






ChatGPT 火爆全球后,基于人类反馈的强化学习(RLHF)成为了一项可能让机器像人一样思考的重要技术。OpenAI 联合创始人、研究科学家 John Schulman 将“RLHF”看作是 ChatGPT 成功的秘密武器。
强化学习在大模型中的应用具有广泛潜力和机会,特别是ICLR2024接收论文中就有573篇论文与强化学习或大语言模型相关,远超其他研究分类。
所以这次我整理了
+10年(2008-2018)NIPS顶会强化学习论文100篇
+ICLR2024强化学习和LLM相关论文573篇
+Neurips 2023 强化学习论文350篇
+ICLR2023顶会强化学习论文376篇
+强化学习发展路线 (含论文140篇)
+AAAI2023强化学习论文11篇
+经典强化论文合集100篇
扫码回复“强化学习”
立即领取1500篇强化学习顶会论文


最近,大语言模型LLM成为了大家关注的热点,在人机对话领域具有里程碑的意义。然而,传统的LLM并没有明确的动作层次上的策略,其潜在的策略可以看成是对Token的选择。
那么如何更好的学习基于深度强化学习任务型对话策略呢?
这次我邀请了国内985理工强校博士徐老师,在7月25日19点30和大家探讨任务型对话策略的现有研究方法、对话策略的评估方式、数据集,以及介绍经典论文,并且和大家分享对话策略在大模型中的应用以及未来的研究趋势。

扫码回复“强化学习”
预约25日晚19:30大咖直播

深度学习和强化学习分别在2013年和2017年被选全球十强技术之一,甚至有研究者构建了一个“人工智能 =深度学习 + 强化学习”的公式,由此可见深度强化学习的价值及重要性。
RLHF是一个将强化学习与人类反馈相结合的框架,以提高个体(Agent)在学习复杂任务中的表现。在RLHF中,人类通过提供反馈参与学习过程,帮助个体更好地理解任务,更有效地学习最优策略,这次我邀请了多位顶刊大佬给大家录制了三节强化学习课程,三小时吃透强化学习!

扫码回复“强化学习”
解锁三节强化学习系列课

顶会idea福利
沃恩智慧秉承服务好每一位学员的初心,从人工智能论文辅导起步,逐步扩充到人文社科、医学、理工科、金融商科等全方向,SCI、SSCI、CCF、EI、南核北核等国际/国内期刊会议均可提供专业辅导。
专业顾问老师规划学习,同时配有论文导师、代码导师及专属班主任,4人服务你1人。从选题、调研、idea验证、代码、实验、润色、投稿、直至中稿的一站式科研服务(不代写!)。
沃恩智慧拥有自主研发的科研服务系统,除了排课、上课提醒、课程无限次回放、布置作业、自动分析科研进度等功能,最大的优势是对学员信息和科研成果做到保密。同时,近700位全球最顶尖的博士导师团队不仅会带你做科研、发表科研论文,拿到名校offer,更能给你提供申博申硕指导推荐,大厂实习工作内推名额,为你的科研之路保驾护航!
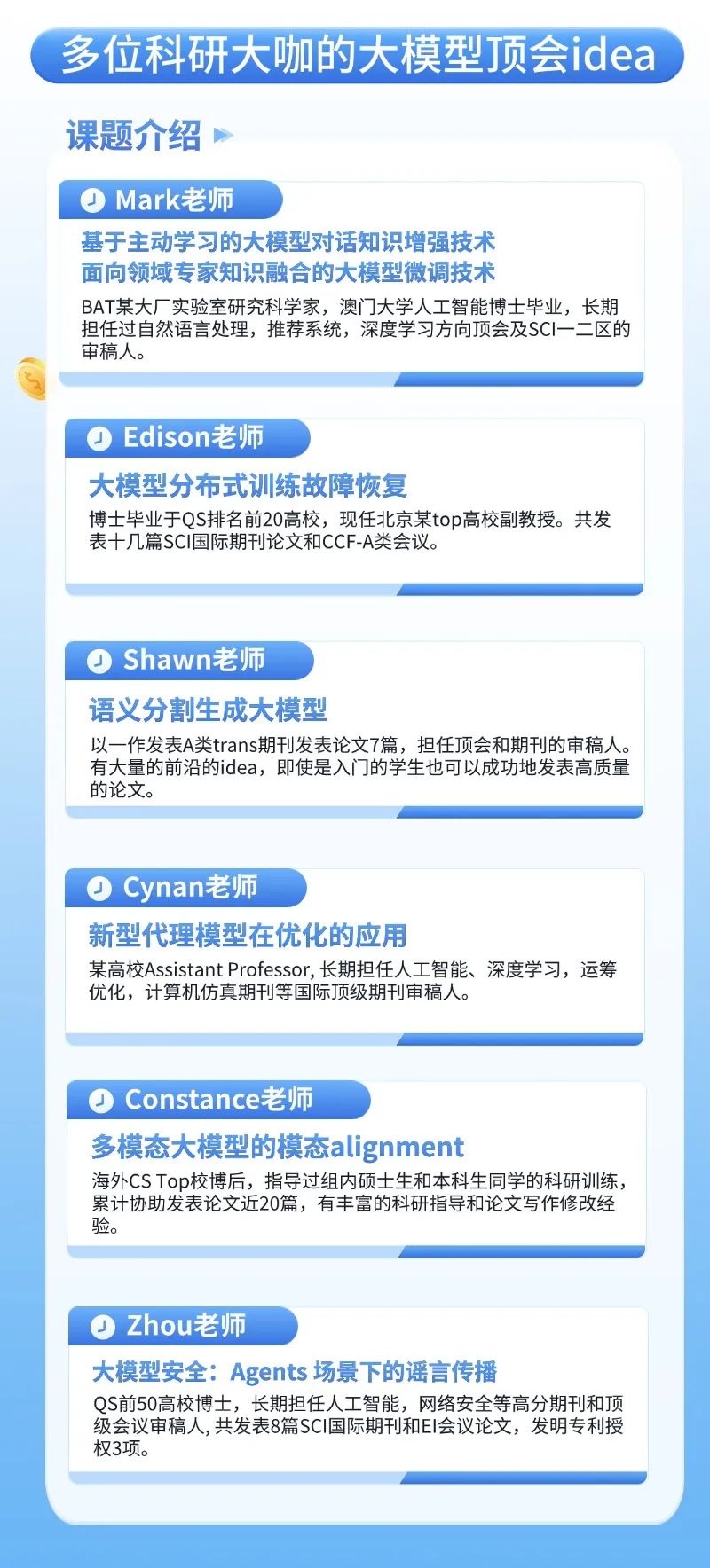
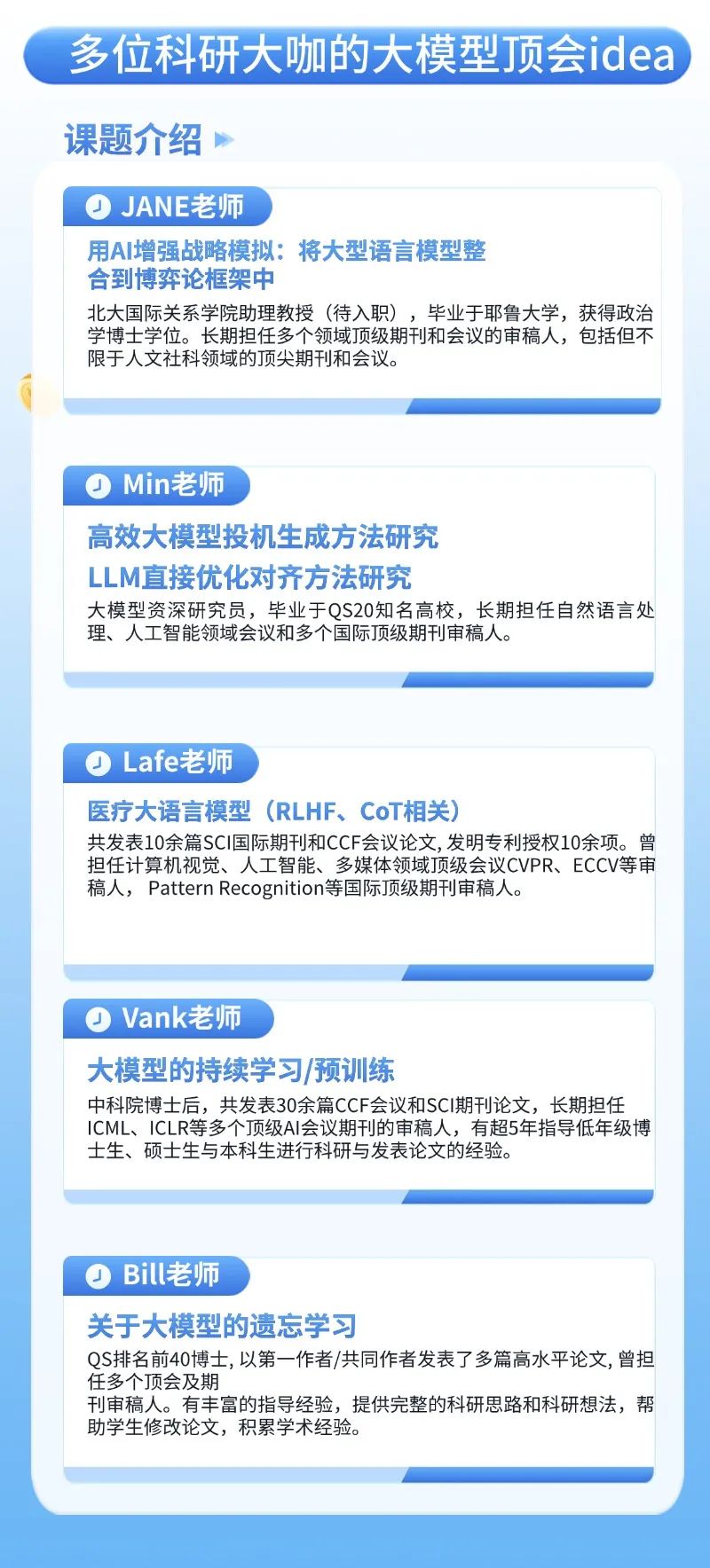
左右滑动查看更多
扫码回复“大模型”
立即解锁顶会新idea
















 138
138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









