







温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
1. 项目简介
随着大数据分析技术的发展,智慧城市、智慧停车的领域正在发展,智慧停车场可以采集、记录以及存储停车场的运营数据,停车数量与时间的关系可显示停车场的运行状态。本项目基于停车场的运营数据,利用 python 实现对智能停车场运行数据的可视化统计分析,对停车时间、停车高峰期时间占比、停车星期比 、每日接待车辆统计、车辆归属地等多个维度进行可视化分析,利用flask构建web后台rest接口服务,echarts实现前端可视化。
基于数据挖掘的智能停车场运营数据分析系统
2. 功能组成
基于数据挖掘的智能停车场运营数据分析系统的主要功能包括:
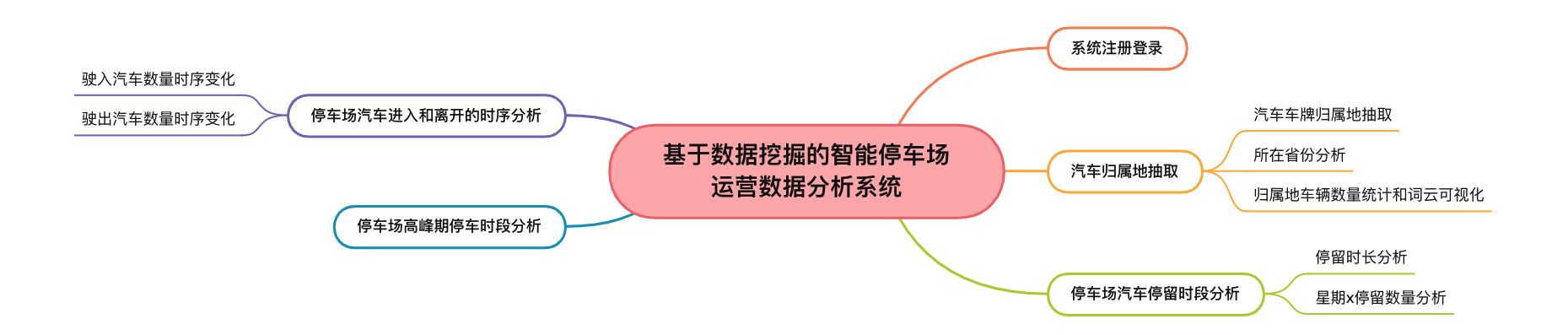
3. 基于数据挖掘的智能停车场运营数据分析系统
3.1 系统首页和注册登录

3.2 汽车归属地抽取并词云分析
针对汽车的车牌号,抽取出汽车的归属地,并进行词频的统计:
# 排除进入停车场未出停车场的车
data = data.loc[data['timeout'] != 0]
data['timein'] = pd.to_datetime(data['timein'])
data['timeout'] = pd.to_datetime(data['timeout'])
data['h'] = data['timeout'] - data['timein']
# 汽车归属地所在省份
data['province'] = data['cn'].map(lambda x: x[0])
print(data.head())
word_count = {}
for name in tqdm(data['cn'].values):
word = name[0:2]
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
wordclout_dict = sorted(word_count.items(), key=lambda d: d[1], reverse=True)
wordclout_dict = [{"name": k[0], "value": k[1]} for k in wordclout_dict if k[1] > 0]
# 归属地所在省份
province_count = {}
for pro in data['province']:
if pro not in province_count:
province_count[pro] = 0
province_count[pro] += 1
province_count = sorted(province_count.items(), key=lambda d: d[1], reverse=True)
province = [p[0] for p in province_count]
count = [p[1] for p in province_count]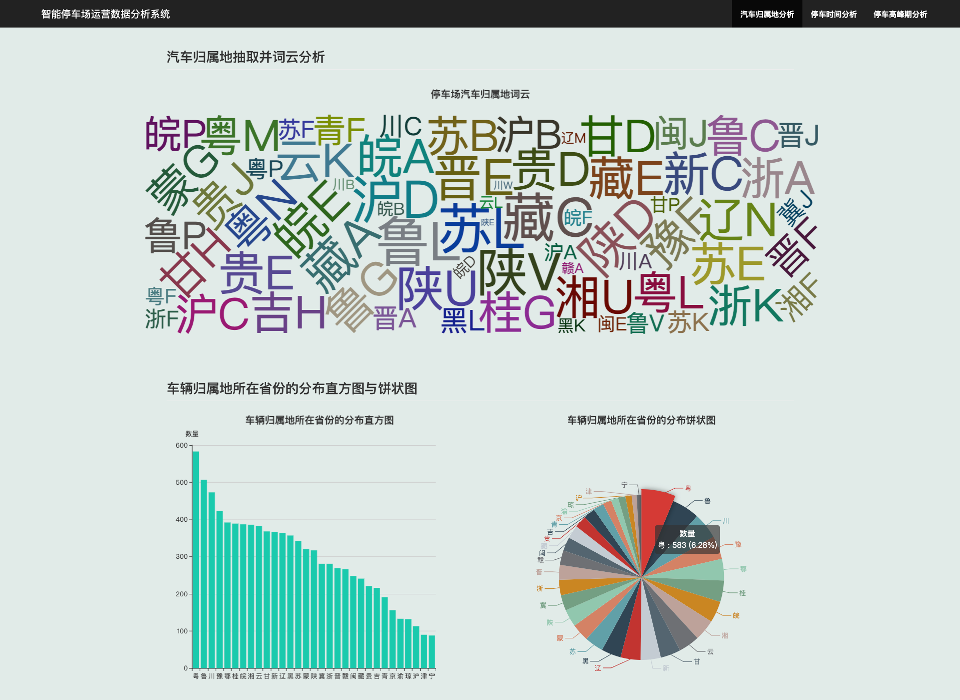
3.3 停车场汽车停留时段分布情况
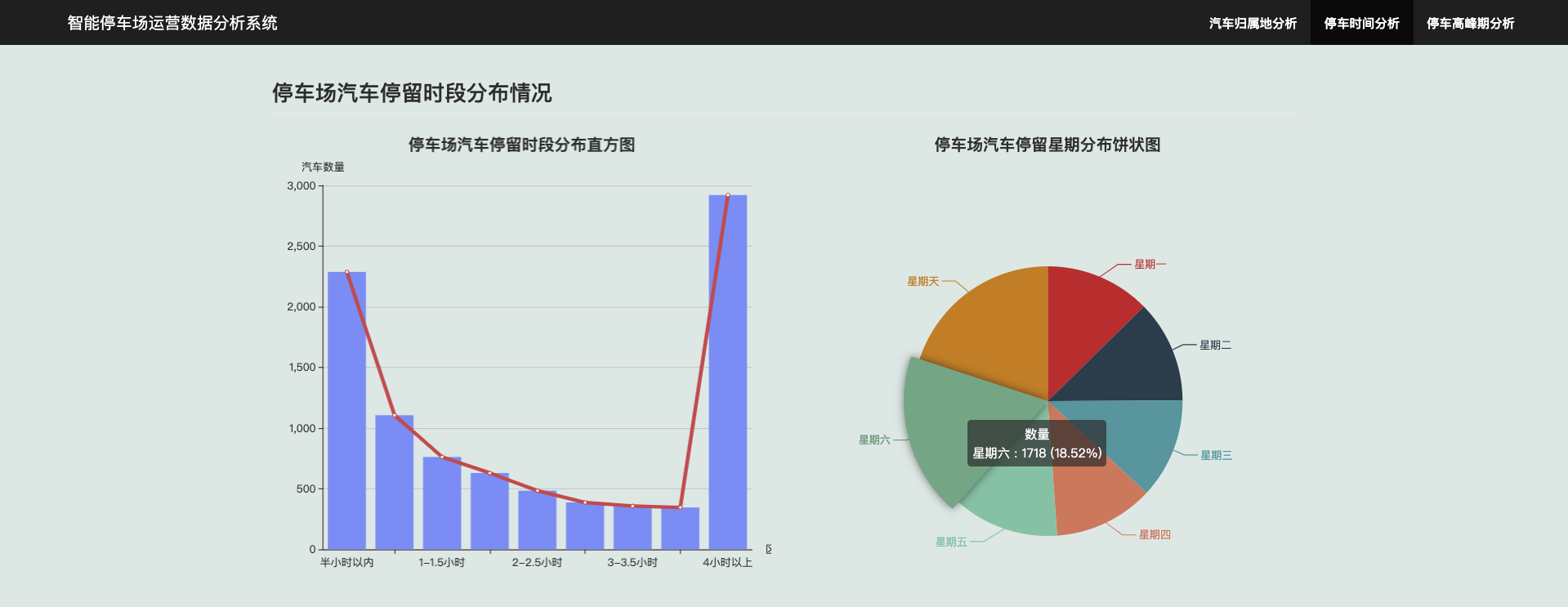
可以看出,大部分汽车停留的时间超过4个小时以上,可能为附近上班人员或居住人员,半个小时的汽车其次。星期六、星期日的停车数量也较多,可能为附近居住人员。
3.4 停车场汽车进入和离开的时序分布情况
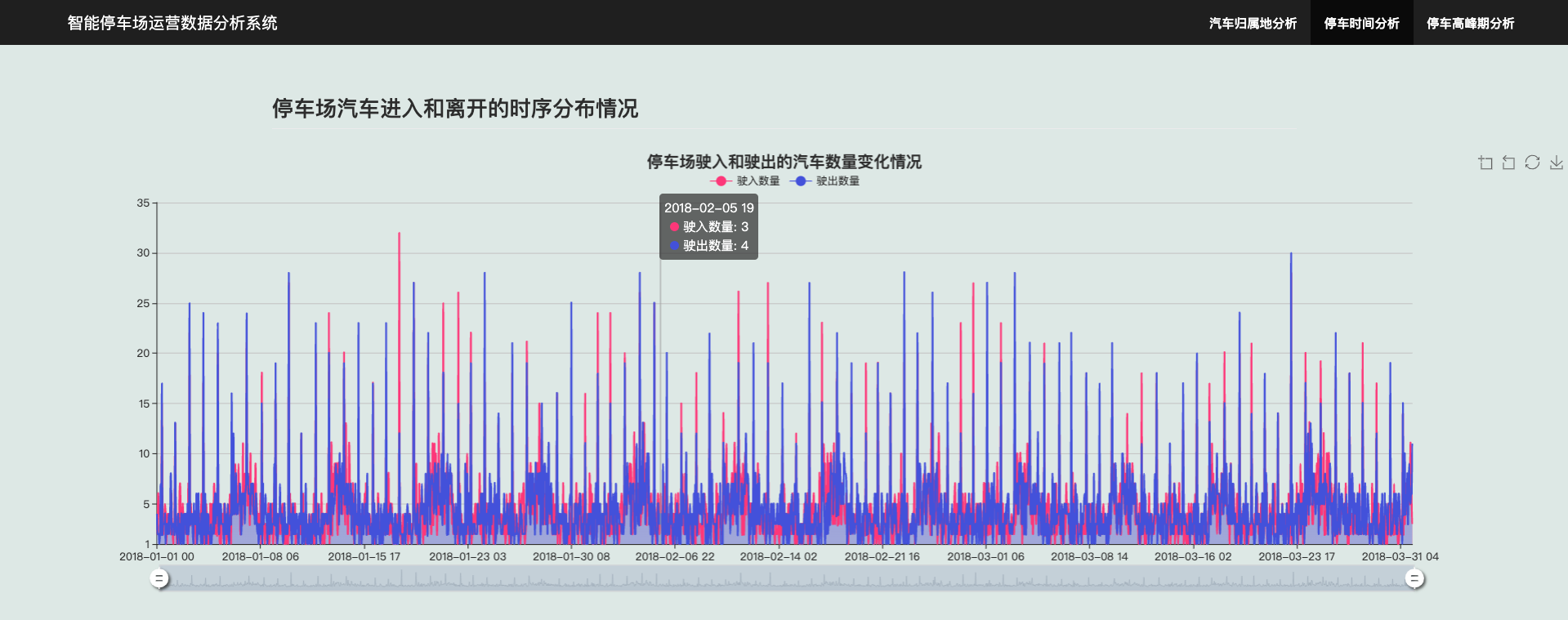
可对时序停车数据进行缩放查看细节: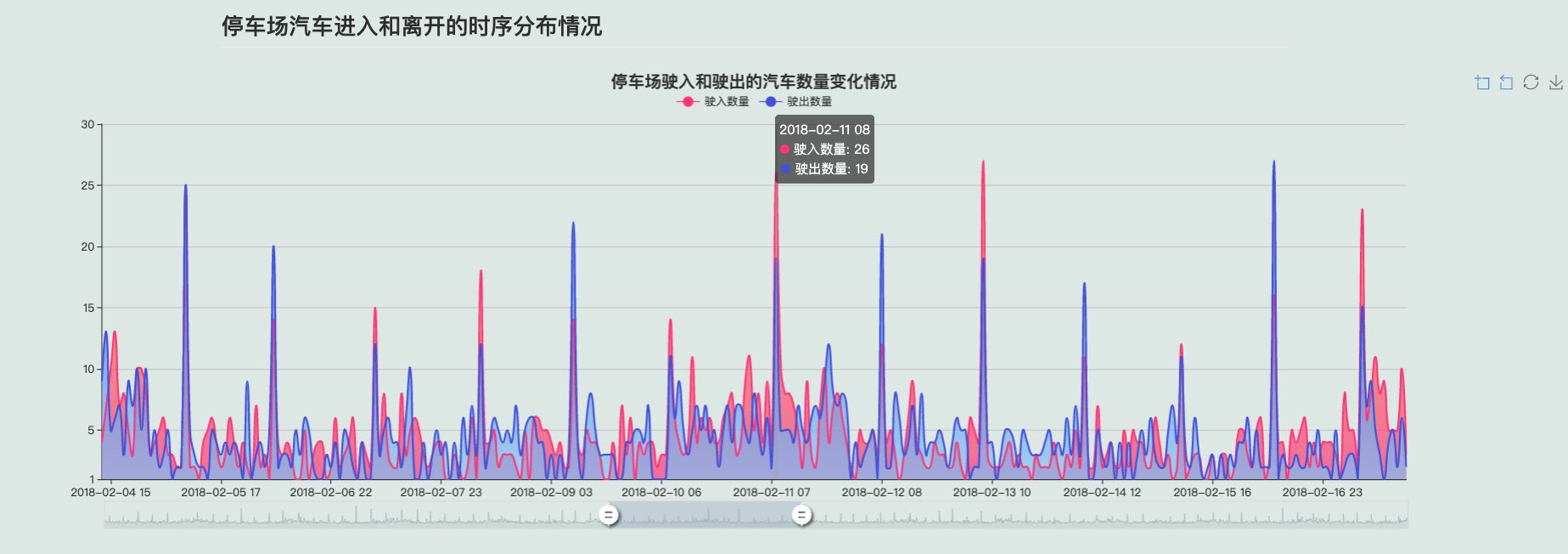
可以看出,停车场汽车的进出存在一定的时序周期性,且驶入和驶出能基本保持一定的平衡,说明停车场的在车辆管理方面较为合理。
3.5 停车场高峰期停车时段分析
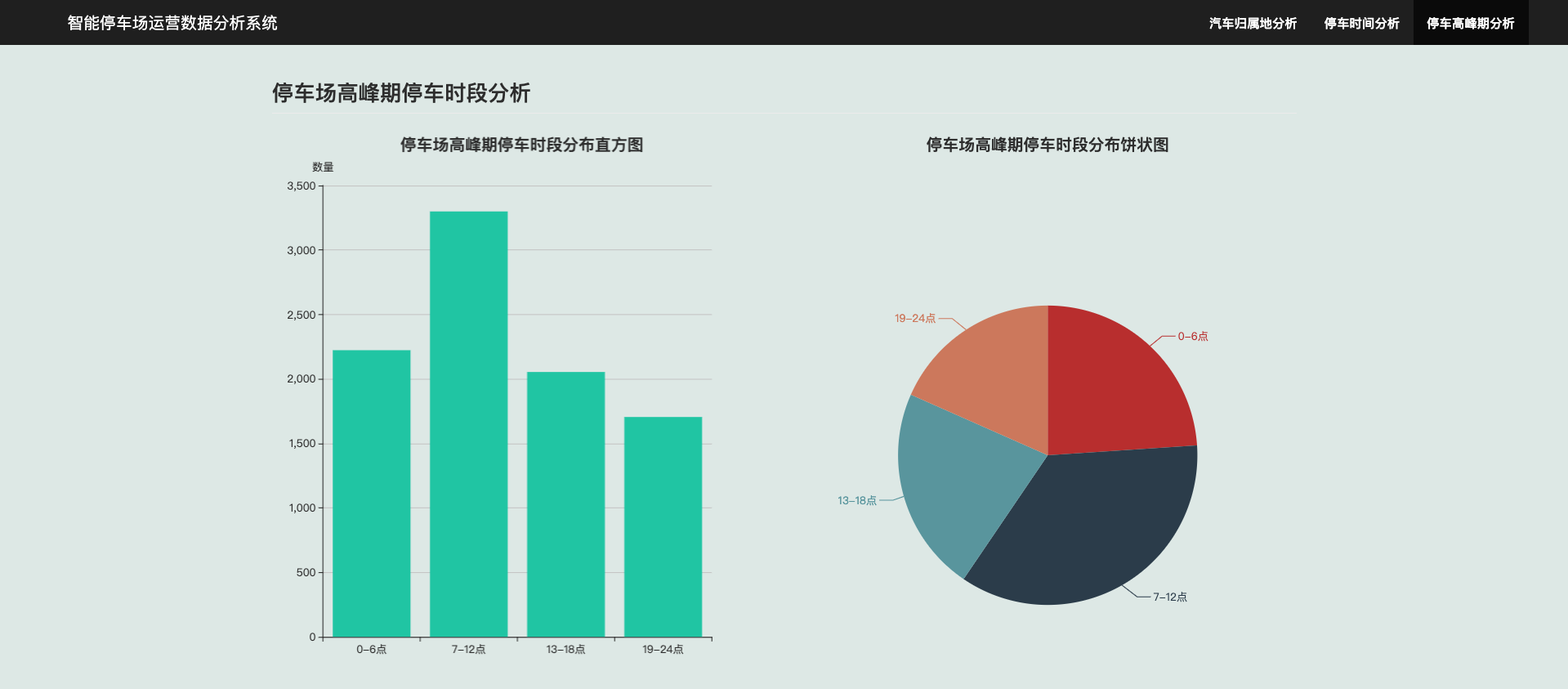
4. 总结
本项目基于停车场的运营数据,利用 python 实现对智能停车场运行数据的可视化统计分析,对停车时间、停车高峰期时间占比、停车星期比 、每日接待车辆统计、车辆归属地等多个维度进行可视化分析,利用flask构建web后台rest接口服务,echarts实现前端可视化。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
精彩专栏推荐订阅:




















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











