








温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
1. 项目背景
面对激烈的市场竞争,各个航空公司相继推出了更优惠的营销方式来吸引更多的客户,国内某航空公司面临着常旅游客流失、竞争力下降和航空公司资源未充分利用等经营危机。本项目对某航空公司今年来积累的大量的会员档案信息和其乘坐航班记录,利用RFM模型对客户进行分类,对不同的客户类别进行特征分析,比较不同类客户的客户价值,同时机器学习算法对可能的流失客户就行预测,为航空公司制定相应的营销策略提供支撑。
基于机器学习的航空公司客户价值分析与流失预测
2. 功能组成
基于机器学习的航空公司客户价值分析与流失预测功能主要包括:
3. 数据读取与预处理
df = pd.read_csv('./data/国内某航空公司会员数据.csv')
df = df[df['WORK_COUNTRY'] == 'CN']
del df['Unnamed: 0']
print(df.shape)对于整个数据集,我们做了以下的清洗行为:
- 丢弃票价为空的记录
- 保留票价不为0,或平均折扣率不为0且总飞行公里数大于0的记录
- 把入会时间2014年2月29日的异常记录改为2014年2月28日
df = df[df['EXPENSE_SUM_YR_1'].notnull()*df['EXPENSE_SUM_YR_2'].notnull()] #票价非空值才保留
#只保留票价非零的,或者平均折扣率与总飞行公里数同时为0的记录。
index1 = df['EXPENSE_SUM_YR_1'] != 0
index2 = df['EXPENSE_SUM_YR_2'] != 0
index3 = (df['SEG_KM_SUM'] == 0) & (df['avg_discount'] == 0) #该规则是“与”
df = df[index1 | index2 | index3] #该规则是“或”| MEMBER_NO | FFP_DATE | FIRST_FLIGHT_DATE | GENDER | FFP_TIER | WORK_CITY | WORK_PROVINCE | WORK_COUNTRY | age | LOAD_TIME | ... | Eli_Add_Point_Sum | L1Y_ELi_Add_Points | Points_Sum | L1Y_Points_Sum | Ration_L1Y_Flight_Count | Ration_P1Y_Flight_Count | Ration_P1Y_BPS | Ration_L1Y_BPS | Point_Chg_NotFlight | runoff_flag | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ‘00000004 | 2000-08-10 00:00:00 | 2000-10-17 00:00:00 | 男 | 4 | 广州 | 广东 | CN | 45.0 | 2008-04-01 00:00:00 | ... | 2734 | 2578 | 10826 | 4566 | 0.333333 | 0.666667 | 0.754232 | 0.245644 | 13 | 0 |
| 1 | ‘00000010 | 1999-09-29 00:00:00 | 1999-09-29 00:00:00 | 女 | 5 | NaN | 北京 | CN | 45.0 | 2008-04-01 00:00:00 | ... | 2285 | 2285 | 47420 | 30754 | 0.555556 | 0.444444 | 0.369240 | 0.630738 | 5 | 0 |
| 2 | ‘00000011 | 2003-01-23 00:00:00 | 2003-03-07 00:00:00 | 男 | 4 | 大连 | 辽宁 | CN | 41.0 | 2008-04-01 00:00:00 | ... | 0 | 0 | 7225 | 2452 | 0.250000 | 0.750000 | 0.660531 | 0.339330 | 0 | 0 |
| 3 | ‘00000012 | 2003-01-30 00:00:00 | 2005-10-16 00:00:00 | 男 | 4 | 哈尔滨 | 黑龙江 | CN | 47.0 | 2008-04-01 00:00:00 | ... | 0 | 0 | 13452 | 10791 | 0.692308 | 0.307692 | 0.197800 | 0.802126 | 0 | 0 |
| 4 | ‘00000013 | 2003-01-30 00:00:00 | 2003-08-25 00:00:00 | 女 | 4 | 上海 | 上海 | CN | 42.0 | 2008-04-01 00:00:00 | ... | 0 | 0 | 4551 | 4074 | 0.700000 | 0.300000 | 0.104789 | 0.894991 | 0 | 0 |
4. 数据探索性可视化分析
4.1 客户基本信息分析
入会时间和第一次飞行时间
plt.figure(figsize=(16, 6))
sns.countplot(df['FFP_DATE'].dt.year)
plt.title('Distribution histogram of annual membership', fontsize=16, weight='bold')
plt.show()
plt.figure(figsize=(16, 6))
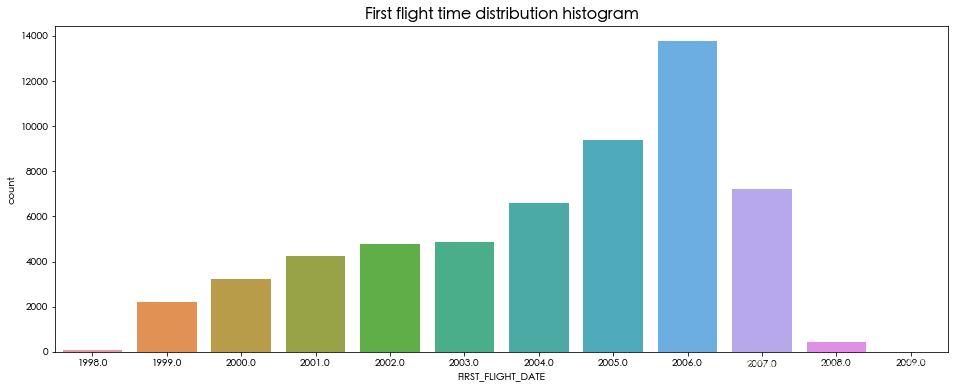
sns.countplot(df['FIRST_FLIGHT_DATE'].dt.year)
plt.title('First flight time distribution histogram', fontsize=16, weight='bold')
plt.show()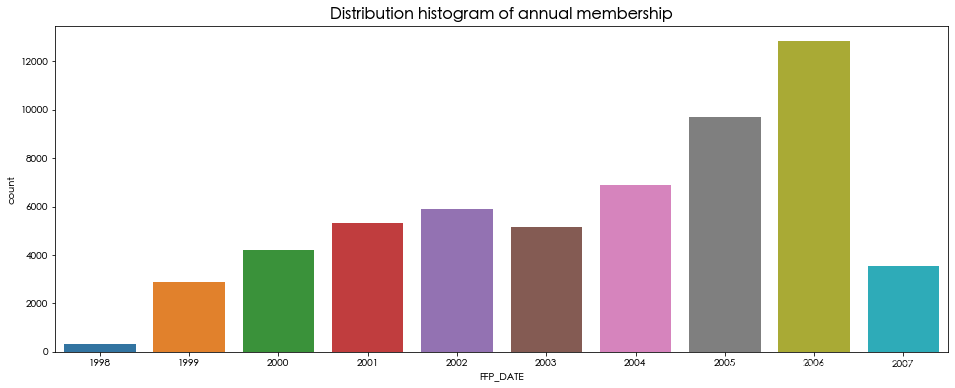
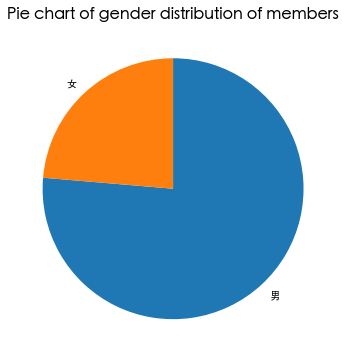
性别分布
会员级别分布
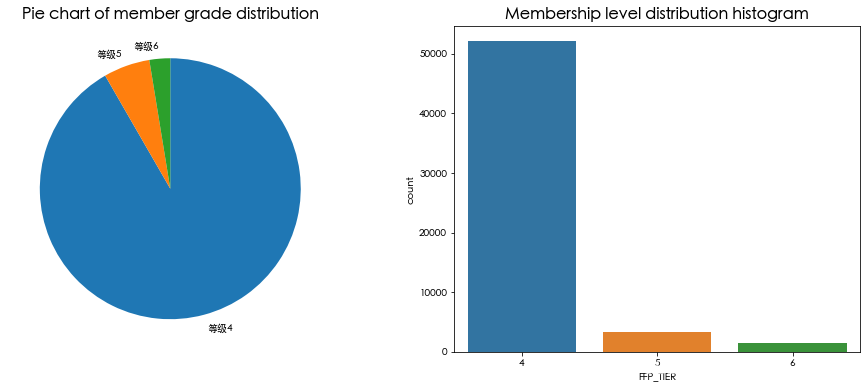
年龄分布
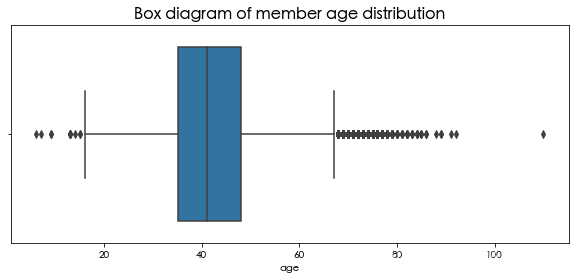
可以看出,会员的人数在2006年的增幅最大,男性占到了76%,会员的级别集中在4级,年龄集中在30-50岁之间。
2.2 乘坐航班记录信息分析
乘机信息是和客户价值关联最密切的信息,其中客户最近一次乘坐公司飞机距观测窗口结束的时长(观测窗口j结束时间2014年4月1日,单位为天),飞行次数,总飞行里程数分别可以对应一个用户的R,F,M的信息。
积分信息
对于积分相关的信息,我们主要看的是积分的兑换次数和总累积积分。

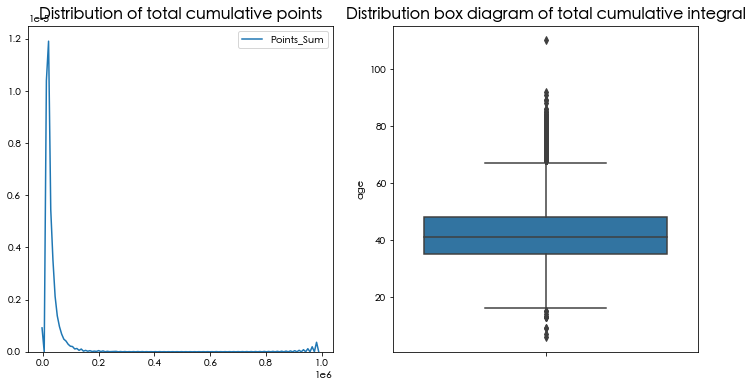
绝大多数的积分主要集中在0-10次以内,表明公司对于积分的玩法似乎并不是很重视,绝大部分的会员都没有兑换积分的意识。而总累积积分的分布和飞行次数和飞行里程的分布比较接近,一定程度上可以用另外2个属性来代替。
2.3 客户信息的相关性分析
plt.figure(figsize=(12, 10))
sns.heatmap(tmp.corr(),vmin=0,vmax=1, annot=True, fmt='.1f')
plt.title('Correlation analysis of customer information', fontsize=20)
plt.show()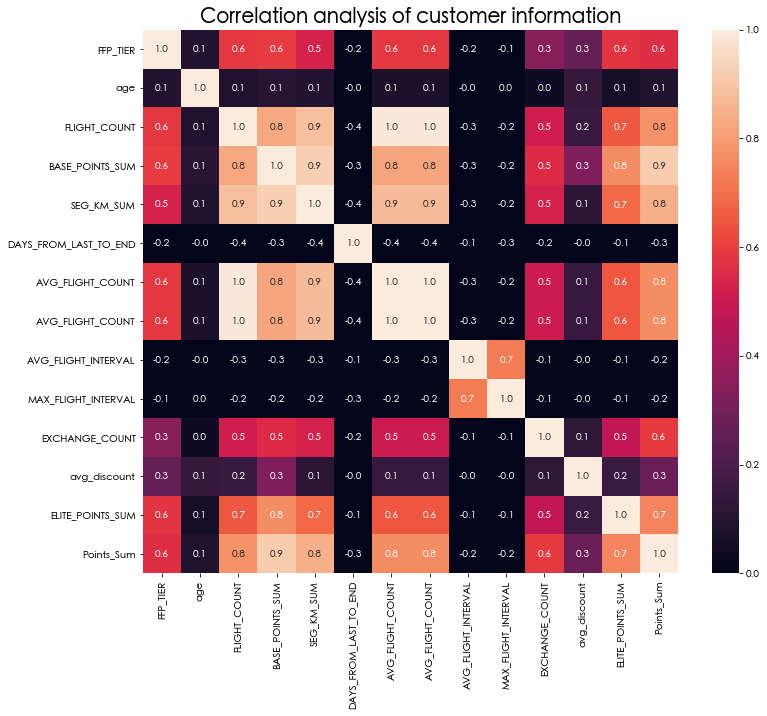
可以看出,我们选择最近一次乘坐公司飞机距观测窗口结束的时长,飞行次数,总飞行里程数,积分的兑换次数,总累积积分,入会年份和客户年龄进行不同特征间的相关性分析,其中主要用的是皮尔逊相关系数。
3. RFM 模型建模分析
识别客户价值应用最广泛的模型是通过3个指标:
- 最近消费时间间隔Recency
- 消费频率Frequency
- 消费金额Monetary
来进行客户细分,识别高价值的客户,简称RFM模型。
在RFM模型中,消费金额表示在一段时间内,客户购买该企业产品金额的总和。由于航空价受到运输距离、航位等级等多种因素影响,同样消费金额的不同旅客对航空公司的价值是不同的。所以消费金额这个指标并不适用于航空公司的客户价值分析。我们选择客户在一定时间内累积的飞行里程M和客户在一定时间内乘坐舱位所对应的折扣系数的平均值C,两个指标代替消费金额。
本案例将客户关系长度L、消费时间间隔R、消费频率F、飞行里程M、折扣系数的平均值C五个指标作为航空公司识别客户价值,记为LRFMC模型。
- L:会员入会时间距观测窗口结束的月数;
- R:客户最近一次乘坐公司飞机距观测窗口结束的月数
- F:客户在观测窗口内乘坐公司飞机的次数
- M:客户在观测窗口内累计的飞行里程
- C:客户在观测窗口内乘坐舱位所对应的折扣系数的平均值
原始数据中属性太多,根据航空公司客户价值LRFMC模型,选择与LRFMC指标相关的6个属性:FFP_DATE、LOAD_TIME、FLIGHT_COUNT、avg_discount、SEG_KM_SUM、LAST_TO_END。
1)L=LOAD_TIME-FFP_DATE(需要手动构造)
会员入会时间距观测窗口结束的月数=观测窗口的结束时间-入会时间【单位:天】
2)R=LAST_TO_END
客户最近一次乘坐公司飞机距观测窗口结束的月数=最后一次乘机时间至观察窗口末端时长【单位:天】
3)F=FLIGHT_COUNT 客户在观测窗口内乘坐公司飞机的次数=观测窗口的总飞行次数【单位:月】
4)M=SEG_KM_SUM 客户在观测时间内在公司累计的飞行里程=观测窗口的总飞行公里数【单位:公里】
5)C=AVG_DISCOUNT
客户在观测时间内乘坐舱位多对应的折扣系数的平均值=平均折扣率【单位:无】
特征构建
L = pd.to_datetime(df["LOAD_TIME"]) - pd.to_datetime(df["LAST_FLIGHT_DATE"])
data_features = pd.concat([L.dt.days,df[['DAYS_FROM_LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM','avg_discount']]],axis = 1)
data_features.columns = ["L","R","F","M","C"]
data_features = (data_features - data_features.mean(axis = 0))/(data_features.std(axis = 0)) #简洁的语句实现了标准化变换,类似地可以实现任何想要的变换。
data_features.columns=['Z'+i for i in data_features.columns] #表头重命名。客户信息聚类
from sklearn.cluster import KMeans
k = 5
kmodel = KMeans(n_clusters = k, n_jobs = 4,random_state=123,init="k-means++") #n_jobs是并行数,一般等于CPU数较好
kmodel.fit(data_features) #训练模型
cluster_center = pd.DataFrame(kmodel.cluster_centers_,columns=data_features.columns) #查看聚类中心
cluster_center.index = pd.Series(kmodel.labels_ ).drop_duplicates().values
cluster_count = pd.Series(kmodel.labels_ ).value_counts()
cluster_count.name = "count"
cluster_center = pd.concat([cluster_center,cluster_count],axis=1)
cluster_center.index = ["客户群"+str(i + 1) for i in cluster_center.index]
cluster_center.sort_index(inplace=True)
cluster_center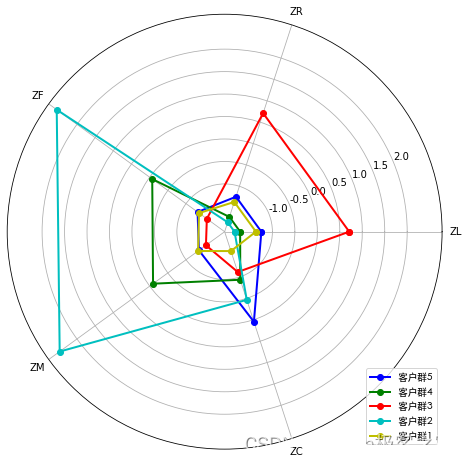
plt.subplots(figsize = (10,8))
sns.heatmap(cluster_center,cmap="Blues",annot=True,vmax=1,square=True)
plt.show()
针对聚类结果进行特征分析,其中
- 客户群1,数量最少,所乘航班折扣率较高(一般所乘航班的等级较高),属于重要发展客户。
- 客户群2,数量较多,乘坐次数很少,累计总飞行公里数较少,很久没有乘坐飞机,属于低价值客户。
- 客户群3,累计总飞行公里数较大,飞行次数较多,最近乘坐过飞机,属于重要保持客户。
- 客户群4,数量较多,所乘航班折扣率较低,加入会员时间短,这类客户一般在打折时才会乘坐航班,属于一般客户.
- 客户群5,数量较多,加入会员时间长,但是最近乘坐频率变小,属于重要挽留客户。
其中重要发展客户、重要保持客户、重要挽留客户分别对应客户生命周期管理的发展期、稳定期、衰退期。
| 客户群 | 排名 | 排名含义 |
|---|---|---|
| 客户群3 | 1 | 重要保持客户 |
| 客户群1 | 2 | 重要发展客户 |
| 客户群5 | 3 | 重要挽留客户 |
| 客户群4 | 4 | 一般客户 |
| 客户群2 | 5 | 低价值客户 |
聚类参数调优
distortions =[]
for i in range(1,11):
km = KMeans(n_clusters=i,n_init=10,max_iter=300,random_state=0)
km.fit(data_features)
distortions.append(km.inertia_)
plt.figure(figsize=(10, 5))
plt.plot(range(1,11),distortions,marker = "o")
plt.xlabel("Number of clusters")
plt.ylabel("Distortion")
plt.show()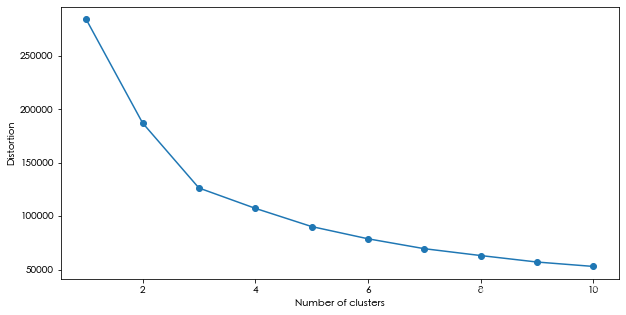
4. 基于决策树的航空客户流失预测建模
数据集预处理和训练集划分
# 去除无用的字段
df.drop(['MEMBER_NO', 'FFP_DATE', 'FIRST_FLIGHT_DATE', 'GENDER', 'WORK_CITY', 'WORK_PROVINCE', 'WORK_COUNTRY',
'LOAD_TIME', 'LAST_FLIGHT_DATE', 'TRANSACTION_DATE'], inplace=True, axis=1)
X_train, X_valid, y_train, y_valid = train_test_split(df, y_train_all, test_size=0.1, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, test_size=0.1, random_state=42)
print('train: {}, valid: {}, test: {}'.format(X_train.shape[0], X_valid.shape[0], X_test.shape[0]))
xgboost客户流失模型训练
df_columns = X_train.columns.values
print('===> feature count: {}'.format(len(df_columns)))
xgb_params = {
'eta': 0.1,
'min_child_weight': 8,
'colsample_bytree': 0.5,
'max_depth': 4,
'subsample': 0.9,
'lambda': 2.0,
'eval_metric': 'auc',
'objective': 'binary:logistic',
'nthread': -1,
'silent': 1,
'booster': 'gbtree'
}
dtrain = xgb.DMatrix(X_train, y_train, feature_names=df_columns)
dvalid = xgb.DMatrix(X_valid, y_valid, feature_names=df_columns)
watchlist = [(dtrain, 'train'), (dvalid, 'valid')]
model = xgb.train(dict(xgb_params),
dtrain,
evals=watchlist,
verbose_eval=100,
early_stopping_rounds=100,
num_boost_round=4000)[0] train-auc:0.933052 valid-auc:0.928962
Multiple eval metrics have been passed: 'valid-auc' will be used for early stopping.Will train until valid-auc hasn't improved in 100 rounds.
[100] train-auc:0.999909 valid-auc:0.999776
[200] train-auc:0.999992 valid-auc:0.999906
[300] train-auc:0.999999 valid-auc:0.999928
[400] train-auc:1 valid-auc:0.999936
[500] train-auc:1 valid-auc:0.999935
Stopping. Best iteration:
[432] train-auc:1 valid-auc:0.999937
客户流失预测模型评估
# predict train
predict_train = model.predict(dtrain)
train_auc = evaluate_score(predict_train, y_train)
# predict validate
predict_valid = model.predict(dvalid)
valid_auc = evaluate_score(predict_valid, y_valid)
print('train auc = {:.7f} , valid auc = {:.7f}\n'.format(train_auc, valid_auc))
# predict test
dtest = xgb.DMatrix(X_test, feature_names=df_columns)
predict_test = model.predict(dtest)
test_auc = evaluate_score(predict_test, y_test)
print('测试集预测 AUC :', test_auc)
train auc = 1.0000000 , valid auc = 0.9999326
测试集预测 AUC : 0.9999223269358186
特征重要程度情况
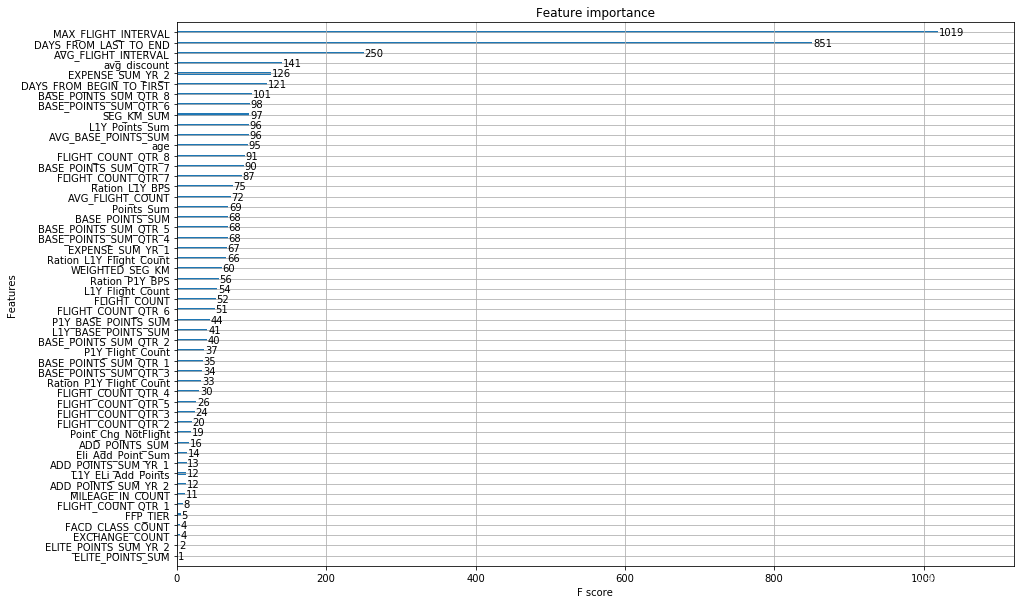 ROC 曲线
ROC 曲线
fpr, tpr, _ = roc_curve(y_valid, predict_valid)
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(10,10))
plt.plot(fpr, tpr, color='darkorange',
lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([-0.02, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC curve')
plt.legend(loc="lower right")
plt.show()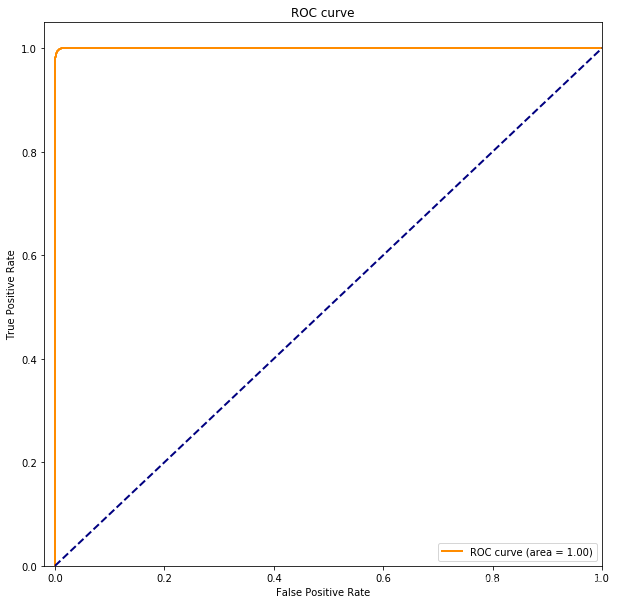
混淆矩阵计算
from sklearn.metrics import confusion_matrix
import itertools
confusion_matrix_test = confusion_matrix(
y_test, predict_test > 0.5, labels=None, sample_weight=None)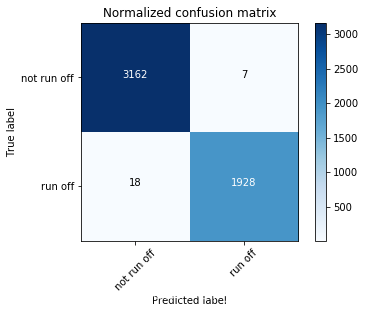
5. 结论
面对激烈的市场竞争,各个航空公司相继推出了更优惠的营销方式来吸引更多的客户,国内某航空公司面临着常旅游客流失、竞争力下降和航空公司资源未充分利用等经营危机。本项目对某航空公司今年来积累的大量的会员档案信息和其乘坐航班记录,利用RFM模型对客户进行分类,对不同的客户类别进行特征分析,比较不同类客户的客户价值,同时机器学习算法对可能的流失客户就行预测,为航空公司制定相应的营销策略提供支撑。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:




















 2588
2588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











