







 本文介绍了NLP中的注意力机制如何通过矩阵运算实现权重池化,以及在视觉领域的应用,如VIT中图片注意力的处理过程。重点讲解了Q、K、V的维度转换和softmax操作的作用。同时提到了不同类型的图片注意力域和VIT模型的工作原理。
本文介绍了NLP中的注意力机制如何通过矩阵运算实现权重池化,以及在视觉领域的应用,如VIT中图片注意力的处理过程。重点讲解了Q、K、V的维度转换和softmax操作的作用。同时提到了不同类型的图片注意力域和VIT模型的工作原理。
1. NLP里的attention怎么理解
可以先借助这个可视化的图来理解。
最开始输入的特征维度为 [C, T]。
训练三组weight(Q,K,V), 维度分别为[A, C], 可以将特征压缩成三组vecotor 维度为[A,T]
Q和K(转置)相乘得到attention matrix, 维度为[A,A]
除以根号d之后(点积的数量级增长很大,会将 softmax 函数推向了梯度极小的区域[1])
经过softmax之后再,乘以V,最终输出的维度还是[C, T]。
Attention本质上是pooling:一种有权重的avg-pooling
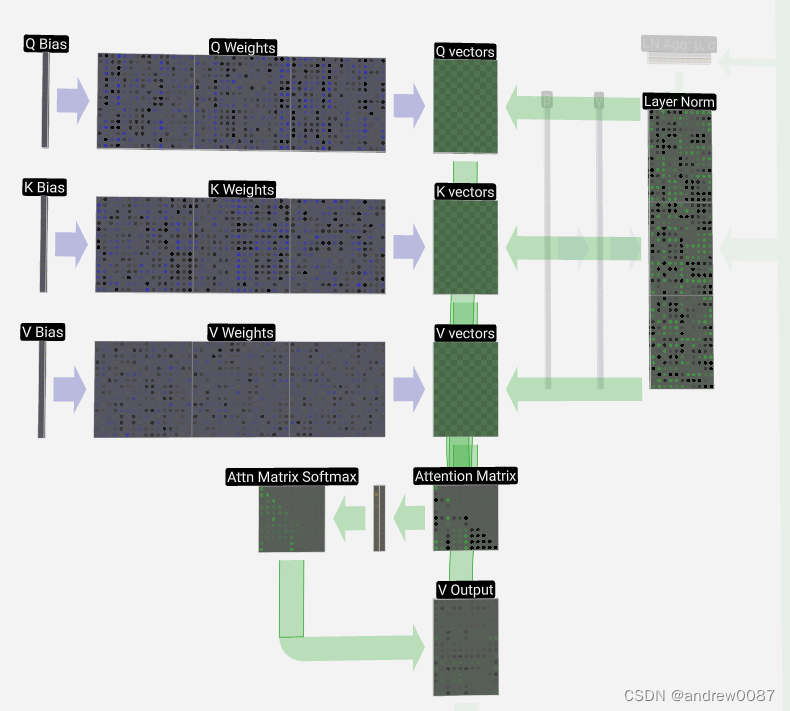
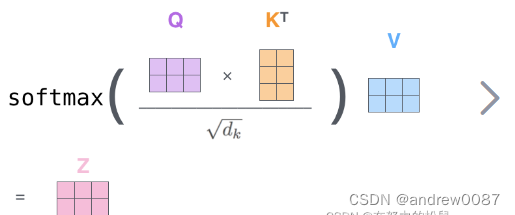
2. 图片的attention
跟文本类似,图片的attention也会保持输入和输出的维度一致。就注意力关注的域来分[2]:
- 空间域(spatial domain)
- 通道域(channel domain)
- 层域(layer domain)
- 混合域(mixed domain)
- 时间域(time domain)
首先要理解图片patch怎么变成attention里的token的,比较经典的工作当属VIT,
假设原始图片为[224,224,3], 每个patch大小假设为[16,16,3],则最终得到196个Patch。每个patch可以通过一个linear projection映射成一个一维向量(假设维度为768)。那就可以得到[196,768]维的输入。
VIT里使用了conv2D(kernel size 16*16,stride 16*16)来实现特征提取, 输入是[224,224,3],输出是[14,14,768]。然后将H,W维度压缩到一起,从而变成[196,768]维。
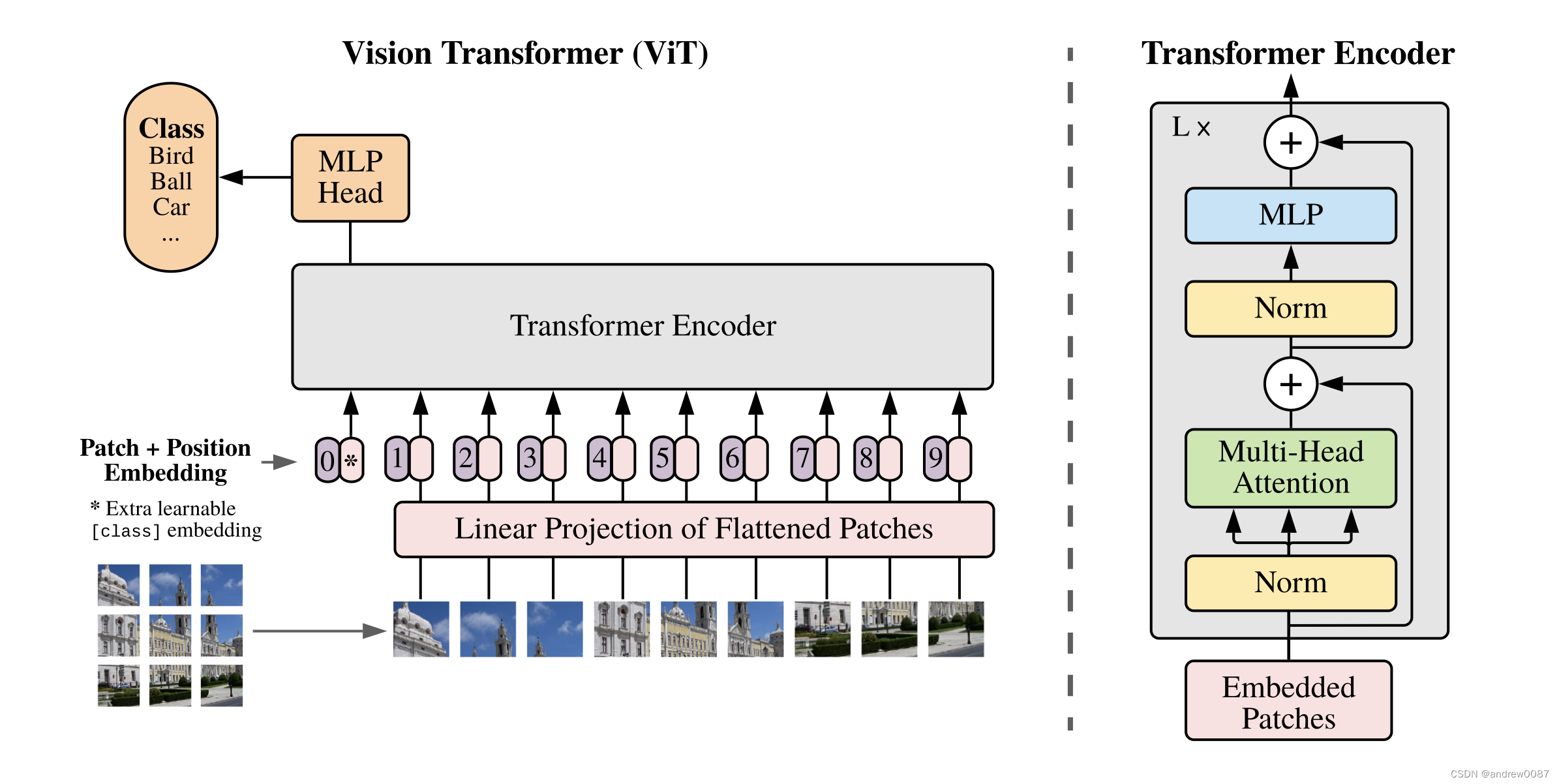
参考文章
[1] 为什么 dot-product attention 需要被 scaled?_scaled dot-product-CSDN博客
[2] 综述---图像处理中的注意力机制_注意力和原图对应的关系-CSDN博客















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









