







LayoutLLM
Paper : LayoutLLM: Layout Instruction Tuning with Large Language Models for Document Understanding
Author : Chuwei Luo, Yufan Shen, Zhaoqing Zhu, Qi Zheng, Zhi Yu, Cong Yao
Affiliation : Alibaba Group, Zhejiang University
Publication :CVPR 2024
Code :https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/LayoutLLM
提出 LayoutLLM ,使用 document pretrained models
提出了三组不同层次的预训练任务:文档级、区域级和分段级,学习从全局到局部的文档布局。
提出 LayoutCoT ,保证对于布局信息的充分使用
0 前景
文档人工智能,包括其文档理解任务,例如文档 VQA 和文档视觉信息提取,是目前学术界和工业界的热门话题。近年来,文档预训练模型在文档 A 下游领域取得了优异的贡献。
0.1 动机
由于需要对相应的下游任务数据进行微调,直接采用预训练模型(如 LayoutLM )进行零样本文档理解具有挑战性。–>LLM/MLLM
对于文本 AI , Layout 信息至关重要,但是只通过文本将布局信息传给 LLM 是很困难的,而且使用代表文本和布局信息的布局文本作为 LLM 的输入并不能保证其有效理解这种格式化文本。
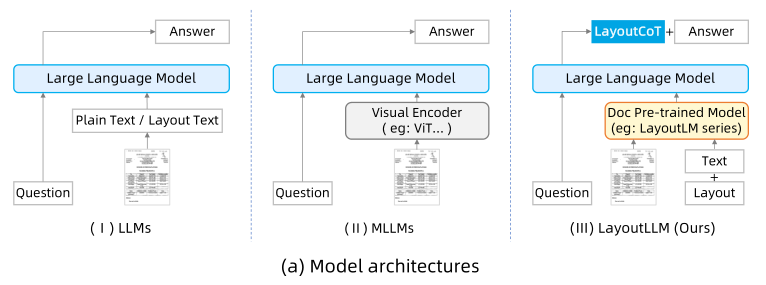
并且,MLLM也没有充分利用文档布局信息。在预训练阶段,通常应用或将文档中的所有文本生成为纯文本等任务,缺乏对于文档布局信息的利用。supervised fine-tuning (SFT)阶段也没有关于文档布局的明确学习。
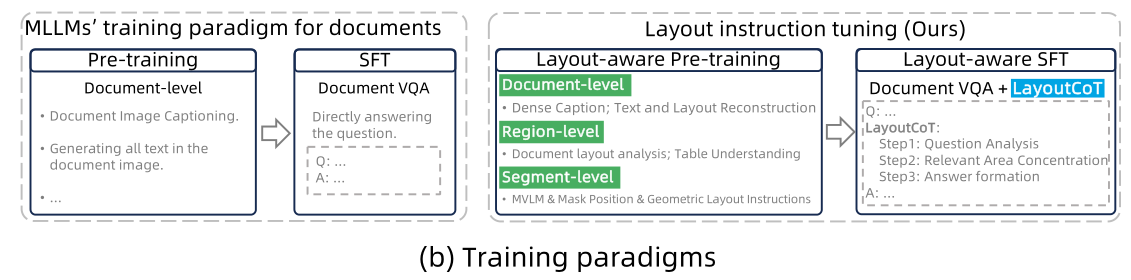
1 方法
LayoutLLM 是一种基于 LLM/MLLM 的方法,它结合了用于文档理解的文档预训练模型。为了增强 LayoutLLM 中的文档布局理解,提出了一种新颖的布局指令调整策略,该策略由两个阶段组成:布局感知预训练和布局感知监督微调(SFT)。
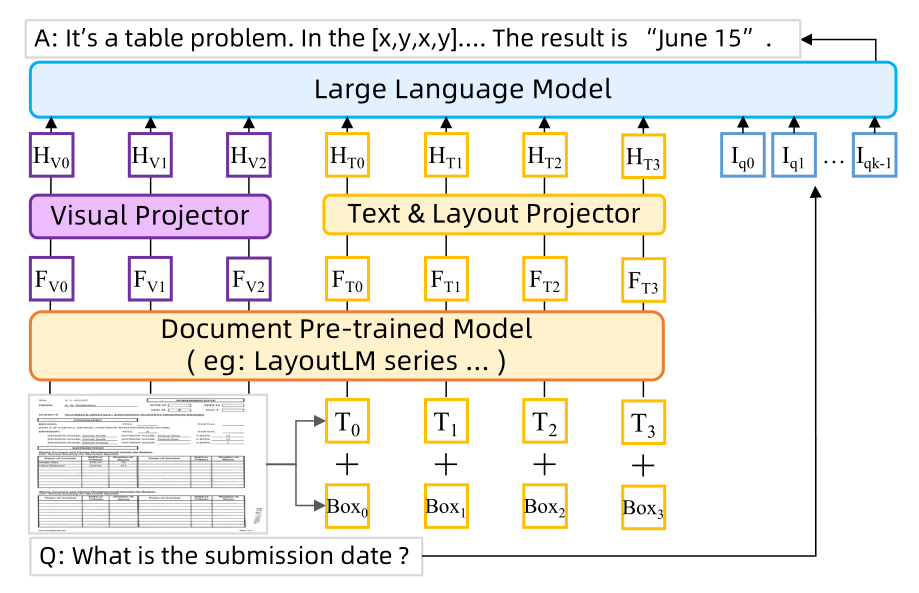
在LayoutLLM中,给定输入文档图像及其相应的文本和布局信息,需要文档预训练模型编码器来获取多模态文档特征。然后,这些特征由多模态投影仪进行编码,并与指令嵌入一起输入 LLM 以生成最终结果。
模型架构
1.1 Document pre-trained model encoder
利用广泛使用的文档预训练模型 LayoutLMv3 作为基本文档编码器。文档图像、文本和布局最初被输入到文档预训练模型(DocPTM)中。然后通过DocPTM对其进行编码,得到相应的特征。
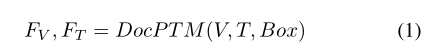
1.2 Multimodal projectors
为了将 DocPTM 的多模态特征投影到 LLM 的嵌入空间中,受到 LLaVA 中简单而有效的投影仪设计的启发,两个不同的多层感知器(MLP)分别用作视觉投影仪和文本和布局投影仪。
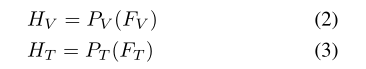
1.3 Large language model
最后,HV、HT和问题指令文本的嵌入一起输入LLM,生成目标答案。
1.4 Layout Instruction Tuning
LayoutLLM 模型使用布局指令调整进行训练,包括两个阶段:布局感知预训练和布局感知 SFT。
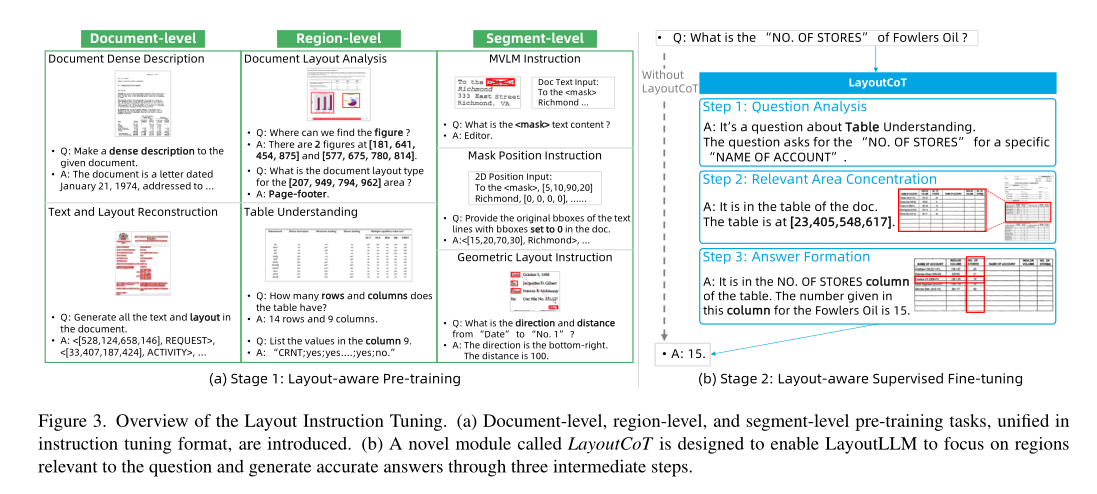
1.4.1 Layout-aware Pre-training
预训练 LayoutLLM 的目标是通过布局学习增强模型对不同级别文档的全面理解,而不是像现有 MLLM 方法那样只关注全局文档级别的理解 。为此,在预训练阶段,三种不同级别的预训练策略同时应用于LayoutLLM,即文档级、区域级和段级。
Document-level
为了使模型具有基本的全局文档理解,提出了预训练任务,即文档密集描述 Document Dense Description (DDD) 和文本和布局重建 Text and Layout Reconstruction (TLR)。与图像描述任务一样,DDD 任务要求模型学习描述输入文档。
而且,在DDD任务中,对文档图像的描述更加详细。例如,在用于 LLaVAR 预训练的文档图像标题数据中,标题平均包含 36.27 个单词,而在 DDD 任务的建议数据集中,描述平均包含 373.25 个单词。通过DDD任务,模型可以获得基本的文档级信息,例如文档类型和详细内容。 TLR任务旨在重建文档的完整文本和布局信息,并以“<{box}, {text} >”的格式输出。
TLR 任务将 DocPTM 输出的文本和布局嵌入与 LayoutLLM 的 LLM 空间对齐。因此,它使 LayoutLLM 中的LLM 能够理解文档中包含的文本和布局信息。
Region-level
文档特定区域中包含的信息,例如标题、图形、表格,对于理解文档至关重要。这些区域是区分文档与自然语言中的纯文本的重要特征。为了使 LayoutLLM 实现基本的区域级理解,利用了两个预训练任务,即文档布局分析 Document Layout Analysis (DLA)和表格理解 Table Understanding(TU)。 DLA任务通过两种方式实现,如图3所示。一种涉及根据布局类型定位布局区域,另一种涉及识别给定区域的类型。此外,表格区域与其他区域的不同之处在于它需要额外关注 2D 布局理解。TU 任务使模型能够理解文档表格区域中的基本行和列信息。如图3所示,TU任务包括对行数和列数、逻辑坐标以及行和列内的内容的指令调整。
Segment-level
文档预训练模型的早期工作已经证明了段级文档预训练任务对文档布局理解能力的有效性,例如掩模视觉语言建模(MVLM),位置掩蔽 [31, 51],以及几何预训练。受这些工作的启发,为了使 LayoutLLM 具有段级布局理解,这些任务被转换为用于预训练的指令格式,如图 3(a)所示。对于 MVLM 指令,对 LayoutLLM 的文本输入进行随机屏蔽,并通过询问屏蔽的单词并回答它们来调整模型。对于掩码位置指令,当输入到 LayoutLLM 时,特定文本行的布局信息(坐标)被随机设置为 0。该指令是通过询问坐标为零的文本行并请求模型用文本内容的原本坐标回答。对于几何布局指令,随机选择文本行,并通过询问它们之间的方向和距离来构建指令。
1.4.2 Layout-aware Supervised Fine-tuning
在现有基于文档的 MLLM 的 SFT 阶段,模型直接由文档理解指令的答案来监督。因此,这些方法缺乏对文档布局的明确学习,而这对于文档理解至关重要。考虑到这一限制,并受到之前与思路链 (CoT)相关的工作的启发,这些工作表明使用中间步骤进行推理可以极大地提高性能。提出了一种称为 LayoutCoT 的新颖模块,它将布局信息显式地合并到 CoT 的每个中间步骤中。同时,通过引入布局感知的中间步骤,使得答题过程获得了一定程度的LayoutLLM可解释性,同时也提供了基于LayoutCoT的交互式修正可能性
LayoutCoT Details
LayoutCoT涉及以下三个中间步骤:
步骤1:问题分析。为了有效解决文档理解问题,分析问题的关键特征非常重要。识别问题类型,例如表格理解或段落中的实体提取,并评估问题是简单的提取查询还是更复杂的推理问题,可以帮助指导后续推理过程的方向。因此,为了给后续步骤提供基础指导,设计了题型分析步骤,包括从布局角度分析题型以及对题型本身的详细理解。受益于布局感知预训练的布局理解能力,这一步可以提取问题中提到的与文档具体特征相关的类型和关键信息。
第 2 步:相关区域集中。对于大多数文档理解任务,整个文档包含大量不相关的信息,可能会混淆模型。这一步的目的是关注相关区域并生成其位置信息,用于辅助模型准确推断答案。受益于步骤1传达的布局信息以及从区域和段级预训练中学到的定位能力,模型可以准确地生成相关区域的位置。例如图3(b)中,根据步骤1中的问题类型“表格”,可以定位到相关的“表格”。通过引导模型聚焦于相关区域,这一步很大程度上缩小了搜索范围,增加了给出正确答案的可能性。同时,位置信息提供了一种目视检查和交互式校正的方法。
第 3 步:答案形成。最后,最后一步,即答案形成,根据步骤2中相关区域的布局特点和步骤1中分析的要点进行解释,得到最终答案。例如图3(b)中,对于“表格”类型的问题,这一步涉及分析步骤2中相关表中的行和列,并逐步推断答案。对于“键值”问题,分析集中区域的关键词有助于得到最终答案。根据不同布局区域的特征以不同的方式分析答案,不仅提高了文档的理解性能,而且带来了一定程度的可解释性。
LayoutCoT Construction

考虑到构建 LayoutCoT 时需要文本和图像注释,手动标记可能很困难。算法 1 提出了一种免手动标记的方法,使用带有 GPT (GPT-3.5 Turbo) 的公共数据集生成 LayoutCoT 数据。它涉及以 GPT 可以理解的格式表示文档文本和布局。然后利用 GPT 生成基于文档内容的 QA 和相应的文本 CoT。最后,使用规则将文本 CoT 转换为 LayoutCoT。
重点关注三种类型的公开文档数据集:HTML 文档(DH)、图像文档(DI)和用于机器阅读理解(MRC)的文本文档(DM)。构建过程如下:
1)Document Representation:为了充分利用 GPT 的功能,确保馈送到 GPT 的文档内容包含准确的布局信息至关重要。由于HTML是能够准确表示文档的格式化语言,因此DH使用原始HTML来表示。通过将 HTML 转换为 PDF 并使用 PDF 解析器,可以获得文本和边界框。对于 DI,使用布局感知文本。 DI 中的文本和边界框来自原始数据集注释。
2) QA&Text CoT Generation:文档的语言表示R用于提示GPT生成带有文本CoT Tc 的 QA对 QA。此外,DM包括QA对和推理过程,从而直接重用QA并手动组织Tc。生成的Tc包括LayoutCoT的步骤1(问题分析)和步骤3(答案形成),并定位文档中所有相关句子进行QA。
3)LayoutCoT生成:Tc 中的步骤1和3用作 Lc中的步骤1和3。为了构建Lc的步骤2(相关区域集中),将Tc中所有定位的相关句子的并集边界框作为相关区域。
4)Document Images Generation:对于 DH 和 DM,HTML 和 MRC 文本将转换为图像。总体而言,文档图像 I、生成的 QA 对 QA 和 LayoutCoTs Lc 构成了最终的 LayoutCoT 数据集 Dc。
2 实验
2.1 Dataset Collection
LayoutLLM 的布局感知预训练数据
来自公开的文档理解数据集。它不包含来自下游基准的训练、验证和测试集的任何数据。区域级预训练任务、大多数文档级和段级任务都是自监督的。因此,只需要原始数据集中的文档图像和从 PDF 转换而来的图像,以及 PDF 解析的相应 OCR 或文本布局结果。对于这些任务,数据是从 PubLayNet、DocLayNet、Docbank 、RVL-CDIP 和 DocILE 中随机采样的。其中,文档密集描述的数据来自将文档文本内容输入GPT-3.5 Turbo,促使其生成平均373.25字的文档密集描述。对于区域级任务,特别是文档布局分析任务,利用公开可用的文档布局分析数据集,包括 PubLayNet 、DocLayNet 和 Docbank。另一项区域级任务(表理解)的数据源自 PubTabNet 及其表注释。所有数据都被转换成图3(a)所示的指令格式。总共构建了 570 万条指令,文档级、区域级和段级任务的比例分别为 1:4:4。
LayoutLLM 的布局感知 SFT 数据
由 GPT (GPT-3.5 Turbo) 生成,并从现有文本机器阅读理解 (MRC) 数据集转换而来,如第 2 节中所述。 3.2.2.为了生成高质量的基于文档的文本 QA 和文本 CoT,让 GPT 理解文档布局至关重要。因此,该文档使用布局文本 和 HTML 来表示。与预训练数据类似,算法1中的DI也是从PubLayNet、DocLayNet、Docbank、RVL-CDIP和DocILE中随机采样,用于构建布局文本。算法1中的DH来自GPT的免费生成。算法 1 中的 DM 是从 FeTaQA中随机采样的,FeTaQA 是一个维基百科问答数据集。总共构建了 300K 条指令,DI、DH 和 DM 的比例分别为 5:4.5:0.5。
2.2 Training Setup
LayoutLLM 的编码器权重是从 LayoutLMv3-large 初始化的,这是一种广泛使用的文档预训练模型。 LLM 主干是从 Vicuna-7B-v1.5初始化的。其他参数随机初始化。在预训练期间,LLM被冻结,并且更新两个投影仪和文档预训练模型编码器的参数。在 SFT 期间,LLM 和两个投影仪都进行了微调,同时保持文档预训练模型编码器冻结。
2.3 Evaluation Setup
在现实世界的文档理解场景中,人们高度期望零样本能力。因此,对广泛使用的文档理解基准进行了零样本评估,包括文档视觉问答(Document VQA)和视觉信息提取(VIE)。所有基准测试中仅使用测试集,并且仅使用官方提供的图像、文本和布局信息。文档 VQA 数据集包括 DocVQA测试集(包含 5,188 个问题)和 VisualMRC 测试集(包含 6,708 个问题)。根据原始数据集的评估指标设置,ANLS用于评估DocVQA,Rouge-L用于评估VisualMRC。对于 VIE 任务,使用 FUNSD、CORD 和 SROIE 。 FUNSD 的测试集包含 50 个表单图像,每个图像都带有实体级标题、问题、答案等注释,以及实体链接注释。 CORD 的测试集包含 100 张收据图像,标注了 30 种实体类型,例如税额、总价等。SROIE 的测试集包含 347 张收据图像,标注了 4 种实体类型:公司、日期、地址和总计。为了提示LLM/MLLM进行零样本VIE,VIE数据集中的注释被转换为问答格式(VIE的QA)。对于 FUNSD 中带有链接的键值注释,格式为 {问:文档中的“键”是什么?一个值”}。对于CORD和SROIE中的实体注释,直接询问文档中的实体,如{问:文档中的地址是什么?答:使用“地址注释”}。遵循 DocVQA,VIE 任务的 QA 由 ANLS 进行评估。
3 结果
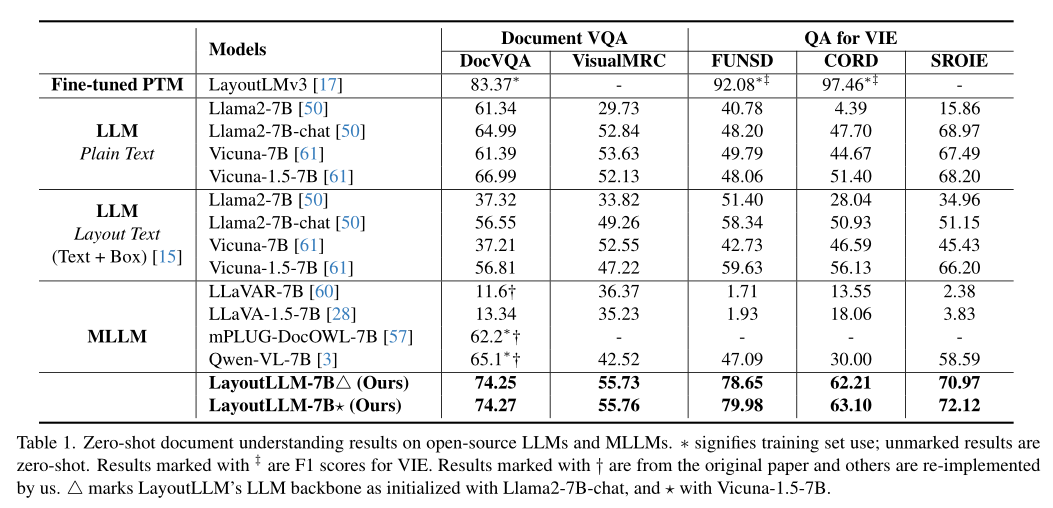
评估了 LayoutLLM 和现有开源 LLM 和 MLLM 的零样本文档理解性能。一般来说,对于零样本文档 VQA 和 VIE,现有的 LLM 比 MLLM 更好。例如,在 DocVQA 上的结果中,大多数 LLM 可以达到 60% 左右或更高的性能,而大多数 MLLM 只能达到 10% 左右。
一个可能的原因是这些 MLLM 很难从文档图像中获取准确的文本信息。此外,对于LLM,进一步讨论了分别使用纯文本和布局文本作为文档表示,其中布局文本通过添加文本坐标来引入布局信息,格式为:{text:“text”, box:[x1,y1,x2 ,y2]} [15]。与纯文本相比,布局文本变体没有表现出稳定的性能改进,这在某些任务中很明显,例如在 Vicuna-1.5 中,VIE 有所改进(FUNSD 48.06% 到 59.63%),但 DocVQA 有所下降(66.99%)至 56.81%)。 LLM 可能缺乏学习这种格式化布局文本的能力,并且直接向文本添加布局信息(例如坐标)也会大大增加标记长度,使答案推理更具挑战性。
与之前的 SOTA 模型 LayoutLMv3(使用下游任务的训练集进行微调)相比,LayoutLLM 在 DocVQA 基准测试中表现出具有竞争力的性能。与这些 LLM 和 MLLM 相比,LayoutLLM 在所有评估基准上都取得了一致且显着的改进。值得注意的是,采用零样本性能的 LayoutLLM 在 DocVQA 数据集上的性能优于 mPLUG-DocOWL 和 Qwen-VL 约 10%,这两个数据集都是使用该数据集进行训练的。这表明 LayoutLLM 可以学习更稳健、更具区分性的文档理解表示。此外,LLM主干的不同初始化的实验在所有基准测试中都取得了最佳结果,证实了LayoutLLM可以适应各种LLM。综上所述,我们的方法探索了一种更有效的利用布局信息进行文档理解的方法,这显着提高了零样本文档理解的性能。
消融实验
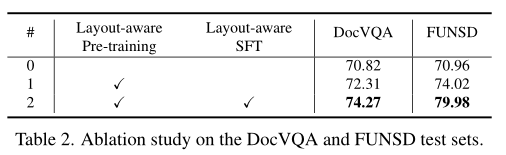
为了更好地验证布局感知预训练和布局感知SFT在布局指令调整中的有效性,进行了消融研究
Qualitative Results

图4给出了两个示例。通过结合布局感知预训练和布局感知SFT,LayoutLLM可以准确聚焦相关区域,利用布局信息辅助解决问题并提供可解释性。例如,在图4(a)中,关于上下布局中键值提取的问题,与左右布局不同,更多地依赖于文档布局来推断正确答案。由于问题中的关键词“所得税”经常与数值数据同时出现,Vicuna-1.5和Qwen-VL找到的数值答案更多地依赖于语义而不是布局,导致响应不正确。相反,得益于布局感知预训练,我们的模型可以有效利用布局信息来给出准确的答案。此外,使用LayoutCoT的模型可以进一步提供位置和推理过程,表现出一定的可解释性。但在某些情况下,仅结合布局预训练,我们的模型可能无法给出准确的答案。如图 4(b) 所示,如果没有 LayoutCoT,我们的模型会将“Exit 2003”识别为相关列并生成错误答案。 然而,在 LayoutCoT 的帮助下,LayoutLLM 可以正确识别问题类型为“表格”,找到相关的表格区域,并最终从相应的“Exit 2004”列推断出正确答案。
Interactive Correction with LayoutCoT
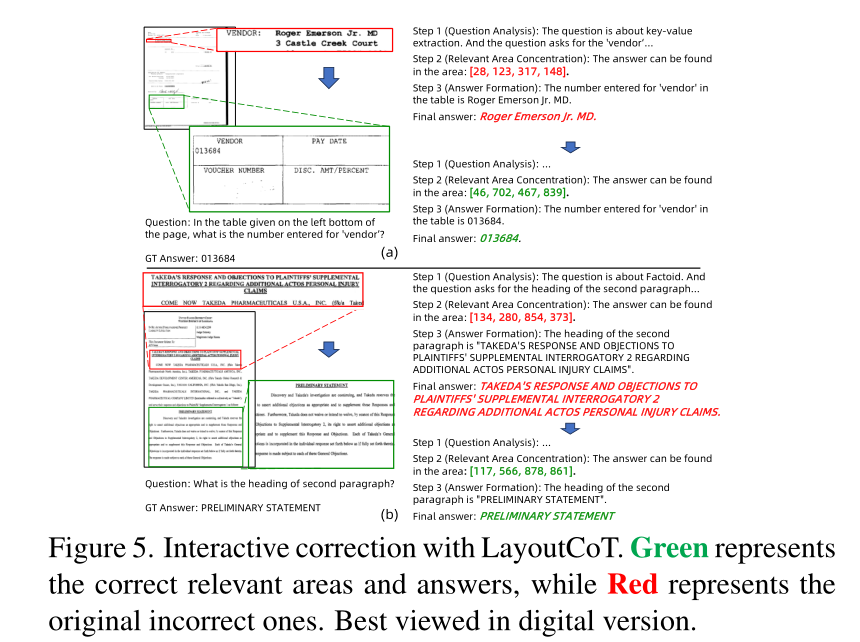
使用 LayoutCoT 进行交互式校正 由于 LayoutCoT 以逐步方式运行并在推理阶段产生中间结果,因此在处理文档时,它可以促进交互式检查和校正。如图5中,在图像中有两个区域与问题的关键字“供应商”相关。 LayoutCoT 关注了包含“供应商”的错误区域,因为它错过了问题中的“左下角”,所以答案不正确。然而,在手动给出正确的区域后,它终于可以给出正确的答案。
类似地,在图 5(b) 中,问题询问“第二段的标题”。然而,术语“段落”没有通用的定义,在这种情况下,主标题下方区域中的句子被视为段落,导致模型预测“TAKEDA 's…CLAIMS”,其中根据 GT 的说法是不正确的。一旦将正确的“第二段”区域输入模型,就可以成功修改答案。 LayoutCoT 的这种独特能力在高风险场景(例如银行交易)中非常有价值,因为这些场景的标准非常高,并且需要手动检查和纠正(即人机交互)。
4 限制
通过LayoutCoT,LayoutLLM展示了交互式校正的能力,但在实际应用中,这还不够。拒绝误报输出并生成提示(例如“文档中未提及答案”)的能力至关重要。然而,目前 LayoutLLM 中不存在该功能。此外,尽管通过布局感知预训练取得了显着的改进,但 LayoutLLM 在精确理解区域级关系方面仍存在困难,如图 5(a) 所示。



















 364
364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











