% matplotlib inline
import re
import os
import jieba
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib. pyplot as plt
from pylab import rcParams
from matplotlib import rc
from collections import defaultdict
from sklearn. metrics import confusion_matrix, classification_report
from sklearn. model_selection import train_test_split
import torchtext
from torchtext import vocab
from torchtext. legacy import data
from torchtext. legacy import datasets
import torch
from torch. utils. data import random_split
import torch. nn as nn
import torch. optim as optim
import torch. nn. functional as F
RANDOM_SEED = 2022
np. random. seed( RANDOM_SEED)
torch. manual_seed( RANDOM_SEED)
device = torch. device( "cuda:0" if torch. cuda. is_available( ) else "cpu" )
device
device(type='cpu')
df_review = pd. read_csv( './data/dataset.csv' )
df_review. head( )
text\tlabel 0 酒店设计有特色,房间很舒服亦很美,位置于南门很方便出入,而且又有得免费上网。前台服务员不错,... 1 地理位置不错,闹中取静。房间比较干净,布局合理。但是隔音效果太差了,有住简易客栈的感觉。临水... 2 不错,下次还考虑入住。交通也方便,在餐厅吃的也不错。\t正向 3 地理位置比较便捷,逛街、旅游、办事都比较方便。老的宾馆新装修改的,房间内的设施简洁、干净,但... 4 因为只住了一晚,所以没什么感觉,差不多四星吧。大堂的地砖很漂亮。房间小了一点。\t正向
df_review. iloc[ 0 , 0 ]
'酒店设计有特色,房间很舒服亦很美,位置于南门很方便出入,而且又有得免费上网。前台服务员不错,唯退房时出了点问题,令大打折扣。事缘我们有饮用酒店雪柜内的汽水,但临退房前已经买回一样的饮品放进去,但酒店说汽水的包装不一样,所以必须收我们钱,最终由查房、收钱、拿回我们的汽水花了我二十分钟,刚刚我又要赶车,很气愤!我们一共住了三天,花了千多元,那几元都要和我们收足,很讨厌!\t正向'
df_review[ 'text' ] , df_review[ 'label' ] = zip ( * df_review[ 'text\tlabel' ] . str . split( '\t' ) )
del df_review[ 'text\tlabel' ]
df_review. head( )
text label 0 酒店设计有特色,房间很舒服亦很美,位置于南门很方便出入,而且又有得免费上网。前台服务员不错,... 正向 1 地理位置不错,闹中取静。房间比较干净,布局合理。但是隔音效果太差了,有住简易客栈的感觉。临水... 正向 2 不错,下次还考虑入住。交通也方便,在餐厅吃的也不错。 正向 3 地理位置比较便捷,逛街、旅游、办事都比较方便。老的宾馆新装修改的,房间内的设施简洁、干净,但... 正向 4 因为只住了一晚,所以没什么感觉,差不多四星吧。大堂的地砖很漂亮。房间小了一点。 正向
cate = pd. Categorical( df_review[ 'label' ] )
df_review[ 'label' ] = cate. codes
df_review. head( )
text label 0 酒店设计有特色,房间很舒服亦很美,位置于南门很方便出入,而且又有得免费上网。前台服务员不错,... 0 1 地理位置不错,闹中取静。房间比较干净,布局合理。但是隔音效果太差了,有住简易客栈的感觉。临水... 0 2 不错,下次还考虑入住。交通也方便,在餐厅吃的也不错。 0 3 地理位置比较便捷,逛街、旅游、办事都比较方便。老的宾馆新装修改的,房间内的设施简洁、干净,但... 0 4 因为只住了一晚,所以没什么感觉,差不多四星吧。大堂的地砖很漂亮。房间小了一点。 0
df_review. isna( ) . sum ( )
text 0
label 0
dtype: int64
df_review. duplicated( ) . sum ( )
0
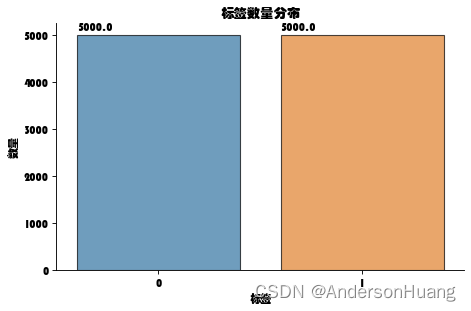
df_review[ 'label' ] . value_counts( )
0 5000
1 5000
Name: label, dtype: int64
plt. rcParams[ 'font.sans-serif' ] = [ 'STHUPO' ]
plt. rcParams[ 'axes.unicode_minus' ] = False
fig, ax = plt. subplots( figsize= ( 6 , 4 ) , dpi= 80 )
sns. countplot( x= df_review. label, edgecolor= "black" , alpha= 0.7 , data= df_review)
sns. despine( )
plt. xlabel( '标签' )
plt. ylabel( '数量' )
plt. title( "标签数量分布" )
plt. tight_layout( )
for p in ax. patches:
ax. annotate( f'\n { p. get_height( ) } ' , ( p. get_x( ) , p. get_height( ) + 100 ) , color= 'black' , size= 10 )
df_review[ 'text_len' ] = df_review[ 'text' ] . map ( len )
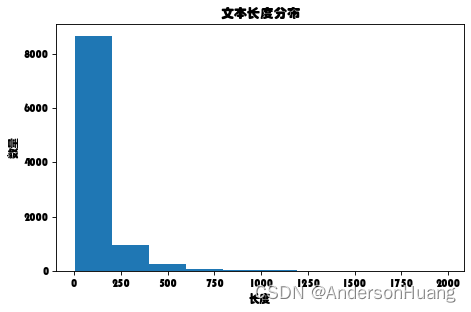
df_review[ 'text_len' ] . describe( )
count 10000.000000
mean 109.083700
std 126.177622
min 4.000000
25% 34.000000
50% 69.000000
75% 135.000000
max 1985.000000
Name: text_len, dtype: float64
plt. rcParams[ 'font.sans-serif' ] = [ 'STHUPO' ]
plt. rcParams[ 'axes.unicode_minus' ] = False
fig, ax = plt. subplots( figsize= ( 6 , 4 ) , dpi= 80 )
plt. xlabel( '长度' )
plt. ylabel( '数量' )
plt. title( "文本长度分布" )
plt. tight_layout( )
plt. hist( df_review[ 'text_len' ] , bins= 10 )
(array([8.672e+03, 9.680e+02, 2.440e+02, 7.700e+01, 1.800e+01, 1.600e+01,
3.000e+00, 0.000e+00, 0.000e+00, 2.000e+00]),
array([ 4. , 202.1, 400.2, 598.3, 796.4, 994.5, 1192.6, 1390.7,
1588.8, 1786.9, 1985. ]),
<BarContainer object of 10 artists>)
sum ( df_review[ 'text_len' ] > 500 )
205
def remove_pun ( line) :
rule = re. compile ( u"[^a-zA-Z0-9\u4E00-\u9FA5]" )
line = rule. sub( '' , line)
return line
stopwords = [ line. strip( ) for line in open ( './data/中文停用词库.txt' , 'r' , encoding= 'utf-8' ) . readlines( ) ]
df_review[ 'clean_text' ] = df_review[ 'text' ] . map ( lambda x: remove_pun( x) )
df_review[ 'cut_text' ] = df_review[ 'clean_text' ] . apply ( lambda x: " " . join( w for w in jieba. lcut( x) if w not in stopwords) )
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.622 seconds.
Prefix dict has been built successfully.
df_review. head( )
text label text_len clean_text cut_text 0 酒店设计有特色,房间很舒服亦很美,位置于南门很方便出入,而且又有得免费上网。前台服务员不错,... 0 184 酒店设计有特色房间很舒服亦很美位置于南门很方便出入而且又有得免费上网前台服务员不错唯退房时出... 酒店设计 特色 房间 舒服 美 位置 南门 出入 免费 上网 前台 服务员 不错 唯 退房 ... 1 地理位置不错,闹中取静。房间比较干净,布局合理。但是隔音效果太差了,有住简易客栈的感觉。临水... 0 119 地理位置不错闹中取静房间比较干净布局合理但是隔音效果太差了有住简易客栈的感觉临水的房间风景不... 地理位置 不错 闹中取静 房间 干净 布局合理 隔音 效果 太差 住 简易 客栈 感觉 临水... 2 不错,下次还考虑入住。交通也方便,在餐厅吃的也不错。 0 26 不错下次还考虑入住交通也方便在餐厅吃的也不错 不错 下次 入住 交通 餐厅 吃 不错 3 地理位置比较便捷,逛街、旅游、办事都比较方便。老的宾馆新装修改的,房间内的设施简洁、干净,但... 0 59 地理位置比较便捷逛街旅游办事都比较方便老的宾馆新装修改的房间内的设施简洁干净但宾馆整体建筑设... 地理位置 便捷 逛街 旅游 办事 宾馆 新装 修改 房间内 设施 简洁 干净 宾馆 整体 建... 4 因为只住了一晚,所以没什么感觉,差不多四星吧。大堂的地砖很漂亮。房间小了一点。 0 39 因为只住了一晚所以没什么感觉差不多四星吧大堂的地砖很漂亮房间小了一点 只住 一晚 没什么 感觉 四星 大堂 地砖 很漂亮 房间 一点
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
from PIL import Image
background_image = np. array( Image. open ( "data/pl.jpg" ) )
fig, ax = plt. subplots( figsize= ( 12 , 8 ) , dpi= 100 )
mytext = ''
for i in range ( len ( df_review) ) :
mytext += df_review[ 'text' ] [ i]
wcloud = WordCloud( width= 2400 , height= 1600 ,
background_color= "white" ,
stopwords= stopwords,
font_path= "data/STHUPO.TTF" ,
mask = background_image)
wcloud = wcloud. generate( mytext)
plt. imshow( wcloud)
plt. axis( 'off' )
(-0.5, 1023.5, 857.5, -0.5)
df_train, df_test = train_test_split( df_review, test_size= 0.2 , random_state= RANDOM_SEED)
df_val, df_test = train_test_split( df_test, test_size= 0.5 , random_state= RANDOM_SEED)
df_train. shape, df_val. shape, df_test. shape
((8000, 5), (1000, 5), (1000, 5))
class ReviewDataset ( data. Dataset) :
def __init__ ( self, df, fields, is_test= True , ** kwargs) :
examples = [ ]
for i, row in df. iterrows( ) :
label = row. label
text = row. cut_text
examples. append( data. Example. fromlist( [ text, label] , fields) )
super ( ) . __init__( examples, fields, ** kwargs)
@staticmethod
def sort_key ( ex) :
return len ( ex. text)
@classmethod
def splits ( cls, fields, train_df, val_df= None , test_df= None , ** kwargs) :
train_data, val_data, test_data = ( None , None , None )
data_field = fields
if train_df is not None :
train_data = cls( train_df. copy( ) , data_field, ** kwargs)
if val_df is not None :
val_data = cls( val_df. copy( ) , data_field, ** kwargs)
if test_df is not None :
test_data = cls( test_df. copy( ) , data_field, True , ** kwargs)
return tuple ( d for d in ( train_data, val_data, test_data) if d is not None )
TEXT = data. Field( sequential= True , lower= True , fix_length= 500 , tokenize= str . split, batch_first= True )
LABEL = data. LabelField( dtype= torch. float )
fields = [ ( 'text' , TEXT) , ( 'label' , LABEL) ]
train_ds, val_ds , test_ds= ReviewDataset. splits( fields, train_df= df_train, val_df= df_val, test_df= df_test)
print ( vars ( train_ds[ 666 ] ) )
{'text': ['酒店', '位置', '没得说', '静安寺', '边上', '房间', '里', '一股', '子', '怪味', '窗上', '纱窗', '一夜', '两臂', '苍蝇', '蚊子', '叮出', '大包', '点着', '蚊香', '国营企业', '德行'], 'label': 1}
print ( type ( train_ds[ 666 ] ) )
<class 'torchtext.legacy.data.example.Example'>
pretrained_name = 'sgns.sogou.word'
pretrained_path = './model/'
vectors = torchtext. vocab. Vectors( name= pretrained_name, cache= pretrained_path)
0%| | 0/364990 [00:00<?, ?it/s]Skipping token b'364990' with 1-dimensional vector [b'300']; likely a header
100%|██████████| 364990/364990 [00:22<00:00, 16418.00it/s]
MAX_VOCAB_SIZE = 25000
TEXT. build_vocab( train_ds,
max_size = MAX_VOCAB_SIZE,
vectors = vectors,
unk_init = torch. Tensor. zero_)
LABEL. build_vocab( train_ds)
BATCH_SIZE = 128
train_iterator, valid_iterator, test_iterator = data. BucketIterator. splits( ( train_ds, val_ds, test_ds) ,
batch_size= BATCH_SIZE,
device= device)
class TextCNN ( nn. Module) :
def __init__ ( self,
class_num,
filter_sizes,
filter_num,
vocabulary_size,
embedding_dimension,
vectors,
dropout) :
super ( TextCNN, self) . __init__( )
chanel_num = 1
self. embedding = nn. Embedding( vocabulary_size, embedding_dimension)
self. embedding = self. embedding. from_pretrained( vectors)
self. convs = nn. ModuleList(
[ nn. Conv2d( chanel_num, filter_num, ( fsz, embedding_dimension) ) for fsz in filter_sizes] )
self. dropout = nn. Dropout( dropout)
self. fc = nn. Linear( len ( filter_sizes) * filter_num, class_num)
def forward ( self, x) :
x = self. embedding( x)
x = x. unsqueeze( 1 )
x = [ conv( x) for conv in self. convs]
x = [ sub_x. squeeze( 3 ) for sub_x in x]
x = [ F. relu( sub_x) for sub_x in x]
x = [ F. max_pool1d( sub_x, sub_x. size( 2 ) ) for sub_x in x]
x = [ sub_x. squeeze( 2 ) for sub_x in x]
x = torch. cat( x, 1 )
x = self. dropout( x)
logits = self. fc( x)
return logits
class_num = len ( LABEL. vocab)
filter_size = [ 2 , 3 , 4 ]
filter_num = 64
vocab_size = len ( TEXT. vocab)
embedding_dim = TEXT. vocab. vectors. size( ) [ - 1 ]
vectors = TEXT. vocab. vectors
dropout = 0.5
learning_rate = 0.001
epochs = 5
save_dir = './model/'
steps_show = 20
steps_eval = 100
early_stopping = 1000
textcnn_model = TextCNN( class_num= class_num,
filter_sizes= filter_size,
filter_num= filter_num,
vocabulary_size= vocab_size,
embedding_dimension= embedding_dim,
vectors= vectors,
dropout= dropout)
class_num
2
def train ( train_iter, dev_iter, model) :
if torch. cuda. is_available( ) :
model. cuda( )
optimizer = torch. optim. Adam( model. parameters( ) , lr= learning_rate)
steps = 0
best_acc = 0
last_step = 0
model. train( )
for epoch in range ( 1 , epochs + 1 ) :
for batch in train_iter:
feature, target = batch. text, batch. label
if torch. cuda. is_available( ) :
feature, target = feature. cuda( ) , target. cuda( )
optimizer. zero_grad( )
logits = model( feature)
loss = F. cross_entropy( logits, target. to( torch. int64) )
loss. backward( )
optimizer. step( )
steps += 1
if steps % steps_show == 0 :
corrects = ( torch. max ( logits, 1 ) [ 1 ] . view( target. size( ) ) . data == target. data) . sum ( )
train_acc = 100.0 * corrects / batch. batch_size
print ( 'steps:{} - loss: {:.6f} acc:{:.4f}' . format ( steps, loss. item( ) , train_acc) )
if steps % steps_eval == 0 :
dev_acc = dev_eval( dev_iter, model)
if dev_acc > best_acc:
best_acc = dev_acc
last_step = steps
print ( 'Saving best model, acc: {:.4f}%\n' . format ( best_acc) )
save( model, save_dir, steps)
else :
if steps - last_step >= early_stopping:
print ( '\n提前停止于 {} steps, acc: {:.4f}%' . format ( last_step, best_acc) )
raise KeyboardInterrupt
def dev_eval ( dev_iter, model) :
model. eval ( )
corrects, avg_loss = 0 , 0
for batch in dev_iter:
feature, target = batch. text, batch. label
if torch. cuda. is_available( ) :
feature, target = feature. cuda( ) , target. cuda( )
logits = model( feature)
loss = F. cross_entropy( logits, target. to( torch. int64) )
avg_loss += loss. item( )
corrects += ( torch. max ( logits, 1 ) [ 1 ] . view( target. size( ) ) . data == target. data) . sum ( )
size = len ( dev_iter. dataset)
avg_loss /= size
accuracy = 100.0 * corrects / size
print ( '\nEvaluation - loss: {:.6f} acc: {:.4f}%({}/{}) \n' . format ( avg_loss, accuracy, corrects, size) )
return accuracy
def save ( model, save_dir, steps) :
if not os. path. isdir( save_dir) :
os. makedirs( save_dir)
save_path = 'bestmodel_steps{}.pt' . format ( steps)
save_bestmodel_path = os. path. join( save_dir, save_path)
torch. save( model. state_dict( ) , save_bestmodel_path)
train( train_iterator, valid_iterator, textcnn_model)
steps:20 - loss: 0.416524 acc:82.8125
steps:40 - loss: 0.378324 acc:85.1562
steps:60 - loss: 0.327376 acc:86.7188
steps:80 - loss: 0.236540 acc:92.1875
steps:100 - loss: 0.338137 acc:84.3750
Evaluation - loss: 0.002457 acc: 87.5000%(875/1000)
Saving best model, acc: 87.5000%
steps:120 - loss: 0.243032 acc:89.0625
steps:140 - loss: 0.235221 acc:90.6250
steps:160 - loss: 0.176186 acc:92.9688
steps:180 - loss: 0.214169 acc:92.1875
steps:200 - loss: 0.167112 acc:96.8750
Evaluation - loss: 0.002242 acc: 89.0000%(890/1000)
Saving best model, acc: 89.0000%
steps:220 - loss: 0.183157 acc:95.3125
steps:240 - loss: 0.110481 acc:97.6562
steps:260 - loss: 0.122785 acc:96.8750
steps:280 - loss: 0.118930 acc:95.3125
steps:300 - loss: 0.132682 acc:95.3125
Evaluation - loss: 0.002152 acc: 89.9000%(899/1000)
Saving best model, acc: 89.9000%
dev_eval( test_iterator, textcnn_model)
Evaluation - loss: 0.002377 acc: 87.6000%(876/1000)
tensor(87.6000)


























 1504
1504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









