






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:王云鹤 | 源:知乎(已授权转载)
https://zhuanlan.zhihu.com/p/632076967NTIRE (New Trends in image Restoration and Enhancement) 是图像复原与增强领域的顶级研讨会,由苏黎世联邦理工大学在历年的CVPR大会上举办,并同步开展相应的学术竞赛,以总结该领域的最新进展并探讨未来的研究新趋势。到目前为止,已经连续举办了八届。在其中的图像去噪挑战赛中,全球共有234位选手参赛,17支队伍提交了最终成绩,来自华为诺亚-终端联合团队以显著优势斩获该赛道的冠军,下面将简要阐述一下我们的解决方案。
图像去噪是计算机视觉领域中最基础的一个研究课题,其目标是去除图像上的噪声信息并同时尽可能多地恢复细节特征。NTIRE2023的图像去噪挑战赛基于DIV2K和LSDIR数据集,通过向高清图像添加高斯白噪声(sigma=50)以模拟真实的噪声图像。比赛要求参赛者提出一种网络设计/解决方案,能够产生高质量的结果,最终以测试集上的PSNR结果排序。

随着transformer在计算机视觉领域的应用,我们发现目前性能最高的图像复原模型均是基于transformer来构建的,如IPT[1]、SwinIR[2]、Restormer[3]和GRL[4]。然而通过这些模型结构的研究,我们发现它们均不能高效且准确地构建全局和局部像素的依赖关系,这对于去除噪声并恢复图像细节尤为重要。
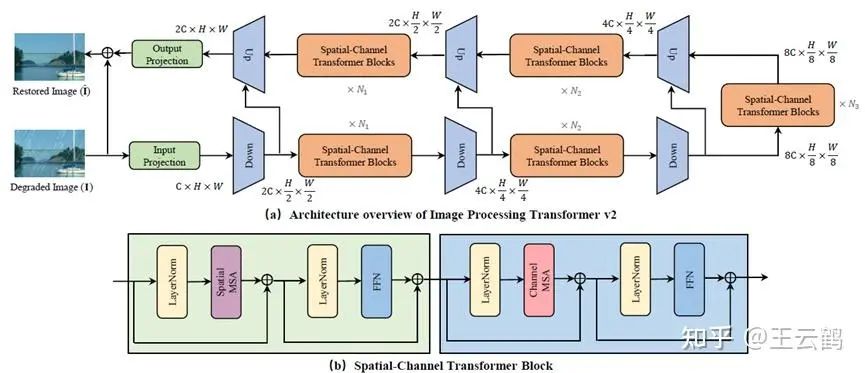
为了解决这个问题,我们提出了一种高效且新颖的混合自注意力模型IPT-V2,旨在以一个较低的计算复杂度同步构建准确的全局和局部像素的依赖关系。整体的网络架构如上图所示,IPT-V2是一个U型编码-解码的网络结构,具有三次下采样和上采样。基础模块是spatial-channel transformer block,在空间维度和通道维度同时构建自注意力机制。为了更好地恢复出高清图像,我们在局部和全局范围内对channel self-attention和spatial self-attention进行了增强,整个模型的计算复杂度与Restormer接近,且远低于IPT、SwinIR和GRL。
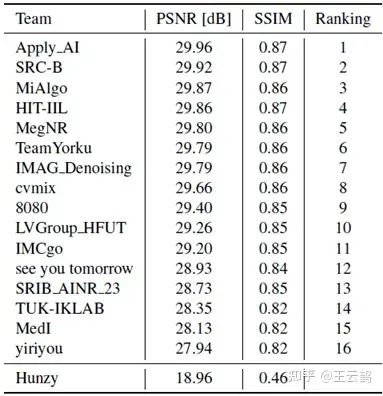
在训练阶段,IPT-V2仅使用DIV2K和LSDIR数据集,采用MSE和Sobel loss进行训练,在赛方的测试集上达到了29.96 dB的准确度,最终结果的排名如上,本方案以显著优势获得该赛道的冠军,超越了三星、小米、旷视等友商,充分证明了IPT-V2的优势。
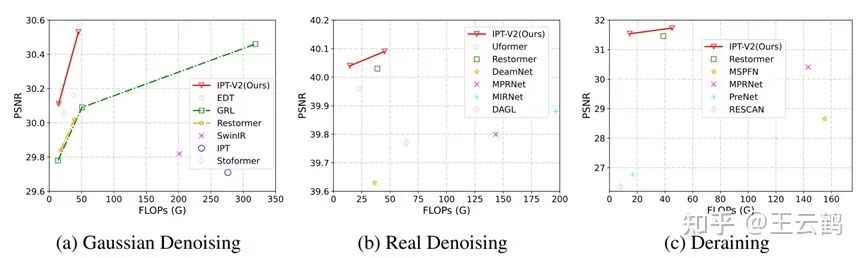
除了在NTIRE比赛的结果,IPT-V2还在公开数据集上进行了验证,结果显示,IPT-V2在去噪、去雨等多项底层视觉任务上均超越了现有的SOTA方案,取得了更优的FLOPS-PNSR曲线。

图中是一些视觉效果的对比,可以看到,IPT-V2不仅在指标上领先,在视觉效果上也取得了优势。
方案的具体细节和内容会在论文公开之后进行详细解读,敬请期待。
【1】 Chen, Hanting, et al. "Pre-trained image processing transformer." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
【2】 Liang, Jingyun, et al. "Swinir: Image restoration using swin transformer." Proceedings of the IEEE/CVF international conference on computer vision. 2021.
【3】 Zamir, Syed Waqas, et al. "Restormer: Efficient transformer for high-resolution image restoration." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
【4】 Li, Yawei, et al. "Efficient and Explicit Modelling of Image Hierarchies for Image Restoration." arXiv preprint arXiv:2303.00748 (2023).
最新CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
去一切和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-去一切或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如去一切和Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()

















 1157
1157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









