






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer5555,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!


最近的研究表明CLIP、BLIP等一众大型预训练视觉语言模型 (VLMs) 十分容易被对抗样本(adversarial examples)诱导从而产生错误的、有害的输出,例如反社会的言论和钓鱼网站链接。这一发现引起了人们对于那些部署在现实世界中的视觉语言模型的安全性和可信赖程度的担忧。为了解决这一问题,本文从提示词(prompt)这一独特的角度研究大型预训练视觉语言模型的对抗鲁棒性(adversarial robustness)。本文首先揭示了对抗攻击(adversarial attacks)和防御(adversarial defenses)的有效性对于其所使用的提示词十分敏感。受此启发,本文提出一种新的对抗防御机制,Adversarial Prompt Tuning (APT)。APT通过优化提示词的方式在不调整原模型参数的情况下提高模型的对抗鲁棒性。在ImageNet等15个数据集上测试的结果表明,APT在仅依赖极少参数(parameter-efficient)的情况下展现出了极佳的分部内(In-Distribution)和分布外(Out-of-Distribution)泛化能力以及零样本(Zero-shot)和少样本(Few-shot)学习能力。令人印象深刻的是,在提示词中仅仅加入一个APT优化后的词(只有512个参数)就能极大得提高模型的表现:如图1,在11个数据集上,相较于CLIP的默认提示词工程baseline,APT平均提高了准确率(accuracy)+13% 和对抗鲁棒性(adversarial robustness)+8.5%。论文已被CVPR2024录用,VALSE2024墙报展示。
论文地址:https://arxiv.org/abs/2403.01849
联系方式:李淋(https://treelli.github.io/)
代码地址:https://github.com/TreeLLi/APT
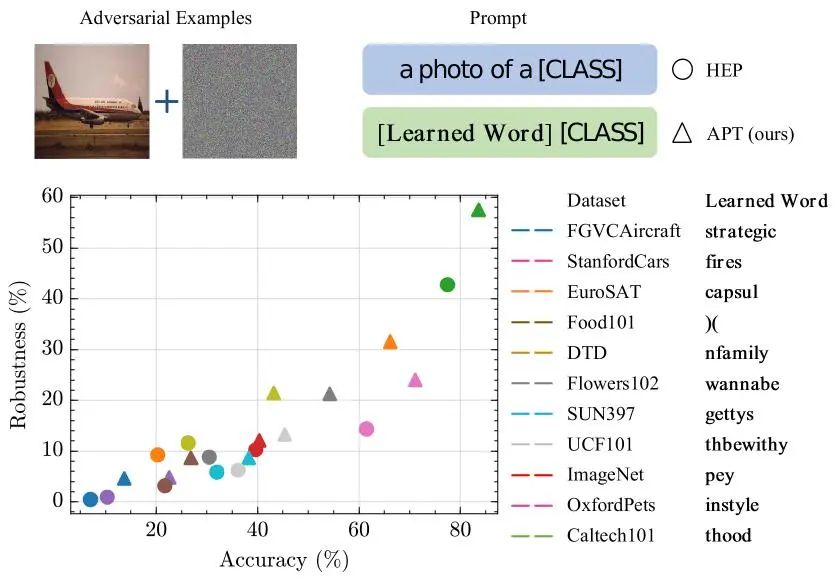
Figure 1 添加APT优化“词”前后模型在11个数据集上准确性和鲁棒性的变化。虚线箭头指示性能提升幅度。“词”在这里指的是一个可学习的向量。图中的最后一列展示了它在各个数据集上的近似语义解释。
Adversarial Example: A Critical Vulnerability in DNNs
对抗样本是指原始样本加上人为生成的、人类不可见的噪音,从而误导或欺骗模型,使其产生错误的输出。

Figure 2对抗样本示例,左图为原始图片,中间为对抗噪声,右图为对抗样本。
在生成模型时代,对抗样本可能导致更大的危害。如下图所示,左图是原始样本,右图是对抗样本,对抗样本诱导模型生成了一个指向恶意网站的链接。如果用户轻信了模型的输出并点击了这个链接,或者不小心误触了它,他将被引导到一个预先设定好的恶意网站如钓鱼网站,进而导致个人的经济损失。

Figure 3左图为原始图片,右图为对抗样本,图片下方为模型输出的图片描述。
Research Problem and Contribution
本文从Text Prompt角度切入研究以视觉语言模型为代表的多模态模型的对抗鲁棒性。选择text prompt作为切入点的原因有二:其一,Text Prompt是视觉语言模型相对于纯视觉模型的一个独特组成部分;其二,已有的工作主要从模型参数(model weights)的角度研究对抗鲁棒性,关于Text Prompt在对抗攻防领域的应用与研究还很少。本文旨在回答两个主要问题:
1. Text Prompt如何影响对抗攻击和防御
2. 是否能够通过text prompting的方法来提高模型的对抗鲁棒性。
Background
CLIP
本研究主要选择了CLIP作为多模态语言模型的代表。CLIP由一个图像编码器(Image Encoder)和一个文本编码器(Text Encoder)两部分组成。在预训练阶段,损失函数被设计为最大化图像和文本之间的特征对齐。在推理阶段,CLIP使用了数据集的类别文本标签来生成一组Text Prompt,然后将它们输入到Text Encoder中以获取它们的文本特征。接着,通过计算给定图像特征与每个类别的文本特征之间的相似性,选择相似性最大的文本特征对应的类别标签作为输出的分类结果。
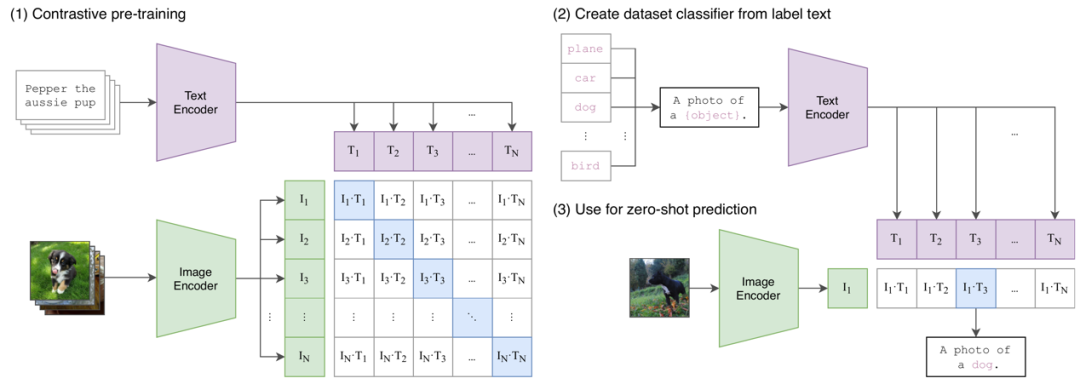
Figure 4 CLIP模型训练及推理流程示意图。
Text Prompt
本研究中,“Text Prompt”指的是Text Encoder的输入。为了实现图像分类的能力,CLIP主要使用的默认提示词模板如下所示
"a photo of a class label"
一个更抽象的一般化prompt模板如下公式所示:
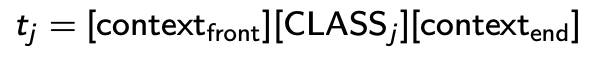
即在类别标签的前后添加一定的文本内容。本文默认认为标签是由数据集给定的,无法调整或学习;但标签前后的文本内容即context可以调整。
Adversarial Attacks on VLMs
给定目标视觉语言模型,对抗样本是如何生成的呢?一个常用的策略是最小化图片和ground-truth类别标签prompt之间的特征相似度,也可以理解为最大化他们之间的不相似度,如下公式所示:
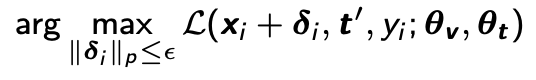
The Sensitivity of Adversarial Robustness to Text Prompts
由上述算法可知,攻击者在构建对抗样本时,一个关键的设计决策是使用什么样的text prompt模板。在我们开始实验之前,有两点需要明确。首先,攻击者使用的attack prompt可以不同于用户使用模型进行推断任务时所使用的inference prompt。其次,取决于威胁模型(threat model)是否为白盒(white-box),攻击者可能无从知晓用户用于推断任务时使用的inference prompt。
为了研究Text Prompt对对抗攻击和防御算法有效性的影响,如下图所示,本文设计并选取了6种不同的Text Prompt模板,并将它们分别应用于攻击者的攻击生成和用户的类别推断,从而产生了36(6*6)种情况。

Figure 5 使用不同attack prompt(列)和inference prompt (行)时模型的对抗鲁棒性。对于每一行,只给出了对抗鲁棒性的最小值,而其他数值则是相对于最小值的增量。
通过分析实验数据,我们总结出来三点重要的发现:
1. 对抗攻击的强度对使用的Prompt非常敏感。例如,当Inference Prompt被固定为P5时,攻击者使用的Prompt从P1变到P5,对抗鲁棒性会提高2.21%。这意味着在防御相同的情况下,攻击的有效性随着Prompt从P1变到P5而下降了2.21%。
2. 几乎所有最强的对抗样本都是通过使用与Inference端相同的Prompt生成的。这在图中可以明显地看出,所有最小的对抗鲁棒性几乎都出现在对角线矩阵的对角线上。这表明对于攻击者来说,能否获知用户使用的Inference Prompt将极大得影响其所实施的攻击的有效性。
3. 模型的对抗鲁棒性对用户使用的Inference Prompt也非常敏感。例如,当Inference Prompt被从P5更换为P4时,模型的对抗鲁棒性会从8.53%提高到10.55%,增加了两个点。这也表明在这些Prompt中存在巨大的优化潜力。
Adversarial Prompt Tuning
受到上述第3点发现的启发,我们提出一种新的对抗防御机制:通过调整text prompt的方式来提高模型的对抗鲁棒性。具体来说,我们希望通过优化text prompt的文本内容来使得模型在基于这一text prompt进行推断时更不易受对抗样本的攻击影响。我们将这一方法命名为:Adversarial Prompt Tuning (APT),其具体实现如下所示:
1. Text prompt的参数化(parameterization)。为了能够使用learning的方法来优化text prompt,我们首先需要参数化text prompt。我们在word embedding空间设置了M个vectors,每个vector包含了512个可学习的参数,并将他们和class label的embedding顺序串联起来,如下公式所示:
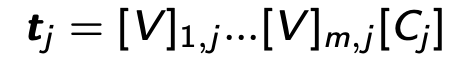
2. Text prompt的优化。我们使用类似对抗训练(adversarial training)的方法来优化text prompt。即最小化对抗样本的损失函数,如下公式所示:
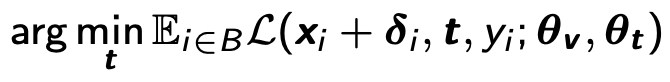
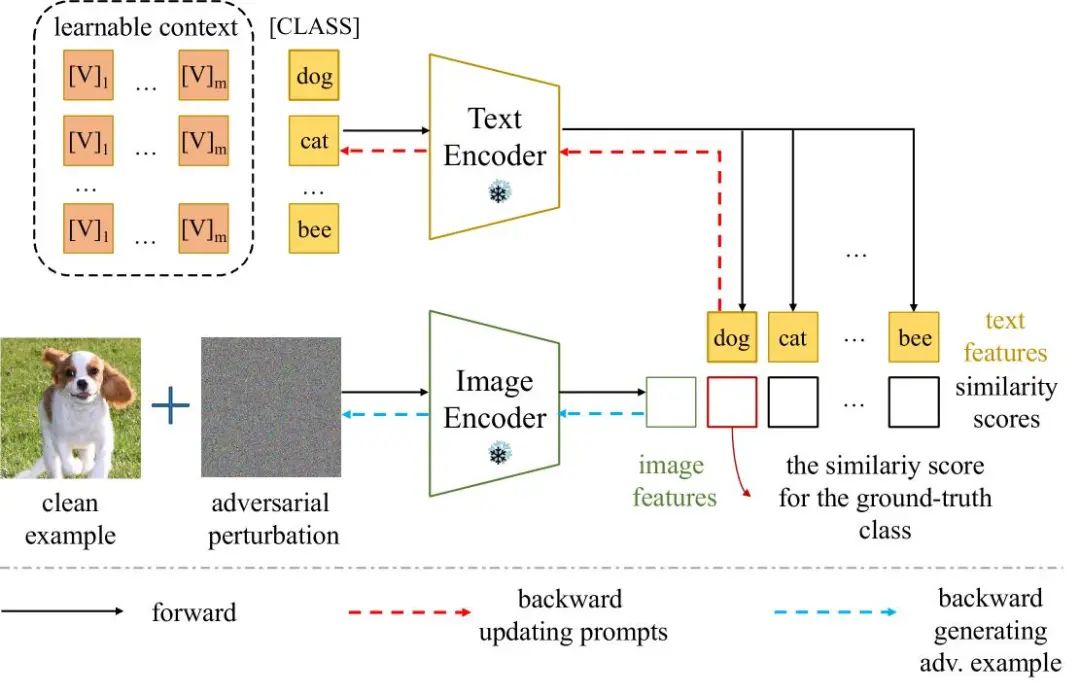
Figure 6 APT算法概览。
Experiments and Results
为了评估APT的性能,本文在ImageNet等11个数据集上进行In-Distribution泛化测试,APT展现了三个主要优点:
1. 参数高效(parameter efficient)。具体来说,只需要少量的context vectors,即只需学习512个参数,就可以大大提高模型的性能。与基线(baseline)相比,在准确性上提高了13%,在对抗鲁棒性上提高了8.5%。
2. 数据高效(data-efficient)。在one-shot learning的情况下,本文方法仍然体现了很好的性能提升。one-shot Learning指的是对于每一个类别,在训练集上只有一张图片。与基线相比,在one-shot Learning的情况下,本文方法在准确性和对抗鲁棒性这两个指标上分别提高了6.1%和3.0%。
3. 有效性(Effective)。APT在准确性和鲁棒性方面都取得了极大的性能提升,准确性提高了26.4%,对抗鲁棒性提高了16.7%。并在准确性和鲁棒性之间取得了一个不错的权衡。
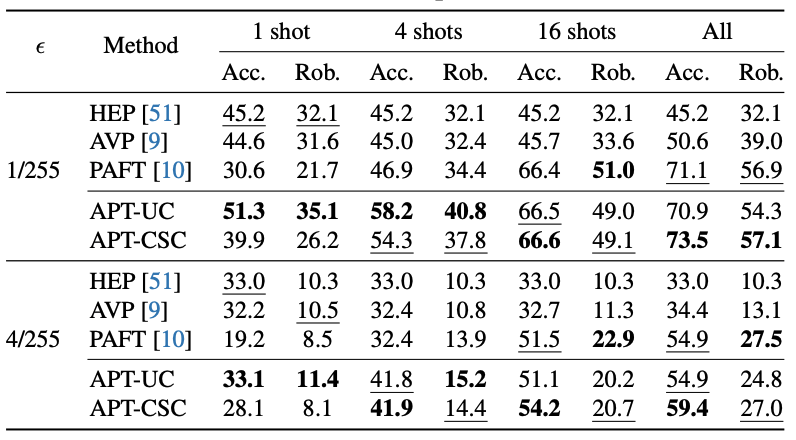
Figure 7 In-Distribution表现。在不同攻击强度和训练样本数的情况下,11个数据集平均结果。
在In-Distribution测试之外,我们还测试了APT在面对distribution shift下的表现,即Out-Of-Distribution (OOD)表现:
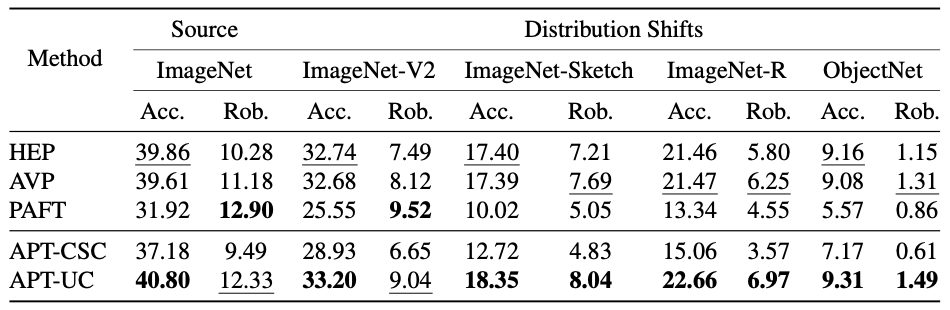
Figure 8 OOD 表现。epsilon=4/255。
最后,我们测试了模型在zero-shot设置下的表现,即将ImageNet上学习到的text prompt应用到其他数据集上的表现:
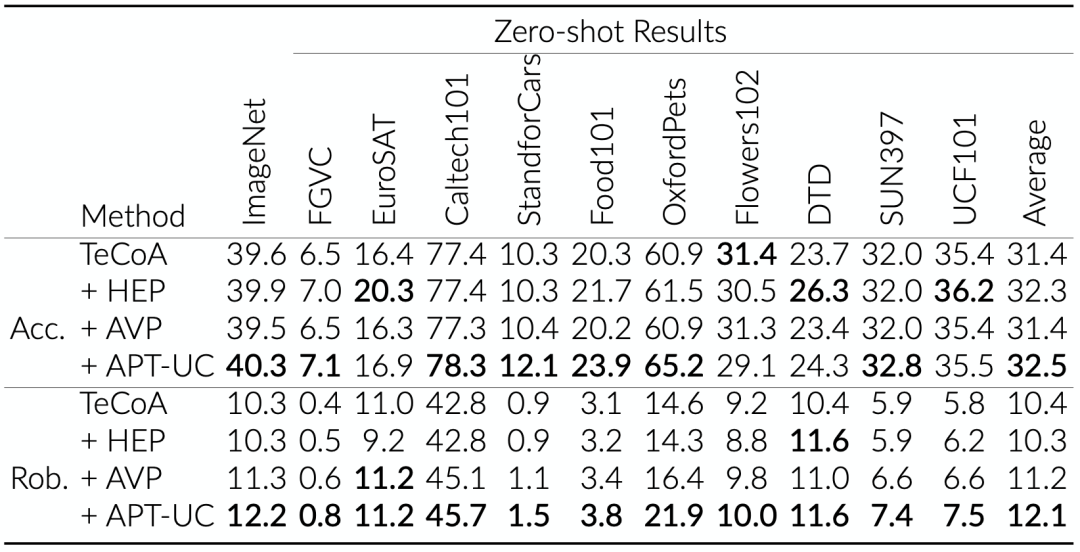
Figure 9 Zero-shot表现。Epsilon=4/255。
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信:CVer5555,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer5555,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
















 31
31

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









