







学习资料
https://www.youtube.com/watch?v=ifCDXFdeaaM
十分钟读懂Diffusion:图解Diffusion扩散模型_PaperWeekly的博客-CSDN博客
模拟问答
1. 什么是扩散模型
有一个forward Process, 给一个图像不断加噪声,直到看不出图像。
有一个reverse Process,给一个噪声图,去做Denoise,直到出现图像。
- VAE 和Diffusion Model的区别是什么。
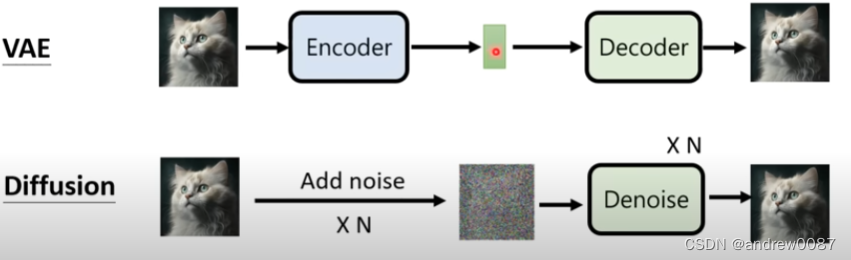
VAE是通过Encoder和Decoder两个网络来实现Forward Process和reverse Process,将图像映射成一个latent representation。
Diffusion通过加噪声实现VAE里的Encoder、通过Denoise实现Decoder。
- Diffusion Model的训练 过程怎么理解?
产生的distribution和目标的distribution越接近越好。
事先定好一批权重alpha(越来越小),先采样一个干净的图像X0,在随机一个整数t,随机一个噪声epsilon。epsilon_theta是一个noise predictor。去预测混入的噪声epsilon长什么样。
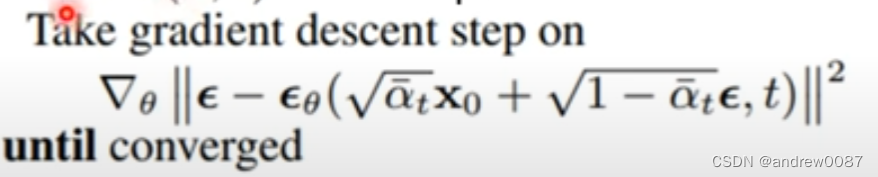
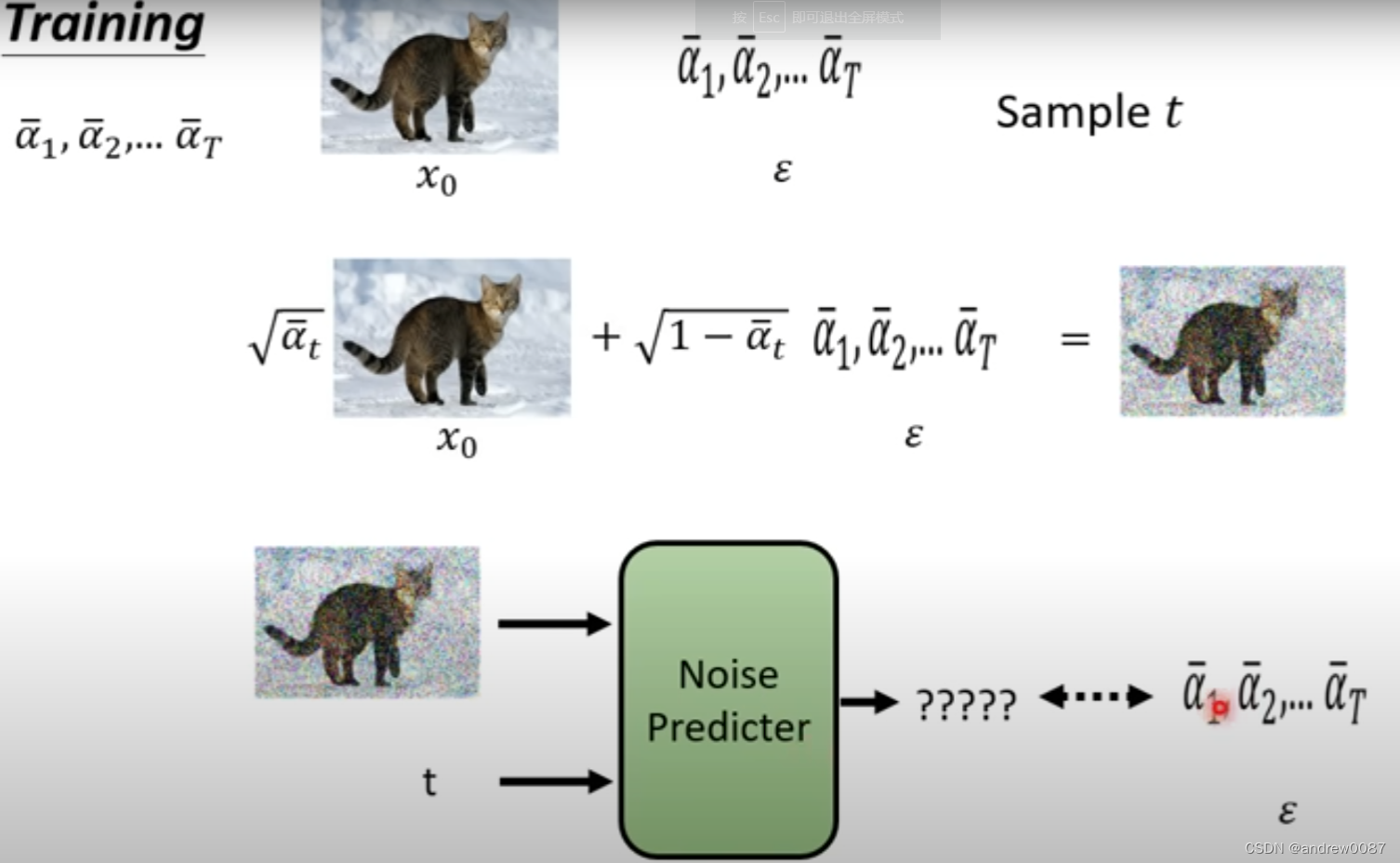
- 训练过程为什么可以这样简化
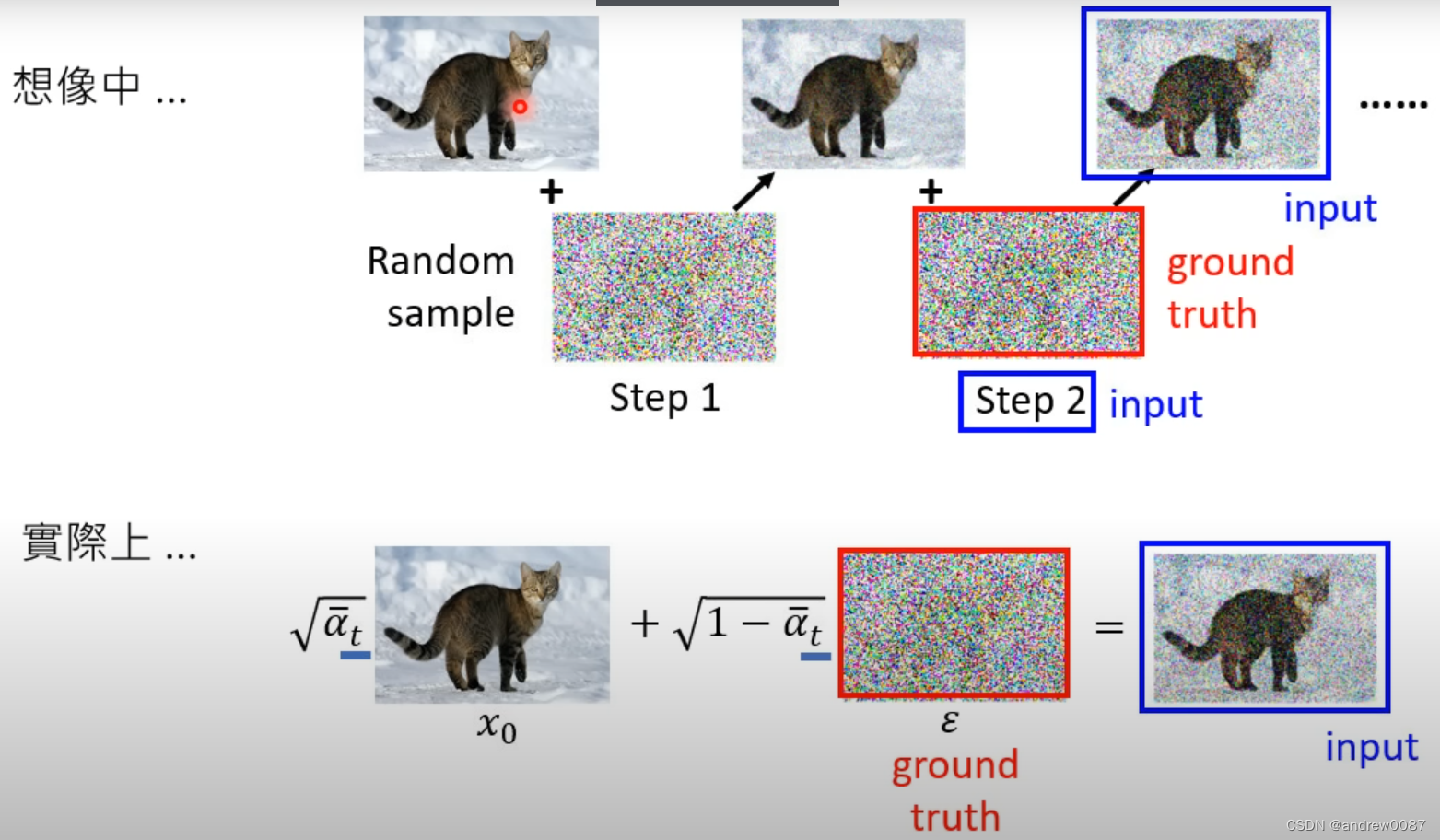
按照常规理解,是Add noise的时候是多次加噪声,Denoise的时候也是逐个预测上一步加的噪声。
实际上是,是给定一个权重alpha_t, 通过加权一次性的就得到有噪音的图。训练的时候把alpha_t也当做一个输入。
- Diffusion Model的产生图的过程怎么理解?
先随机一个全部都是噪声的图x_T, 跑T次循环,每一次循环先生成一个噪声z出来。
epsilon_theta(X_t, t)是之前训练好的noise predicotor预测出来的noise,乘上一个权重。
带噪声的图减去上述加权的值,按照常理来说就是我们要的图。但是这里有加上了一个随机出来的噪声乘以sigma_t, 这是为什么呢?
2. 图像生成模型
本质上是在在一个已知的简单distribution(通常是一个高斯分布)里面采样一个z出来,丢到一个网络中去,输出一个图。这些图片可以组成一个非常复杂的distribution。我们期待的是找到一个network,使得输出图像的distribution跟真正图像的distribution越接近越好。
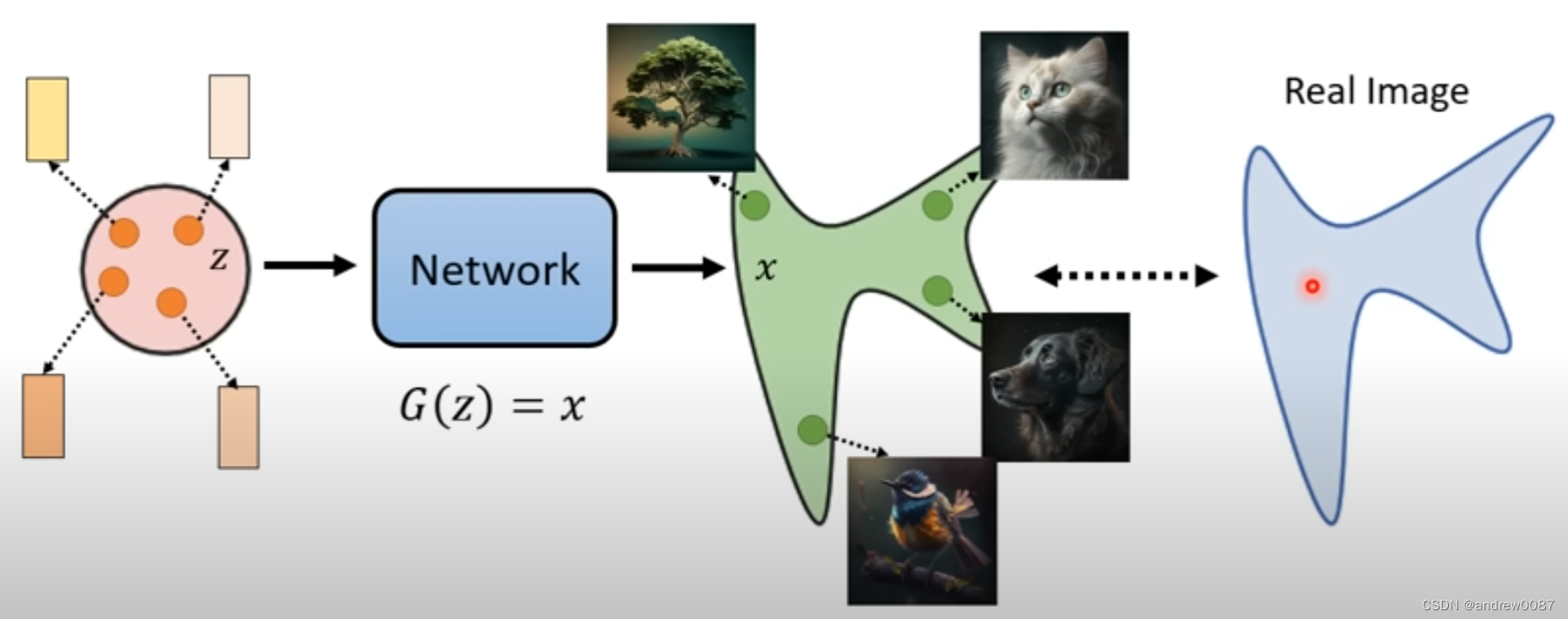
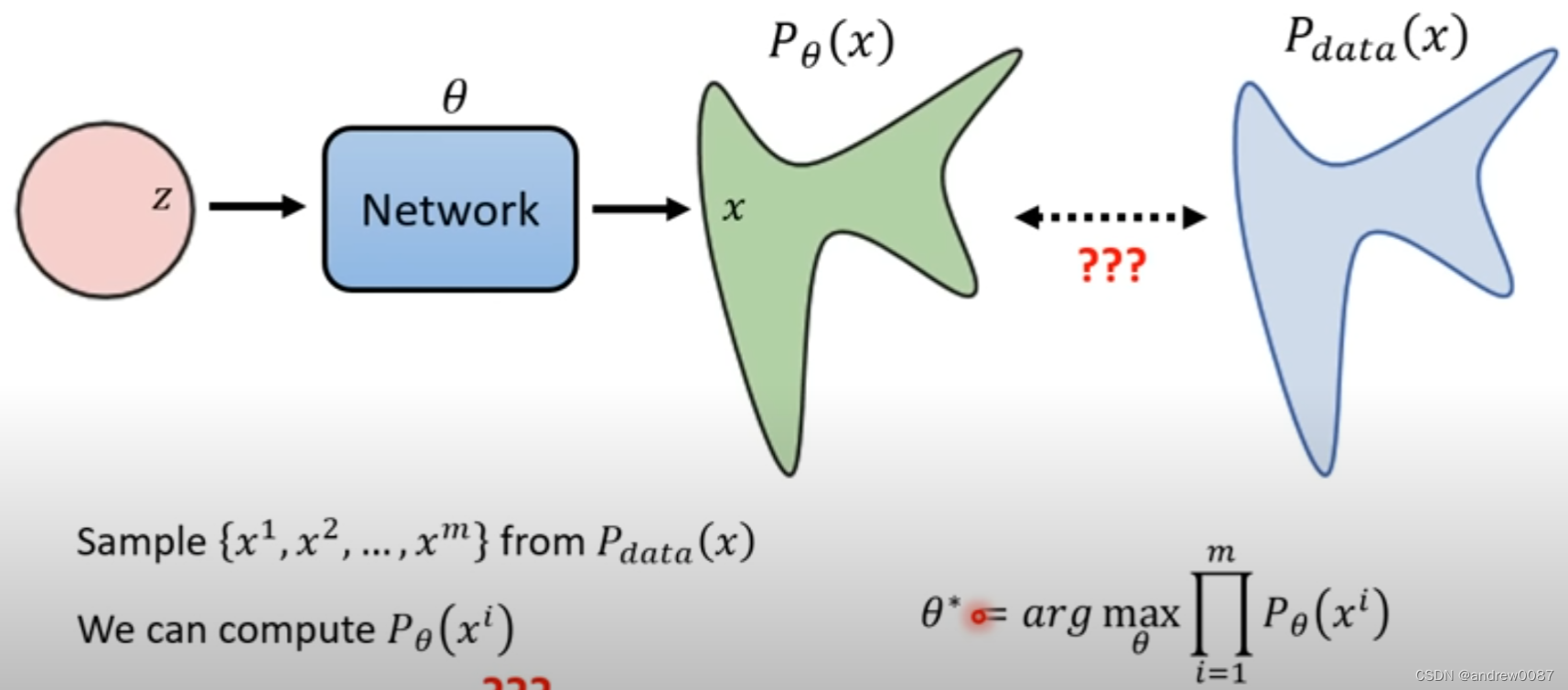
- 什么叫distribution越接近越好?
theta来表示网络,P_theta(x)代表生成的图像,P_data(x)代表真实的图像。
收集训练图像的过程,就可以理解为在全世界所有的图P_data(x)中采样的过程。
假设我们可以计算P_theta产生某一张图的几率(实际上做不到),我们要找的网络theta是让采样到的图{x^1,....x^m}生成的几率最大化。
- 文本输入怎样理解?
文本输入可以理解为Network的一个condition。
- Maxmim likehood == miniminze KL divergence
- 什么是KL Divergence.
- 什么是VAE模什么是VAE模型
Diffusion 的缺点是在反向扩散过程中需要把完整尺寸的图片输入到 U-Net,这使得当图片尺寸以及 time step t 足够大时,Diffusion 会非常的慢。Stable Diffusion 就是为了解决这一问题而提出的。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









