吗?毕竟真要是机器模型生成的文章,谁也不会特意标注一个「本文是大语言模型自动生成的」,对吧?
更何况,研究论文这种逻辑清晰、结构明确、语言风格高度模式化的文章,简直就是大语言模型发挥的最佳场所,即使是生成的原文略显生硬,但如果是当个辅助工具来用,怕是很难辨别,也就难有明确的标准来实施这个禁令。
这样看来,这次ICML的审稿人肩上的担子,怕是又要重了不少了。
参考资料:
https://icml.cc/Conferences/2023/CallForPapers
https://twitter.com/ylecun/status/1610367976016064513
CVPR/ECCV 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:ECCV2022,即可下载ECCV 2022论文和代码开源的论文合集后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer222,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看
















 1411
1411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









