






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer2233,助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪必备!

一、论文信息

论文标题: Practical Compact Deep Compressed Sensing(实用、紧致的深度压缩感知)
论文作者: Bin Chen(陈斌) and Jian Zhang†(张健)(†通讯作者)
作者单位: 北京大学信息工程学院
发表刊物: IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
发表时间: 2024年11月22日
正式版本:
https://ieeexplore.ieee.org/document/10763443
ArXiv版本:
https://arxiv.org/abs/2411.13081
开源代码:
https://github.com/Guaishou74851/PCNet
二、任务背景
压缩感知(Compressed Sensing, CS)是一种信号降采样技术,可大幅节省图像获取成本。CS的核心思想是 “无需完整记录图像信息,通过计算即可还原目标图像”。CS的典型应用包括:
降低相机成本: 利用廉价设备就能拍摄出高质量图像;
加速医疗成像: 将核磁共振成像(MRI)时间从40分钟缩短至10分钟内,减少被检查者的不适;
探索未知世界,助力科学研究: 将“看不见”事物变为“看得见”,如观测细胞活动等转瞬即逝的微观现象,以及通过分布式射电望远镜观测银河系中心的黑洞。
CS的数学模型可表示为 ,其中 是原始图像, 是采样矩阵, 是观测值。定义压缩采样率为 。
CS面临两大核心问题:
如何设计采样矩阵,从而尽可能多地保留图像信息?
如何设计高效的重建算法,从而精准复原图像内容?
然而,现有CS方法仍存在两方面局限:
采样矩阵信息保留能力不足: 将图像切块,逐块采样,导致观测值信息量有限;
重建算法的计算开销过大、复原精度有限。
三、主要贡献
本工作提出了一种实用、紧致的图像压缩感知网络PCNet,具有如下创新点:
一种新型压缩采样矩阵,能够融合图像的局部与全局特征,从而提高信息保留能力。具体采样过程分两步:首先,用一个小型卷积网络对图像滤波;其次,使用全局矩阵对滤波结果降维,生成压缩观测值;
一种新型图像重建网络,将传统近端梯度下降(Proximal Gradient Descent,PGD)算法与深度神经网络有机结合,利用先进模块设计显著提升重建精度。
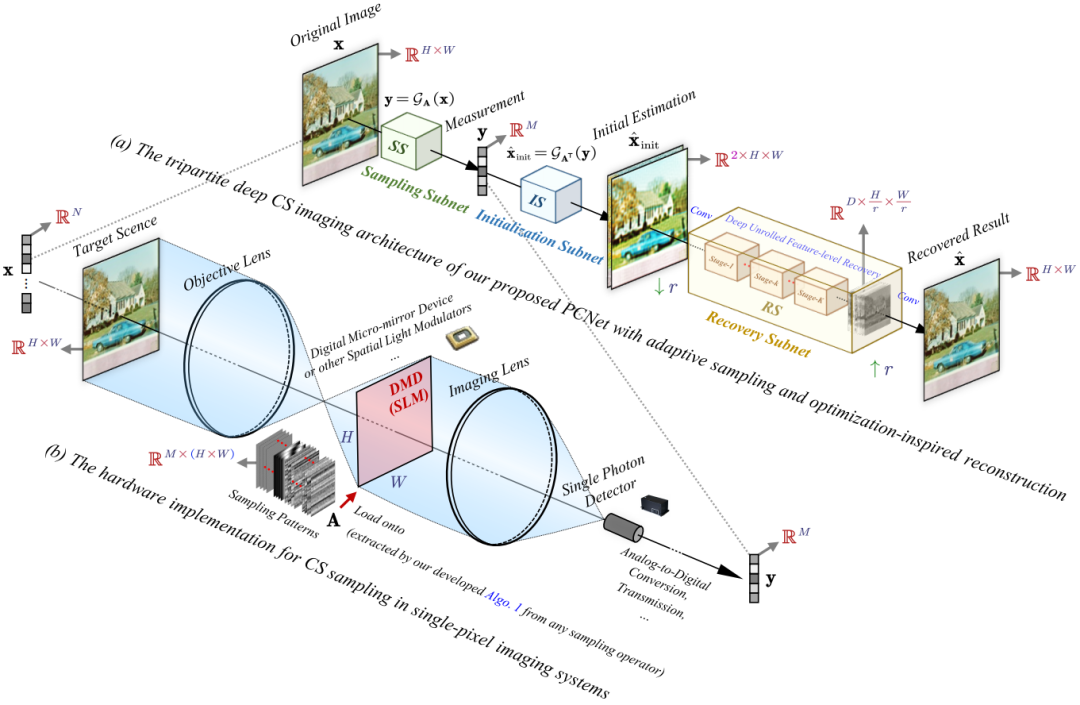
图1:提出的实用、紧致的压缩感知网络PCNet。
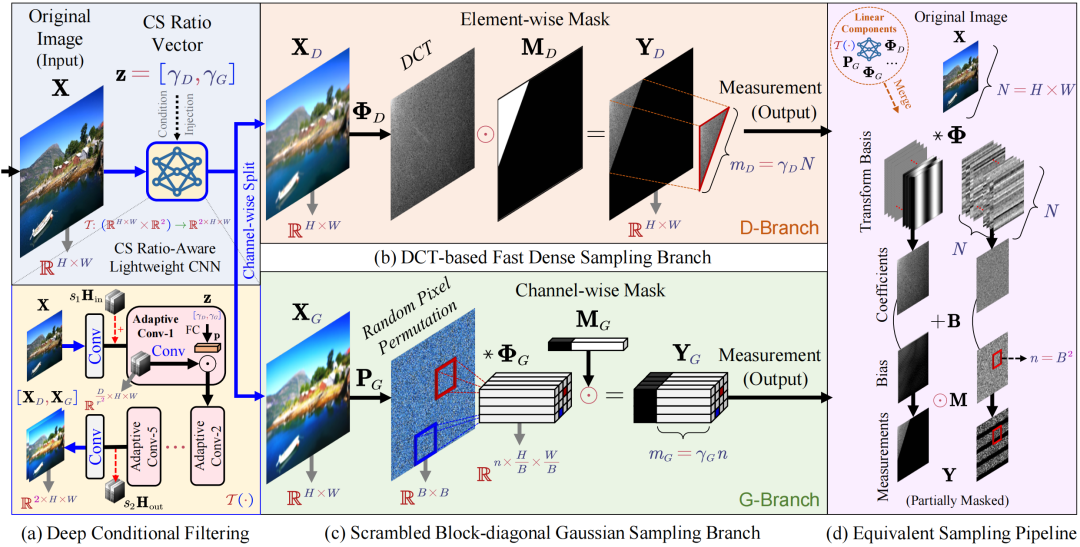
图2:提出的协同采样算子。
四、实验结果
在 Set11、CBSD68、Urban100 和 DIV2K 等基准数据集上,PCNet 的性能显著优于其他方法,特别是在高分辨率(2K、4K、8K)成像任务中。此外,其采样矩阵可拓展至量化CS和自监督CS任务,展现了良好的通用性。
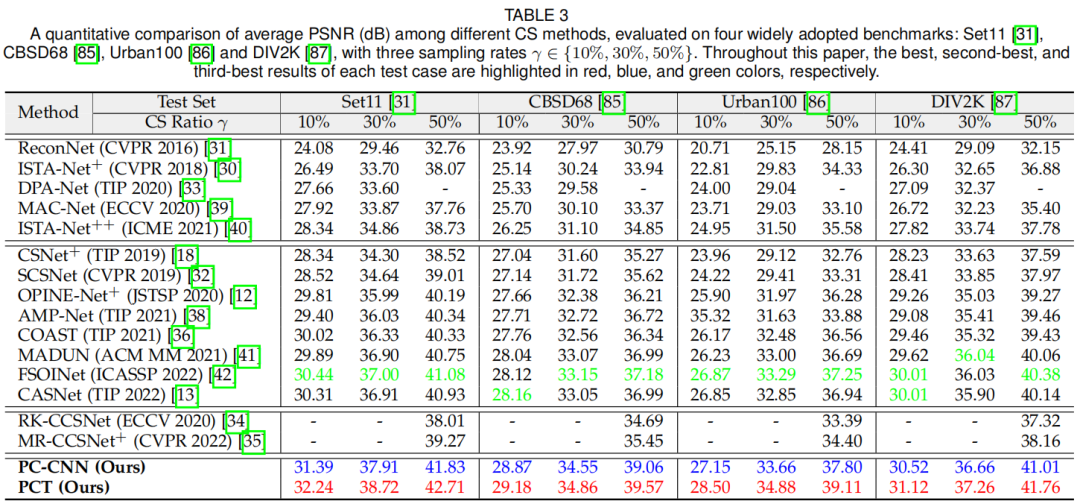

图3:方法与其他CS方法的对比结果。
更多细节、实验结果与理论分析请参阅论文。
五、实验室简介
视觉信息智能学习实验室(VILLA)由北京大学信息工程学院张健助理教授于2019年创立并负责,主要围绕“智能可控图像生成”这一前沿领域,深入开展高效图像重建、可控图像生成和精准图像编辑三个关键方向的研究。张健老师带领VILLA团队已在Nature子刊Communications Engineering、IEEE SPM、TPAMI、TIP、IJCV、NeurIPS、ICLR、CVPR、ICCV和ECCV等高水平国际期刊和会议上发表论文100余篇,其中近三年,以第一作者/通讯作者发表CCF A类论文40余篇。张健老师谷歌学术引用1万余次,h-index值为49(单篇一作最高引用1200余次),获得北大青年教师教学比赛一等奖、国际期刊/会议最佳论文奖五次,主持国家科技重大专项课题、国自然重点项目课题、国自然面上以及与字节/华为/OPPO/创维/兔展等知名企业学术合作项目10余项。
在高效图像重建方面,张健老师团队的代表性成果包括优化启发式深度展开重建网络ISTA-Net、COAST、ISTA-Net++,联合学习采样矩阵压缩计算成像方法OPINE-Net、PUERT、CASNet、HerosNet、PCA-CASSI,基于信息流增强机制的高通量广义优化启发式深度展开重建网络HiTDUN、SODAS-Net、MAPUN、DGUNet、SCI3D、PRL、OCTUF、D3C2-Net,以及无需真值的自监督图像重建方法SCNet。团队还提出了基于自适应路径选择机制的动态重建网络DPC-DUN和用于单像素显微荧光计算成像的深度压缩共聚焦显微镜DCCM,以及生成式图像复原方法Panini-Net、PDN、DEAR-GAN、DDNM,受邀在信号处理领域旗舰期刊SPM发表专题综述论文。本工作提出的实用、紧致的压缩感知网络PCNet进一步提升了图像压缩感知的精度与效率。
更多信息可访问VILLA实验室主页(https://villa.jianzhang.tech/)或张健助理教授个人主页(https://jianzhang.tech/cn/)。
(供稿人:陈斌,北京大学博士生)
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看
















 6793
6793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









