






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer444,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球,可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文搞科研,强烈推荐!

2024 年 2 月 27 日凌晨,CVPR 2024 顶会论文接收结果出炉!这次没有先放出论文 ID List,而是在OpenReview上直接公布结果(朋友圈好友纷纷晒截图,报喜讯~你被刷屏了没?!)。

CVPR 2024 主委会官方尚未发布这次论文接收数据,但可以确定的是接收数量再创新高!毕竟ID都快18000了...PS:CVPR 2023 是收录2360篇
CVPR 2024 会议将于 2024 年 6 月 17 日至 21 日在美国西雅图举行。

Amusi 简单预测一下,CVPR 2024 收录的工作中 " 扩散模型、多模态、大模型、3DGS、AIGC " 相关工作的数量会显著增长。
本文快速整理了10篇 CVPR 2024 最新工作,内容如下所示。如果你想持续了解更多更新的CVPR 2024 论文和代码,大家可以关注CVPR2024-Papers-with-Code,在CVer公众号后台回复:CVPR2024,即可下载,链接如下:
https://github.com/amusi/CVPR2024-Papers-with-Code
这个项目是从2020年开始,Star数已经破万+!覆盖CVPR 2020-2024的论文工作,很开心能帮助到一些同学。
如果你的 CVPR 2024 论文接收了,欢迎提交issues~
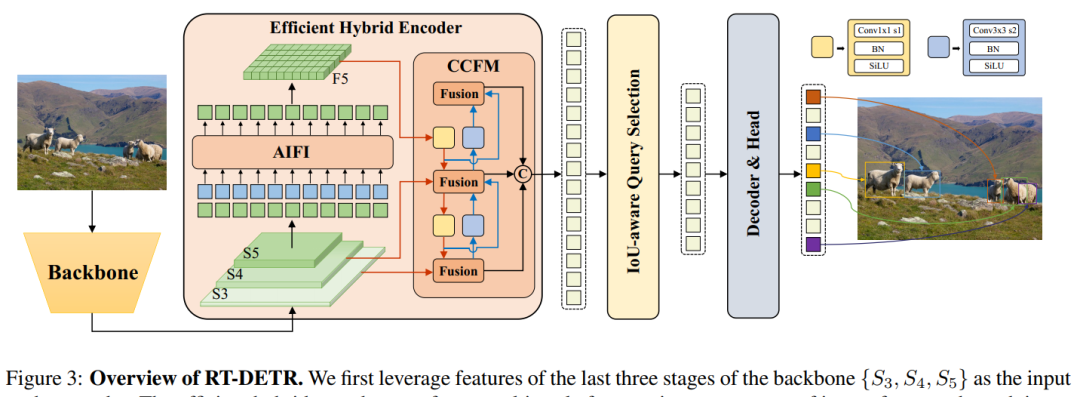
1. DETRs Beat YOLOs on Real-time Object Detection
单位:百度
Paper: https://arxiv.org/abs/2304.08069
Code: https://github.com/lyuwenyu/RT-DETR
超越同规模所有YOLO!RT-DETR:一种实时检测Transformer,据称是第一个实时端到端目标检测器,在速度和精度方面超越YOLOv8、v7等网络,而且在精度上超过了全部使用相同骨干网络的DETR检测器,代码已开源!
2. InstanceDiffusion: Instance-level Control for Image Generation
单位:Meta, UC 伯克利
Homepage: https://people.eecs.berkeley.edu/~xdwang/projects/InstDiff/
Paper: https://arxiv.org/abs/2402.03290
Code: https://github.com/frank-xwang/InstanceDiffusion
InstanceDiffusion:图像生成新工作,可以对文本到图像的生成进行精确的实例级控制,支持每个实例的自由格式语言条件,并允许以灵活的方式指定实例位置,例如简单的单点、涂鸦、边界框或复杂的实例分割掩码及其组合,代码已开源!

3. Residual Denoising Diffusion Models
单位:中科院, 国科大, 沈阳大学, 华南理工, 港大
Paper: https://arxiv.org/abs/2308.13712
Code: https://github.com/nachifur/RDDM
残差去噪扩散模型(RDDM):一种用于图像复原和图像生成的统一扩散模型,在四种不同图像复原(暗光增强、去雨、去模糊等)任务上的实验结果表明,RDDM在不超过五个采样步骤的情况下实现了SOTA性能,代码已开源!

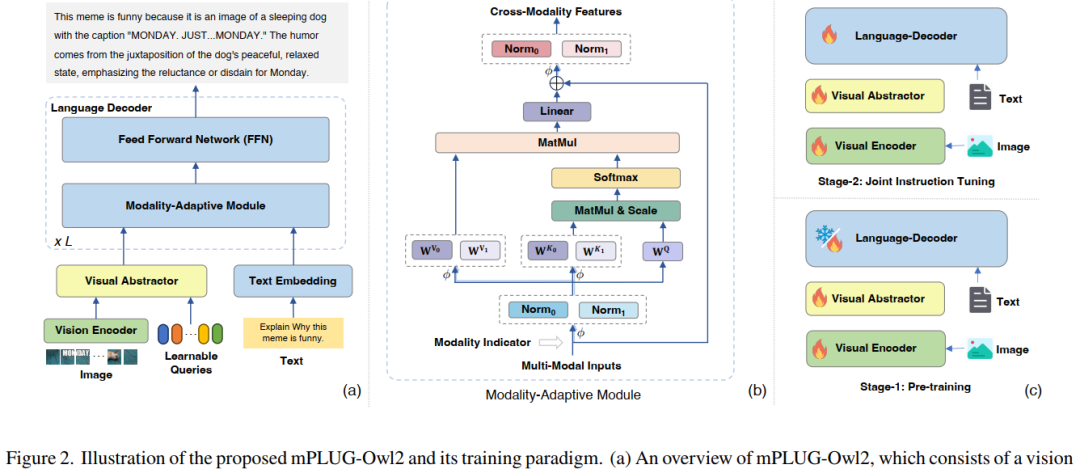
4. mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration
单位:阿里巴巴
Paper: https://arxiv.org/abs/2311.04257
Code: https://github.com/X-PLUG/mPLUG-Owl/tree/main/mPLUG-Owl2
本文引入一种多功能的多模态大语言模型 mPLUG-Owl2,它有效地利用模态协作来提高文本和多模态任务的性能,这是第一个在纯文本和多模态场景中展示模态协作现象的 MLLM!代码已开源!
5. Scaffold-GS: Structured 3D Gaussians for View-Adaptive Rendering
Homepage: https://city-super.github.io/scaffold-gs/
Paper: https://arxiv.org/abs/2312.00109
Code: https://github.com/city-super/Scaffold-GS
6. ECLIPSE: A Resource-Efficient Text-to-Image Prior for Image Generations
Homepage: https://eclipse-t2i.vercel.app/
Paper: https://arxiv.org/abs/2312.04655
Code: https://github.com/eclipse-t2i/eclipse-inference
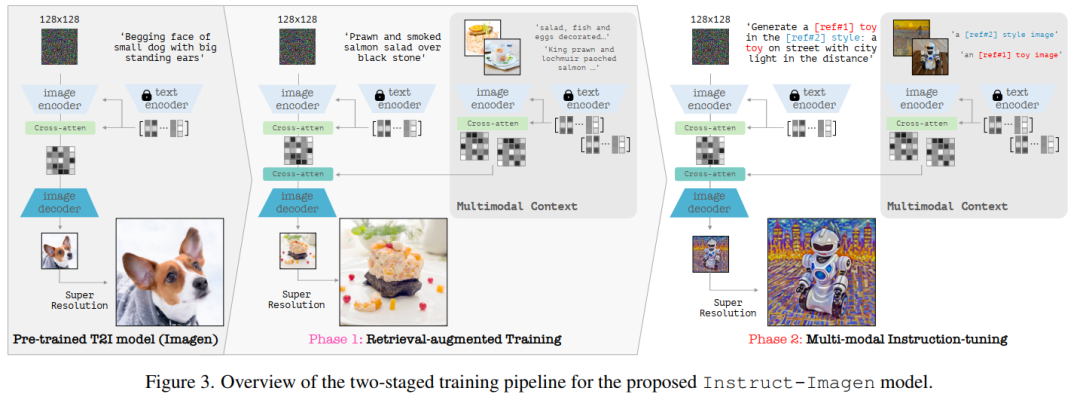
7. Instruct-Imagen: Image Generation with Multi-modal Instruction
单位:谷歌DeepMind, 谷歌
Paper: https://arxiv.org/abs/2401.01952
Instruct-Imagen:一种图像生成新模型,它可以理解多模态指令以完成各种视觉生成任务,使用自然语言来合并不同的模态(例如文本、边缘、掩码、风格、主题等),以生成高保真可控的图像!
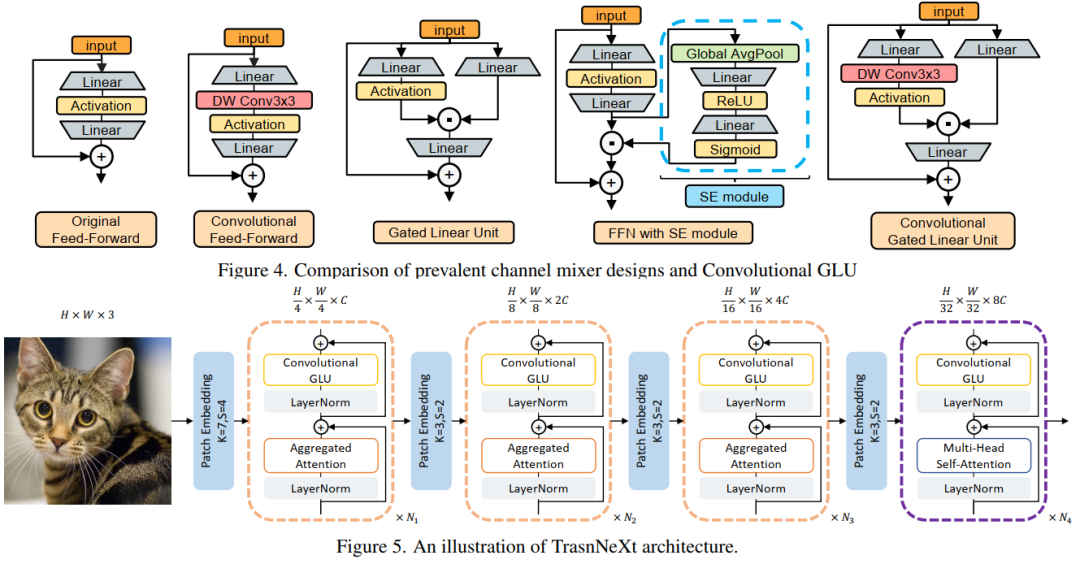
8. TransNeXt: Robust Foveal Visual Perception for Vision Transformers
作者:Dai Shi 一位独立研究员
Paper: https://arxiv.org/abs/2311.17132
Code: https://github.com/DaiShiResearch/TransNeXt
视觉新主干!本文提出聚合注意力:一种基于仿生设计的token mixer,并提出卷积 GLU,进而创建了TransNeXt新视觉主干,在各种下游视觉任务上,多种模型尺寸上都实现了最先进的性能,代码已开源!
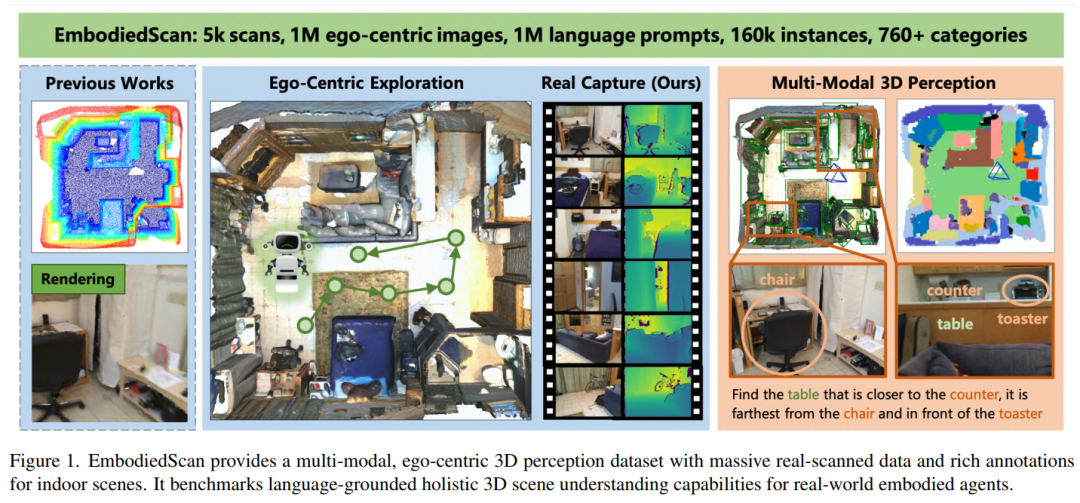
9. EmbodiedScan: A Holistic Multi-Modal 3D Perception Suite Towards Embodied AI
单位:上海AI Lab, 上交, 港大, 港中大, 清华
Homepage: https://tai-wang.github.io/embodiedscan/
Paper: https://arxiv.org/abs/2312.16170
Code: https://github.com/OpenRobotLab/EmbodiedScan
EmbodiedScan:一种多模态,以自我为中心的3D感知数据集和基准,包含超过5K扫描,1M RGB-D视图,1M语言提示,760个类别的160K 3D旋转边界框,80个常见类别的密集语义占用,还提出一个具身感知新基线,代码已开源!
10. Object Recognition as Next Token Prediction
Paper: https://arxiv.org/abs/2312.02142
Code: https://github.com/kaiyuyue/nxtp
最新CVPR 2024论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集
多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-多模态和扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如多模态或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
















 1980
1980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









