






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:新智元 | 编辑:桃子 好困
【导读】今天,OpenAI正式开放GPT-3.5微调API,GPT-4版本也即将推出。这意味着,继插件「APP Store」大爆发后,所有人皆可以打造个性化的专属「类ChatGPT应用」。
终于来了!
刚刚,OpenAI正式宣布,所有开发者都可以对GPT-3.5 Turbo进行微调。

初步结果表明,微调后的GPT-3.5 Turbo,在具体任务中,性能与GPT-4实力相当,甚至反超GPT-4。

最让人兴奋的是,「地表最强」的GPT-4微调版本,也将在几个月后正式上线。
这意味着,任何人可以根据需要,用「专有数据」对模型微调,标志着OpenAI开启了AI商业应用的新纪元。
英伟达高级科学家Jim Fan称,OpenAI发布了自「插件应用商店」以来最大的产品更新:GPT-3.5的微调API。这将是有史以来最大的LoRA云服务。预计将有一大堆新应用从各行各业涌现出来。

提示量大减90%
自GPT-3.5 Turbo发布以来,开发者和企业一直在寻求定制化的模型,以便为用户创建独特和差异化的体验。
不负等待,现在,开发者终于可以进行监督式微调,让该模型更好地满足自己的使用需求。
OpenAI表示,在私人测试版中,客户已经通过微调,显著提升了模型在常见案例中的性能,具体包括:
- 提高可控性
AI模型面临的经典挑战之一,便是精确地遵循指令。而微调便可以让模型做到这一点,比如输出更加简洁,或始终用特定的语言回复。
举个栗子,开发者可以通过微调确保要求模型,当用户在使用德语时,模型总是以德语回应。
- 可靠的输出格式
微调提高了模型一致格式化响应的能力,这对于需要特定响应格式的APP非常重要,比如代码补全或编写API调用。
想象一下,开发者可以通过微调将用户提示可靠地转化为高质量的JSON片段,这样,就能与自己的系统一起使用,让任务变得更加流畅。
- 自定义语调
微调可以优化模型,输出可以反应特定语调,从而更好地代表适应企业品牌的声音。
不同的品牌对外发出的声音是不一样的,从活跃创新初创公司到较为保守的企业,都可以通过模型微调让语调与对外形象保持一致。
- 更短的提示,相同的性能
GPT-3.5-Turbo微调可以处理多达4k个token,是之前微调模型的2倍。
早期测试者通过指令微调模型本身,将提示大小减少了高达90%,从而加快了每次API调用,并降低了成本。

值得注意的是,当微调与提示工程、信息检索和函数调用等其他技术相结合时,会获得最为强大的能力。
最后OpenAI表示,支持使用函数调用和gpt-3.5-turbo-16k的微调功能,也将在今年秋季推出。
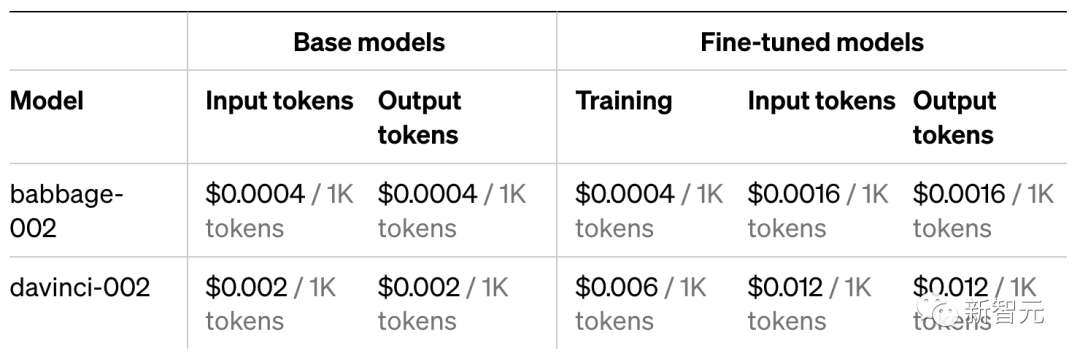
价格x8
微调GPT-3.5的成本可以分为两部分:初始训练成本和使用成本。
训练:0.008美元/1K token
使用输入:0.012美元/1K token
使用输出:0.016美元/1K token
例如,一个gpt-3.5-turbo微调任务的训练文件为100,000个token(约75,000个单词),那么训练3个epoch的预期成本为2.40美元。

从使用的价格上来看,微调后的GPT-3.5是原始版本的8倍。

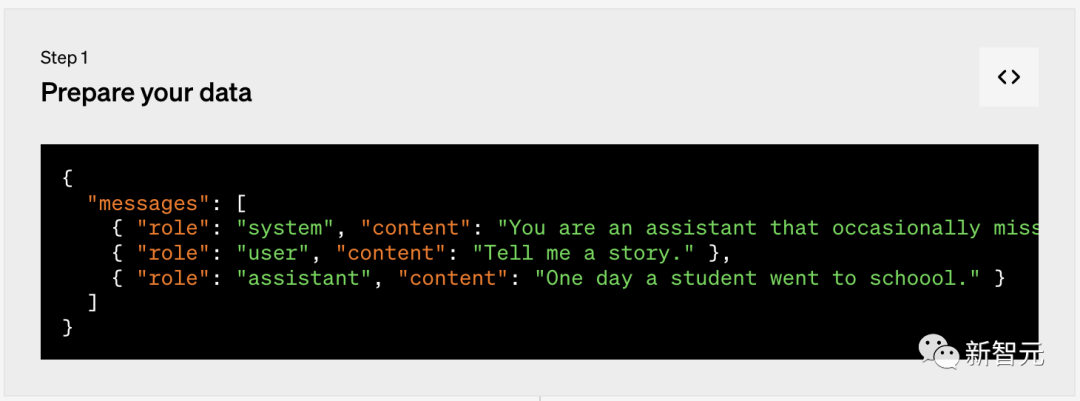
四步轻松搞定
第一步:准备数据
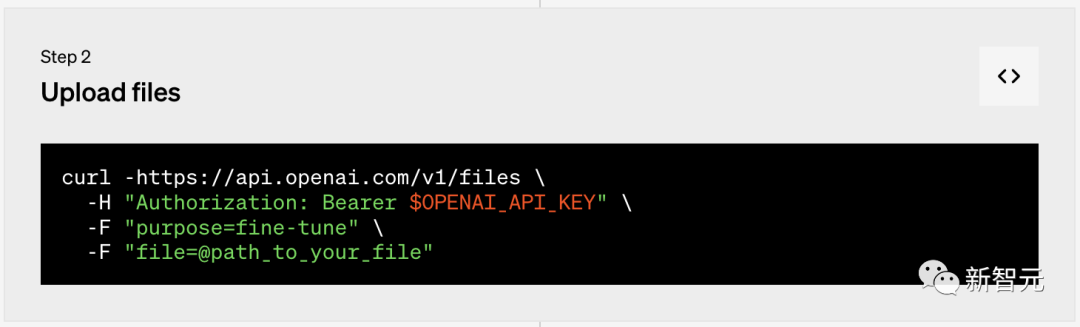
第二步:上传文件
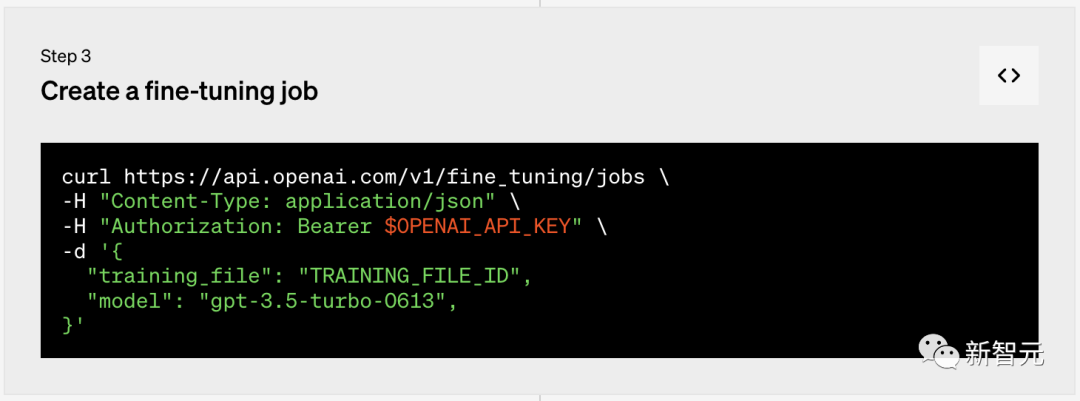
第三步:创建微调任务
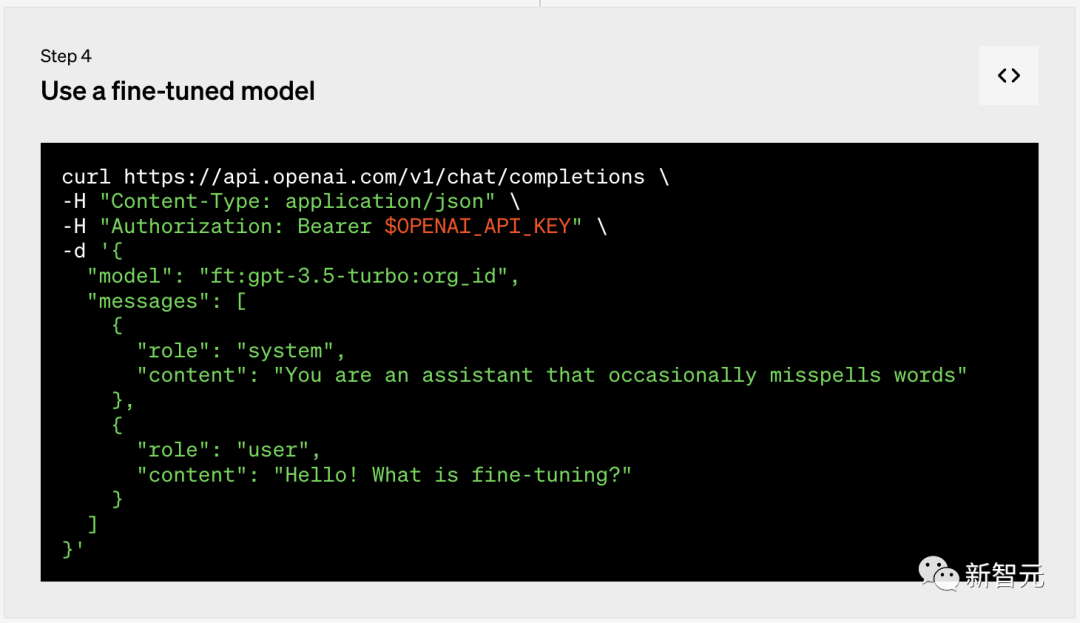
第四步:使用微调模型
GPT-3模型更新
7月,OpenAI曾宣布GPT-3基础模型(ada、babbage、curie和davinci)将于2024年1月4日关闭。
同在今天,OpenAI再次更新GPT-3模型,并提供了babbage-002和davinci-002作为以上模型替代品,可以作为基础模型或微调模型来使用。
客户也可以通过查询Completions API来访问这些模型。
另外,这些模型使用新的API端口/v1/fine_tuning/jobs进行微调。
该端口取代了/v1/fine-tunes旧端口(2024年1月4日关闭),提供了分页和更多可扩展性,以支持微调API的未来发展。
网友开启新世界
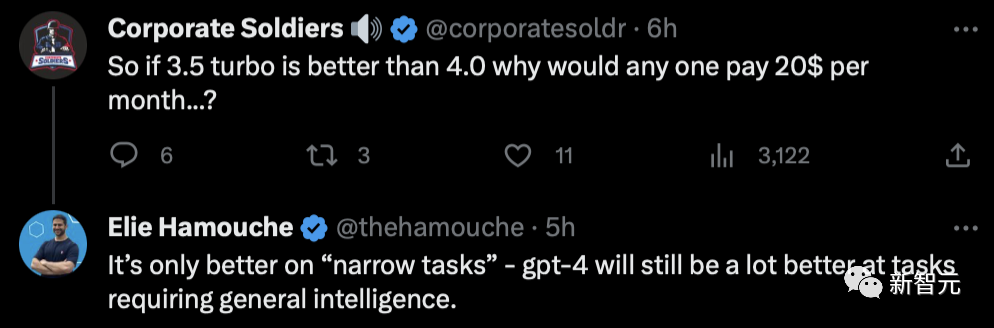
众多网友已经基于GPT-3.5 Turbo微调功能,开始创造新世界了。
刚刚在基于Marv示例的合成样本数据上对GPT-3.5进行了微调,Marv太搞笑了。

用户:我怎样才能交到女朋友?
助手:嘿Siri,给我找个女朋友。

毋庸置疑,这将彻底改变游戏规则,大大减少我们的API成本!

不过,也有网友表示十分疑惑,如果GPT-3.5 Turbo比GPT-4还强,那为什么还要每月支付20美元???
对此其他网友解释道,它只是在「特定任务」上更胜一筹,在通用型任务上依然还是GPT-4的主场。
官方微调指南
如何去微调GPT-3.5 Turbo,官方已经给出了教程。

地址:https://platform.openai.com/docs/guides/fine-tuning
首先,OpenAI介绍了通过微调,你可以API可用的模型中获得更多信息:
1. 比提示质量更高的结果
2. 能够就提示中无法容纳的更多示例进行训练
3. 提示更简洁,节省token使用
4. 降低延迟请求
GPT模型已经在大量文本上进行了预训练。
为了有效使用模型,OpenAI在提示中加入指令,有时还包括几个示例。通过演示,来展示模型如何执行任务通常被称为「少样本学习」。
微调可以通过训练比提示中更多的示例,来改进少样本学习,能够让模型在大量任务上获得更好的结果。
一旦微调模型,你就不需要在提示符中提供更多的示例。这样,既节省了成本,又降低了延迟的请求。
在高层次上,微调包含以下步骤:
1. 准备和上传训练数据
2. 训练一个新的微调模型
3. 使用你的微调模型
目前,微调可用于以下模型:
- gpt-3.5-turbo-0613(推荐)
- babbage-002
- davinci-002
何时需要微调
微调GPT模型可以使其更适合特定APP,但这需要投入大量的时间和精力。
OpenAI建议,首先尝试通过提示工程、提示链(将复杂任务分解为多个提示),以及函数调用,可以获得良好的结果,主要原因是:
- 有许多任务,GPT模型最初可能表现不佳,但有了更好的提示,便可以获得更好的结果,并且可能不需要微调。
- 迭代提示等其他策略,比使用微调迭代具有更快的反馈循环,而微调需要创建数据集,并且训练模型。
- 在仍需要微调的情况下,初始提示工程任务不会白费。OpenAI通常在微调数据中使用优秀的提示(或将提示链/工具使用与微调相结合),从而看到最佳结果。
前段时间,OpenAI发布「GPT最佳实践指南」中,提供一些有关提示有效的策略,无需微调即可获得更好的性能。

https://platform.openai.com/docs/guides/gpt-best-practices
常见用例
微调可以改善结果的一些常见用例:
- 设置风格、语调、格式或其他定性方面
- 提高生产所需输出的可靠性
- 纠正不按复杂提示操作的情况
- 以特定方式处理许多边缘情况
- 执行一项难以用提示表达的新技能或任务
在接下来的部分中,OpenAI将探讨如何设置用于微调的数据,以及微调后提高基线模型性能的各种示例。
微调有效的另一个场景是,在不牺牲质量的情况下通过替换GPT-4,或使用更短的提示来降低成本和/或延迟。
如果可以用GPT-4取得良好的结果,那么通过对GPT-4完成进行微调(可能使用更短的指令提示),而微调gpt-3.5-turbo后模型也能达到类似的效果。
准备数据集
当你确定微调是正确的解决方案,将需要准备训练模型的数据。
这里,你需要创建一组多样化的演示对话,这些对话应与你在推理时要求模型响应的对话相似。
数据集中的每个示例都应该是,与Chat completions API相同的对话,具体来说,就是一个消息列表,每个消息都有角色、内容和可选名称。
至少一些训练示例,应该直接针对提示模型行为不符合预期的情况,并且数据中提供的助手消息,应该是你希望模型提供的理想响应。
- 示例格式
在这个例子中,目标是创建一个偶尔给出讽刺回应的聊天机器人。
对此,OpenAI为数据集创建了3个训练示例(对话):
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}微调gpt-3.5-turbo需要会话聊天格式。对于babbage-002和davinci-002,你可以按照用于旧版微调的提示完成配对格式,如下:
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}- 编写提示
建议在微调之前,用你认为对模型最有效的指令和提示,纳入到每个训练示例中。
这样做可以获得最佳和最普遍的结果,尤其是在训练示例相对较少(不足100个)的情况下。
如果你想缩短每个示例中重复出现的指令或提示,以节省成本,请记住,模型的行为很可能包含这些指令,很难让模型在推理时忽略这些「内置」指令。
可能需要更多的训练示例才能获得良好的结果,因为模型必须完全通过演示学习,而无需指令指导。
- 示例数量
要微调模型,你需要提供至少10个示例。
通常会看到,使用gpt-3.5-turbo对50-100个训练示例进行微调,有着明显改进。根据具体使用情况,同样的的示例效果不一。
OpenAI建议,从50个精心制作示例开始,看看模型在微调后是否显示出改进的迹象。
在某些情况下,这可能就足够了,但即使模型尚未达到输出质量,明确的改进也是一个好迹象,表明提供更多数据将继续改进模型。
如果没有改进,则表明你可能需要重新考虑如何为模型设置任务,或者在扩展到有限的示例集之前,重新调整数据结构。
- 拆分训练和测试
收集初始数据集后,建议将其拆分为训练和测试两个部分。
当提交包含训练和测试文件的微调时,OpenAI将在训练过程中提供两者的统计数据。
这些统计数据将是模型改进程度的初始信号。
此外,通过在测试集上生成样本,尽早构建测试集将有助于确保你能够在训练后评估模型。
- token限制
每个训练示例限制为4096个token。
训练时,长度超过这一限制,将被截断为4096个token。
因此,要确保整个训练示例适合上下文,请检查消息内容中的总token数是否低于4,000个。每个文件当前限制为50 MB。
- 估算成本
为了估算微调成本,主要还是参考官方定价页面,了解每1k token成本的详细信息。
在3个epoch内训练了100,000个token的训练文件,预期成本约为2.4美元。
- 检查数据格式
编译完数据集后,在创建微调之前,检查数据格式非常重要。
为此,OpenAI创建了一个简单的Python脚本,你可以使用它来查找潜在错误、查看token计数并估计微调的成本。
数据格式化脚本:
# We start by importing the required packages
import json
import os
import tiktoken
import numpy as np
from collections import defaultdict
# Next, we specify the data path and open the JSONL file
data_path = "<YOUR_JSON_FILE_HERE>"
# Load dataset
with open(data_path) as f:
dataset = [json.loads(line) for line in f]
# We can inspect the data quickly by checking the number of examples and the first item
# Initial dataset stats
print("Num examples:", len(dataset))
print("First example:")
for message in dataset[0]["messages"]:
print(message)
# Now that we have a sense of the data, we need to go through all the different examples and check to make sure the formatting is correct and matches the Chat completions message structure
# Format error checks
format_errors = defaultdict(int)
for ex in dataset:
if not isinstance(ex, dict):
format_errors["data_type"] += 1
continue
messages = ex.get("messages", None)
if not messages:
format_errors["missing_messages_list"] += 1
continue
for message in messages:
if "role" not in message or "content" not in message:
format_errors["message_missing_key"] += 1
if any(k not in ("role", "content", "name") for k in message):
format_errors["message_unrecognized_key"] += 1
if message.get("role", None) not in ("system", "user", "assistant"):
format_errors["unrecognized_role"] += 1
content = message.get("content", None)
if not content or not isinstance(content, str):
format_errors["missing_content"] += 1
if not any(message.get("role", None) == "assistant" for message in messages):
format_errors["example_missing_assistant_message"] += 1
if format_errors:
print("Found errors:")
for k, v in format_errors.items():
print(f"{k}: {v}")
else:
print("No errors found")
# Beyond the structure of the message, we also need to ensure that the length does not exceed the 4096 token limit.
# Token counting functions
encoding = tiktoken.get_encoding("cl100k_base")
# not exact!
# simplified from https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
def num_tokens_from_messages(messages, tokens_per_message=3, tokens_per_name=1):
num_tokens = 0
for message in messages:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name":
num_tokens += tokens_per_name
num_tokens += 3
return num_tokens
def num_assistant_tokens_from_messages(messages):
num_tokens = 0
for message in messages:
if message["role"] == "assistant":
num_tokens += len(encoding.encode(message["content"]))
return num_tokens
def print_distribution(values, name):
print(f"\n#### Distribution of {name}:")
print(f"min / max: {min(values)}, {max(values)}")
print(f"mean / median: {np.mean(values)}, {np.median(values)}")
print(f"p5 / p95: {np.quantile(values, 0.1)}, {np.quantile(values, 0.9)}")
# Last, we can look at the results of the different formatting operations before proceeding with creating a fine-tuning job:
# Warnings and tokens counts
n_missing_system = 0
n_missing_user = 0
n_messages = []
convo_lens = []
assistant_message_lens = []
for ex in dataset:
messages = ex["messages"]
if not any(message["role"] == "system" for message in messages):
n_missing_system += 1
if not any(message["role"] == "user" for message in messages):
n_missing_user += 1
n_messages.append(len(messages))
convo_lens.append(num_tokens_from_messages(messages))
assistant_message_lens.append(num_assistant_tokens_from_messages(messages))
print("Num examples missing system message:", n_missing_system)
print("Num examples missing user message:", n_missing_user)
print_distribution(n_messages, "num_messages_per_example")
print_distribution(convo_lens, "num_total_tokens_per_example")
print_distribution(assistant_message_lens, "num_assistant_tokens_per_example")
n_too_long = sum(l > 4096 for l in convo_lens)
print(f"\n{n_too_long} examples may be over the 4096 token limit, they will be truncated during fine-tuning")
# Pricing and default n_epochs estimate
MAX_TOKENS_PER_EXAMPLE = 4096
MIN_TARGET_EXAMPLES = 100
MAX_TARGET_EXAMPLES = 25000
TARGET_EPOCHS = 3
MIN_EPOCHS = 1
MAX_EPOCHS = 25
n_epochs = TARGET_EPOCHS
n_train_examples = len(dataset)
if n_train_examples * TARGET_EPOCHS < MIN_TARGET_EXAMPLES:
n_epochs = min(MAX_EPOCHS, MIN_TARGET_EXAMPLES // n_train_examples)
elif n_train_examples * TARGET_EPOCHS > MAX_TARGET_EXAMPLES:
n_epochs = max(MIN_EPOCHS, MAX_TARGET_EXAMPLES // n_train_examples)
n_billing_tokens_in_dataset = sum(min(MAX_TOKENS_PER_EXAMPLE, length) for length in convo_lens)
print(f"Dataset has ~{n_billing_tokens_in_dataset} tokens that will be charged for during training")
print(f"By default, you'll train for {n_epochs} epochs on this dataset")
print(f"By default, you'll be charged for ~{n_epochs * n_billing_tokens_in_dataset} tokens")
print("See pricing page to estimate total costs")验证数据后,需要上传文件才能与微调一起使用:
openai.File.create(
file=open("mydata.jsonl", "rb"),
purpose='fine-tune'
)创建微调模型
在确保数据集的数量和结构正确并上传文件后,下一步是创建微调模型。
使用OpenAI SDK开始微调:
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.FineTuningJob.create(training_file="file-abc123", model="gpt-3.5-turbo")其中,model是初始的模型的名称(gpt-3.5-turbo、babbage-002或davinci-002)。你可以使用后缀参数自定义微调模型的名称。
开始微调后,可能需要一些时间才能完成。
根据模型和数据集的大小,训练模型可能需要几分钟,或几个小时。模型训练完成后,创建微调模型的用户将收到一封电子邮件确认。
除了创建微调模型之外,你还可以列出现有任务、检索任务状态或取消任务。
# List 10 fine-tuning jobs
openai.FineTuningJob.list(limit=10)
# Retrieve the state of a fine-tune
openai.FineTuningJob.retrieve("ft-abc123")
# Cancel a job
openai.FineTuningJob.cancel("ft-abc123")
# List up to 10 events from a fine-tuning job
openai.FineTuningJob.list_events(id="ft-abc123", limit=10)
# Delete a fine-tuned model (must be an owner of the org the model was created in)
import openai
openai.Model.delete("ft-abc123")使用微调模型
任务成功后,在检索工作详细信息时,你将看到fine_tuned_model字段填充了模型的名称。
你现在可以将此模型指定为Chat完成(用于gpt-3.5-turbo)或旧Completions API(用于babbage-002和davinci-002)中的参数,并使用Playground向其发出请求。
所有步骤完成后,模型可以立即用于推理。
在某些情况下,你的模型可能需要几分钟才能准备好处理请求。如果对模型的请求超时或找不到模型名称,很可能是因为模型仍在加载中。如果发生这种情况,请在几分钟后重试。
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
completion = openai.ChatCompletion.create(
model="ft:gpt-3.5-turbo:my-org:custom_suffix:id",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)微调示例
- 风格和语调
在这个例子中,将探讨如何建立一个微调模型,让模型遵循特定的风格和语调指导,而不是仅仅依靠提示。
首先,创建一组示例对话,显示模型应该是什么,如下这个例子是「拼写错误的单词」。
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}如果你想效仿并自己创建一个微调模型,至少需要10个示例。
在获得可能改进模型的数据后,下一步是检查数据是否满足所有格式要求。
在对数据进行了格式化和验证,最后的训练步骤是开始创建微调模型。你可以通过OpenAI CLI或SDK之一执行此操作,如下所示:
openai.File.create(file=open("marv.jsonl", "rb"), purpose='fine-tune')
openai.FineTuningJob.create(training_file="file-abc123", model="gpt-3.5-turbo")一旦训练完成后,你就可以使用自己的微调模型。
- 结构化输出
另一种与微调非常有效的用例是让模型提供结构化信息,如下例子是关于「体育新闻标题」:
{"messages": [{"role": "system", "content": "Given a sports headline, provide the following fields in a JSON dict, where applicable: "player" (full name)", "team", "sport", and "gender".},{"role": "user", "content": "Sources: Colts grant RB Taylor OK to seek trade"},
{"role": "assistant", "content": "{"player": "Jonathan Taylor", "team": "Colts", "sport": "football", "gender": "male" }"},]}
{"messages": [{"role": "system", "content": "Given a sports headline, provide the following fields in a JSON dict, where applicable: "player" (full name)", "team", "sport", and "gender".},{"role": "user", "content": "OSU 'split down middle' on starting QB battle"},
{"role": "assistant", "content": "{"player": null, "team": "OSU", "sport": "football", "gender": null }"},]}接下来的步骤,如上一个例子:
openai.File.create(file=open("sports-context.jsonl", "rb"), purpose='fine-tune')
openai.FineTuningJob.create(training_file="file-abc123", model="gpt-3.5-turbo")训练完成后,你可以使用微调模型,并提出一下请求:
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
completion = openai.ChatCompletion.create(
model="ft:gpt-3.5-turbo:my-org:custom_suffix:id",
messages=[
{"role": "system", "content": "Given a sports headline, provide the following fields in a JSON dict, where applicable: player (full name), team, sport, and gender"},
{"role": "user", "content": "Richardson wins 100m at worlds to cap comeback"}
]
)
print(completion.choices[0].message)根据格式化的训练数据,响应应如下所示:
{"player": "Sha'Carri Richardson", "team": null", "sport": "track and field", "gender": "female"}除此之外,在GitHub上斩获了近47k星的「OpenAI Cookbook」(OpenAI API的使用示例和指南),也于第一时间整理出了一份详尽的微调教程。
项目地址:https://github.com/openai/openai-cookbook/blob/main/examples/How_to_finetune_chat_models.ipynb
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()














 494
494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









