



点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer2233,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

引言
推理能力的进步极大提升了大语言模型(LLMs)和多模态大语言模型(MLLMs)在各类任务中的表现。但过度依赖思维链(CoT)推理会降低模型性能,产生冗长输出,影响效率。研究发现,长CoT推理并非总能提升准确率,甚至会削弱模型处理简单任务的能力。为此,我们提出基于置信度的自适应推理框架(CAR),它能根据模型困惑度动态选择短回答或详细的长文本推理:首先生成简短回答并评估困惑度,仅在模型置信度低(困惑度高)时触发推理。在多模态视觉问答、关键信息提取及文本推理等多个基准测试中,CAR超越了单纯的短回答与长推理方法,实现了准确性与效率的最佳平衡。


论文:https://arxiv.org/abs/2505.15154
相关工作
CAR是第一个自动化切换长短推理的方案。和CAR最相关的领域,应该是缩减推理过程中的Token数量的方案,旨在解决推理过程中Token过多带来的计算损耗增加的问题。Concise Thoughts[1] 采用固定的全局Token预算限制Token的生成数量,而Token-Budget-Aware的 LLM 推理方式(TALE)[2] 则根据问题复杂度动态调整Token的数量预算。然而,这些方法可能会引入额外的 LLM 调用,或面临不切实际的Token数目限制。此外,Chain of Draft (CoD)[3] 通过生成最少中间步骤来减少冗长性,在不影响准确性的前提下显著降低输出Token的数量。近期,也有工作提出并行化推理的方法[4]以及牺牲可解释性完成预测Token数目缩减的方法[5,6]。
先导实验
先导实验设置
我们在文本密集型视觉问答(VQA) 和 关键信息抽取(KIE) 领域展开先导实验,选取 8 个代表性数据集用于实验。其中包含VQA 数据集:DocVQA、InfoVQA、ChartQA、VisualMRC(涵盖文档、图表、信息图等多类型视觉文本);KIE 数据集:SROIE、CORD、FUNSD、POIE(聚焦票据、表格等结构化信息抽取)。
基于上述数据,我们对 Qwen2.5-0.5B 进行微调,在域内(DocVQA、ChartQA 等) 和域外(POIE、InfoVQA 等)数据集上评估性能,要求模型生成两种响应:简短答案(提示词:"Please directly output the answer")和长文本推理 + 答案(提示词:"Please output the reasoning process before outputting the answer")。评估完成后,我们统计了对应数据集的准确率(Accuracy)和相应的回答的困惑度(PPL),其中 PPL 越低表示模型对答案的置信度越高。
图1 数据集PPL scores vs. accuracy |
图2 各数据集上PPL与回答对错的分布图 |
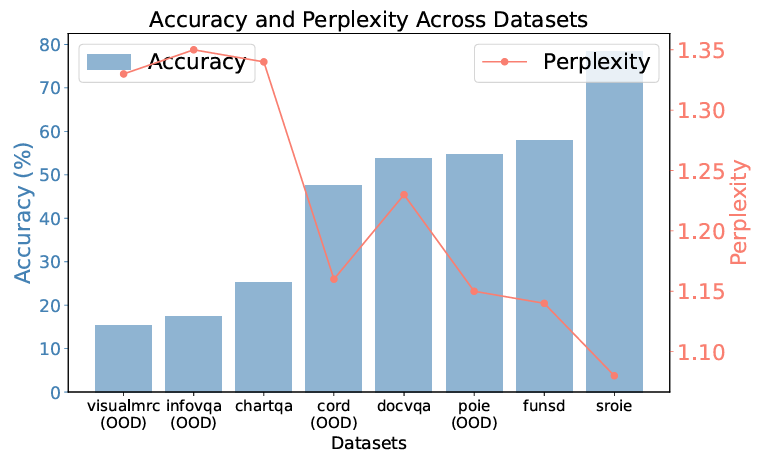
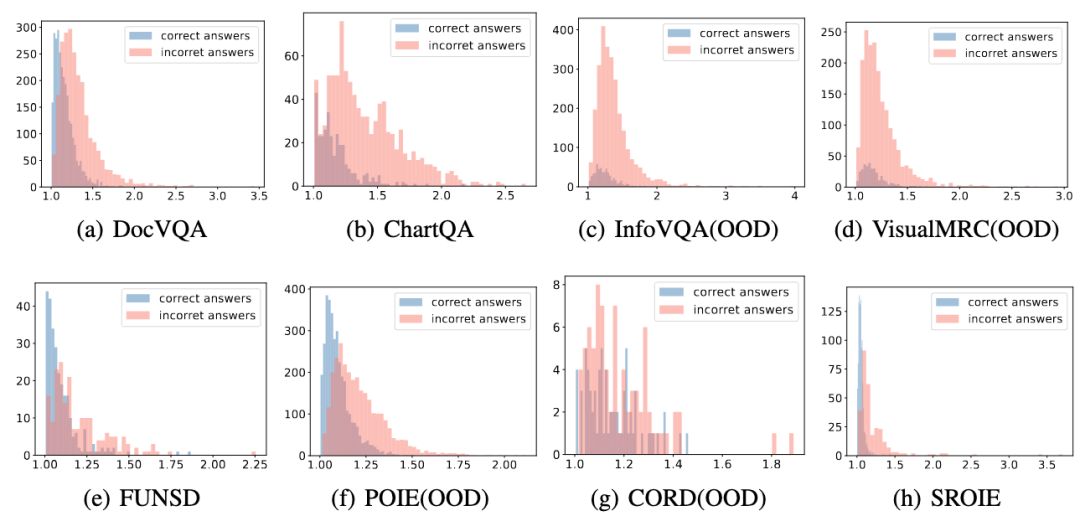
实验发现:PPL 与准确率存在强负相关性。通过分析数据集级别的准确率与 PPL 关系,我们发现二者呈现显著逆相关(如图 1 所示):准确率越高的数据集,平均 PPL 越低。此外如图2所示,我们发现数据集内部,预测正确的examples的平均PPL score也是低于预测错误的examples的平均PPL score。
上述实验揭示了PPL 作为模型置信度指标的潜力。因此,我们首先提出一个基础的基于 PPL 的动态推理决策,即低置信度场景(PPL 超过阈值)下触发长文本推理,避免草率决策;在高置信度场景,直接输出简短答案,提升推理效率。具体地,我们以测试集 PPL 分布的 75% 分位数作为阈值来评估性能(如表1所示)。实验发现模型在绝大多数数据集上均有明显性能提升。

表1 PPL取75%分位数为阈值下的性能对比
方法(Certainty-based Adaptive Reasoning)
基于上述探索性的发现,本文将利用它们作为基础,开发一个使用困惑度(PPL)的动态推理决策框架Certainty-based Adaptive Reasoning(CAR),其目标是能够在推理过程中自适应地在短文本推理和长文本推理之间切换。通过避免冗余计算,这种方法将显著提高模型的推理效率和准确性。如图3(a)所示,我们首先使用包含简短答案的示例和包含长文本推理解答的示例来训练大语言模型(LLM)或多模态大语言模型(MLLM)。随后,借助训练集的困惑度(PPL),我们估计正确和错误简短答案的PPL分布,这些分布用于决策制定。具体来说,如果估计的分布确定简短答案是正确的,所提出的方法会直接输出该正确答案。否则,它会执行长文本推理。推理过程如图3(b)所示。
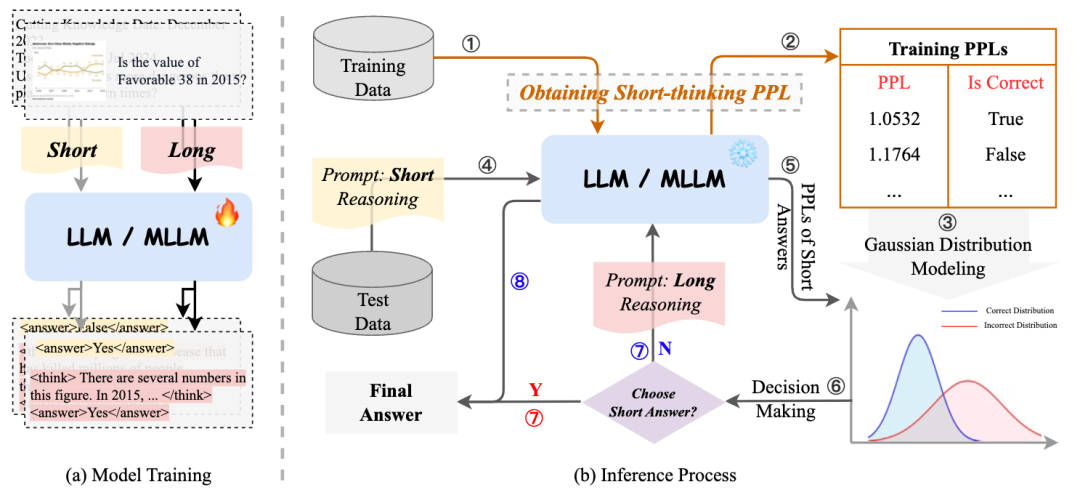
图3 CAR模型的训练与推理过程示意图
模型训练 我们将同时包含简短答案和长文本推理解答标注的训练示例进行混合,构建新的数据集。为引导模型生成简短答案,使用指令:"Please directly output the answer";若需生成带推理过程的长文本答案,则使用指令:"Please output the reasoning process before outputting the answer"。随后采用标准指令微调流程,模型接收由输入文本和输出文本组成的序列,优化目标为交叉熵损失:
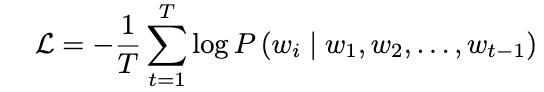
模型训练完成后,对训练集中所有样本进行短答案推理,生成预测答案 并计算其困惑度值PPL。Token 序列的困惑度定义为:
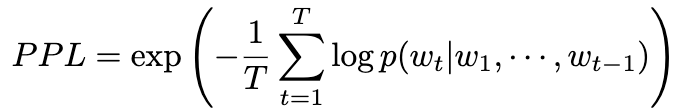
高斯分布建模 设二元变量C表示短答案是否正确(C=1为正确,C=0为错误),假设正确与错误答案的 PPL 分布均服从高斯分布:
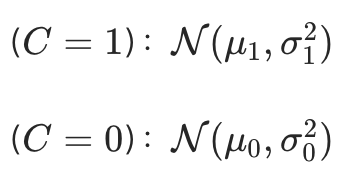
概率密度函数分别为:
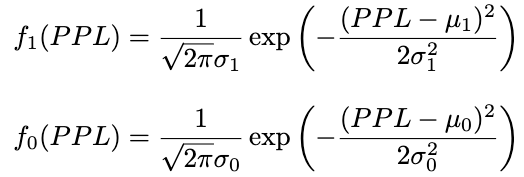
最后,通过训练数据估计其中参数(假设n_1和n_0分别为训练集中正确与错误回答的数量):
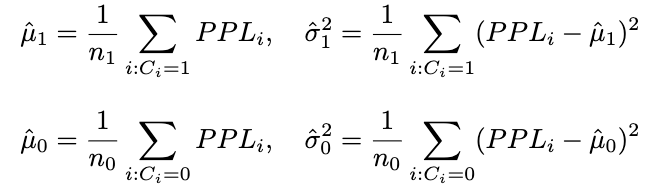
推理过程 对新输入x,推理步骤如下:
1. 短回答推理:模型生成短回答,并计算相应的PPL为PPL_new;
2. 概率计算:根据贝叶斯定理,将PPL_new代入概率密度函数,计算后验概率;
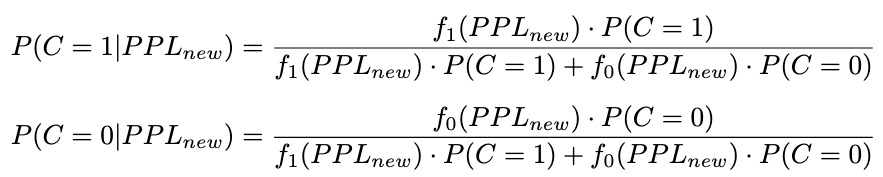
其中,先验概率分别为:
|
|

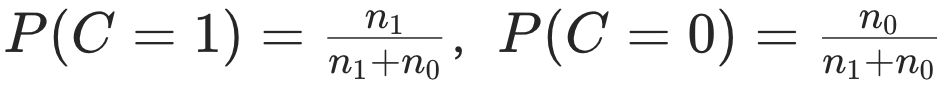
3.决策规则:如果短回答的正确概率高于其可能错误的概率,直接输出短回答;否则触发模型的长推理。
实验结果
实现细节
我们采用Qwen2-VL-7B-Instruct作为多模态语言模型,并使用Qwen2.5-7B-Instruct和Llama3.1-8B-Instruct作为大语言模型,分别命名为CAR$_{Qwen2VL}、CAR$_{Qwen2.5}和CAR$_{Llama3.1}。所有模型均训练3个 epoch,使用批量大小为32、学习率为1e-6的AdamW优化器。最大输入和输出序列长度分别设置为4096和1024。训练在8块NVIDIA A100 GPU上进行。 为消除随机性影响,所有模型在测试期间均不使用采样方法,且统一采用beam search=1生成。此外,生成的最大token数设置为1024,最大输入token数设置为4096。
为了验证我们所提出方法的有效性,我们在三个多模态数据集上进行了实验:DocVQA、ChartQA 和 FUNSD。与之前章节的先导实验不同,这里我们输入图像模态数据,并使用多模态大语言模型进行性能评估。由于这些数据集缺乏推理过程标注,我们复用了先导实验中获得的推理过程数据。此外,我们还在文本数据集上对CAR方法进行了评估,选取了三个广泛使用的推理数据集:数学推理数据集GSM8K和MathQA,以及常识推理数据集StrategyQA。
多模态数据集性能比较
表2展示了多模态数据集上的性能表现。首先,CAR_{Qwen2VL}相比CAR_{Short}和CAR_{Long}的优越性能,证明了使用困惑度(PPL)作为推理路径选择指标的有效性。此外,CAR_{Qwen2VL}实现了77.9%的最高平均准确率,分别比基线模型Qwen2VL_{Short}和Qwen2VL_{Long}提升了2.8%和5.5%。值得注意的是,我们的方法保持了还具备较少的Token使用(平均86.9个token),仅为Qwen2VL_{Long}所使用Token数量的15%。这些结果表明了CAR在多模态场景中的实用性。
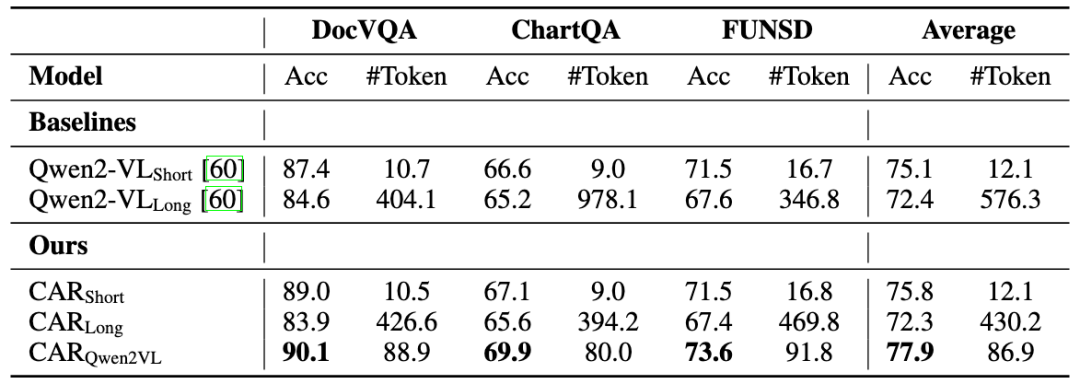
表2 多模态数据集上的性能比较
文本数据集性能比较
表3和4展示了基于文本的推理任务性能对比。CAR方法表现出稳健的性能。具体地,使用Qwen2.5-7B模型时平均准确率达81.1%,使用Llama3.1-8B时达74.9%,均优于简短答案基线模型(55.8%和51.5%)以及长文本推理模型(75.0%和70.8%)。值得注意的是,与仅长文本推理相比,CAR的Token使用量分别减少了45.1%(采用Qwen2.5模型)和45.6%(采用Llama3.1模型)。在Qwen2.5模型中,CAR_{Qwen2.5}始终优于CAR_{Qwen2.5-Short}和CAR_{Qwen2.5-Long},再次证明了使用困惑度(PPL)作为路径选择指标的有效性。
此外,CAR的性能均优于TALE和COD等先进的Token缩减方法。具体而言,在Qwen2.5模型上,CAR的平均准确率比TALE高8.3%,比COD高6.9%,同时保持最低的Token使用数量(即69.2个Token)。类似地,在Llama3.1模型上,CAR的平均准确率分别比TALE和COD高6.6%和5.5%,且生成的token数量最少。
值得注意的是,CAR的自适应路由在MathQA数据集上尤其有效(如Llama3.1模型下70.2% vs. COD的59.1%,Qwen2.5模型下83.8% vs. COD的67.1%),这一现象的潜在原因是提出的CAR模型消除了不必要的推理步骤。其凸显了CAR在不同推理范式中的实用性。
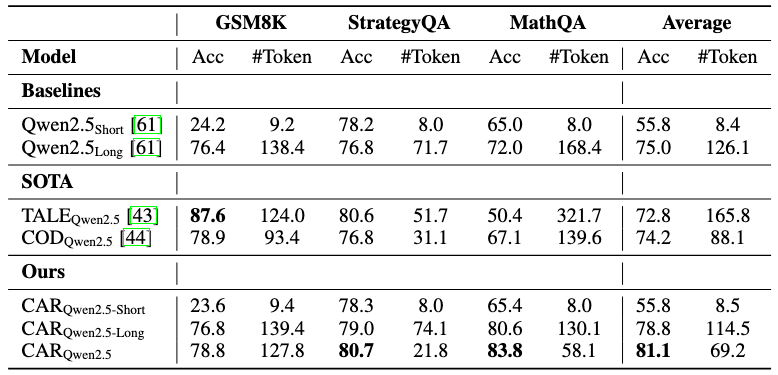
表3 文本数据集上的性能比较(基于Qwen2.5模型)
表4 文本数据集上的性能比较(基于Llama3.1模型)
融合TALE方法后的性能比较
我们额外探索了将 CAR 框架与 TALE 等Token 缩减技术结合的可行性,通过用 TALE 生成的简短推理步骤替代原始推理过程,在 Qwen2.5-7B 和 Llama3.1-8B 上构建了 CAR-TALE 系列变体。表5与表6的结果表明:在Qwen2.5 模型上,CAR 与 TALE 结合后,平均准确率从 78.8% 提升至 85.5%(+6.7%),生成 token 数从 127.8 减少至 111.3,实现性能与效率双提升;在Llama3.1 模型上,结合 TALE 后,平均准确率从 71.6% 提升至 80.8%(+9.2%),验证了融合方案的有效性。实验证明,CAR 与 Token 缩减技术具有协同优势,通过自适应推理框架的动态路径选择与推理Token缩减的技术结合,可进一步优化大模型推理的效率与准确性。
表5 融合TALE方案的CAR性能比较(基于Qwen2.5) |
表6 融合TALE方案的CAR性能比较(基于Llama3.1) |
总结
我们提出基于置信度的自适应推理框架(CAR),该框架可根据模型置信度动态切换短回答与长文本推理模式。通过困惑度(PPL)量化模型对答案的置信度,CAR在高置信度时直接输出短回答以提升效率,低置信度时触发长文本推理以确保准确性。实验表明,在多模态(如DocVQA、ChartQA)和文本推理(如GSM8K、MathQA)任务中,CAR的token使用量较纯长文本推理减少45%以上,平均准确率提升6%-8%,在Qwen2.5、Llama3.1等模型上均优于基线方法,尤其在数学推理任务中显著减少冗余步骤。CAR打破了“长文本推理必然性能更好”的固有认知,为大模型推理提供了更灵活高效的解决方案,推动大模型推理向智能化、轻量化方向发展。
参考文献
[1] Nayab, Sania, et al. "Concise thoughts: Impact of output length on llm reasoning and cost." arXiv preprint arXiv:2407.19825 (2024).
[2] Han, Tingxu, et al. "Token-budget-aware llm reasoning." arXiv preprint arXiv:2412.18547 (2024).
[3] Xu, Silei, et al. "Chain of draft: Thinking faster by writing less." arXiv preprint arXiv:2502.18600 (2025).
[4] Ning, Xuefei, et al. "Skeleton-of-thought: Large language models can do parallel decoding." Proceedings ENLSP-III (2023).
[5] Hao, Shibo, et al. "Training large language models to reason in a continuous latent space." arXiv preprint arXiv:2412.06769 (2024).
[6] Shen, Zhenyi, et al. "Codi: Compressing chain-of-thought into continuous space via self-distillation." arXiv preprint arXiv:2502.21074 (2025).
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
CVPR 2025 论文和代码下载
在CVer公众号后台回复:CVPR2025,即可下载CVPR 2025论文和代码开源的论文合集ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集
CV垂直方向和论文投稿交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-垂直方向和论文投稿微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。 一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者论文投稿+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)人数破万!如果你想要了解最新最快最好的CV/DL/AI论文、实战项目、行业前沿、从入门到精通学习教程等资料,一定要扫描下方二维码,加入CVer知识星球!最强助力你的科研和工作!
▲扫码加入星球学习
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)人数破万!如果你想要了解最新最快最好的CV/DL/AI论文、实战项目、行业前沿、从入门到精通学习教程等资料,一定要扫描下方二维码,加入CVer知识星球!最强助力你的科研和工作!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号 整理不易,请点赞和在看

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









