







在本文中,我们将探讨论文"One-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing",以及其对应的PyTorch实现代码。这篇文章官方没有开源,开源仓是非官方的复现。该文章中的图像的3D特征表示和解耦动作和表情特征的思想,被用在了后续的一些talking face的文章中,比如Sadtalker, 以及至今没有开源的MEGA Portrait, VASA-1。
论文概述
论文提出了一种新颖的神经网络模型,用于合成逼真的“会说话的头像”视频。该模型能够基于单张源图像和一段驱动视频来合成动态的头部视频,其中源图像包含了目标人物的外观,而驱动视频则决定了输出视频中的动作。该技术的一个显著特点是能够在不使用3D图形模型的情况下,实现从不同视角重新渲染头部视频,从而模拟出更加自然的面对面视频会议体验。
技术亮点
- 单次拍摄自由视角合成:使用单张源图像和一系列未受监督学习的3D关键点来重新创建讲话者视频。
- 高效的视频表示:提出了一种新颖的3D关键点表示方法。
方法论
1. 源图像特征提取
使用3D外观特征提取网络从源图像中提取3D外观特征体积。
对应代码的71-79,将【3,256,256】的图像,转换为【32,16,64,64】的4D tensor 表示。
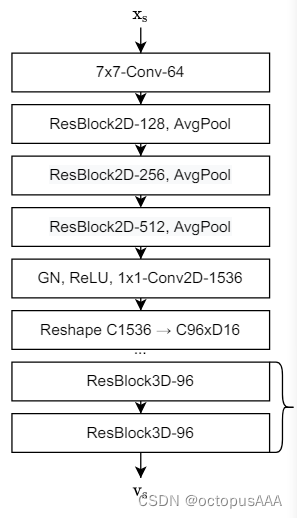
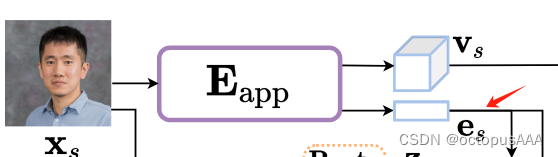
MegaPortrait里的Eapp也是实现了类似的功能。
2.源图像/ 驱动视频特征提取
对源图像提取canonical的隐空间关键点表示。注,该关键点跟传统意义上的人脸关键点不一样。

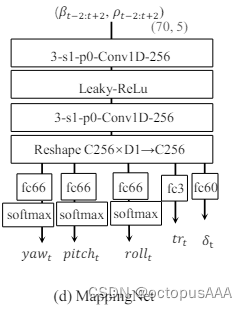
对原图像和驱动视频的每一帧图像进行头部姿态估计和表情变形估计,也映射到同一个维度的隐空间去。
在论文里这个隐空间的维度是【3,20】,在复现的代码里这个维度是【3,15】One-Shot_Free-View_Neural_Talking_Head_Synthesis/config/vox-256-beta.yaml at main · zhanglonghao1992/One-Shot_Free-View_Neural_Talking_Head_Synthesis · GitHub
在megaPortrait里是用global descriptor es来表示,看起来像是一个一维度向量。
使用源图像中提取的规范3D关键点来计算驱动关键点,从而建立任意一张图和正脸图的映射关系。
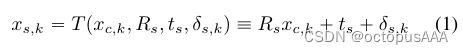
![]()
R是一个【3,3】的矩阵,代表旋转。,
t_d是【1,3】维的矩阵,可以repeate成[3,K]
delate是一个[3,K]维的矩阵,代表口型表情。
3. warping
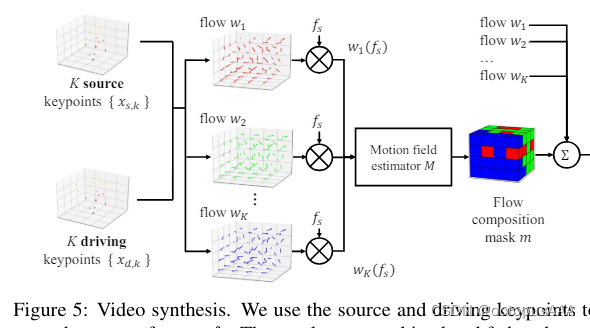
在Face vid2vid里对应着Figure5的左半边。
4. 隐空间变换
这里的输入有两个,源图像的4D Tensor,维度为【32,16,64,64】‘;上一步得到的warping,维度为【16,64,64,3】。输出为【32,16,64,64】。
这一部分的对应 Figure5的中间部分。
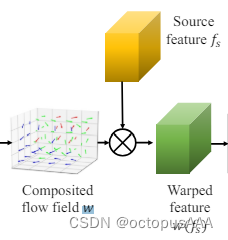
代码实现对应这里
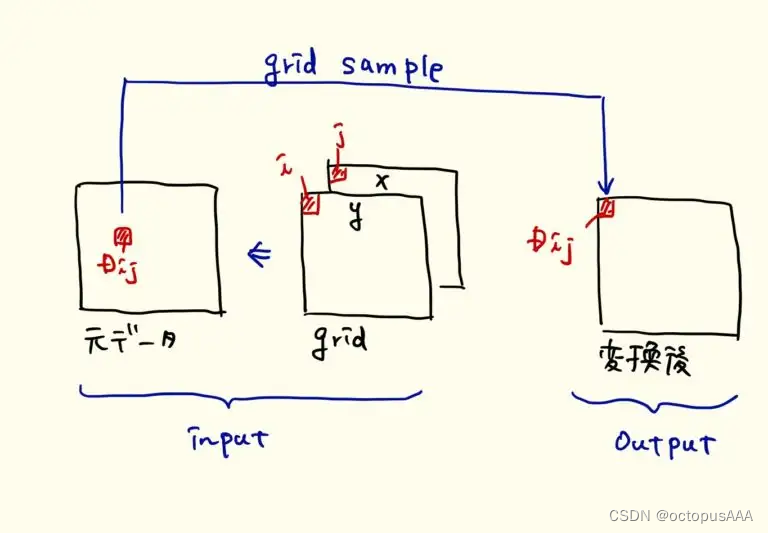
F.grid_sample 是 PyTorch 中的一个函数,它根据给定的网格(在本例中即为变形矩阵)对输入特征图进行采样。在图像形变中,这个网格定义了如何从输入图像中重新映射(或“采样”)像素以创建形变后的输出。
下图示意图里2D grid_sample是什么意思。 face vid2vid里用的是3D grid_sample。
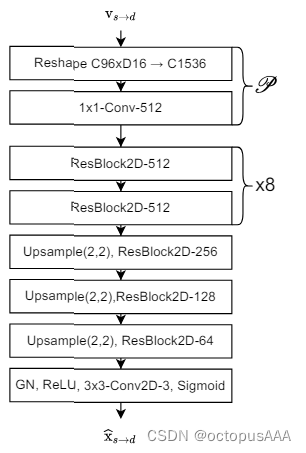
5. 图像Decoder
这里可以理解为第一部分的一个反向操作,把【32,16,64,64】的4D tensor映射回图像空间【3,256,256】。对应代码的109行到113行。
在MegaPortrait里类似的功能模块被叫做G2D。

















 1210
1210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









