









1.Hive是什么?
- Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL ),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 QL ,它允许熟悉 SQL 的用户查询数据。
- Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。
- Hive的表其实就是HDFS的目录,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。
2.Hive的体系结构
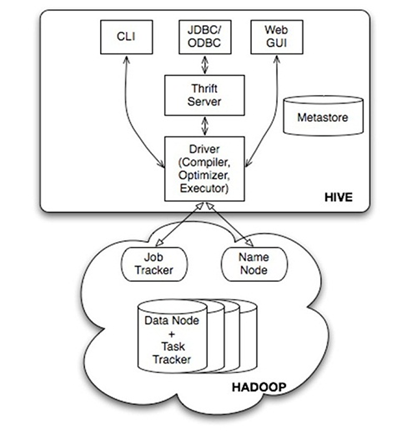
ps:
- 用户接口主要有三个:CLI,JDBC/ODBC和 WebUI
- CLI,即Shell命令行
- JDBC/ODBC 是 Hive 的Java,与使用传统数据库JDBC的方式类似
- WebGUI是通过浏览器访问 Hive
Hive 将元数据存储在数据库中(metastore),目前只支持 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行
- Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from table 不会生成 MapRedcue 任务)
3.Hive的安装
- 解压hive-0.9.0.tar.gz与重命名
cd /usr/local
tar -zxvf hive-0.9.0.tar.gz
mv hive-0.9.0 hive - 添加环境变量
修改/etc/profile文件:
[root@hadoop local]# vi /etc/profile增加
export HIVE_HOME=/usr/local/hive修改
export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HIVE_HOME/bin保存退出
[root@hadoop local]# source /etc/profile- 修改hive配置文件
[root@hadoop local]#cd $HIVE_HOME
[root@hadoop conf]#mv hive-env.sh.template hive-env.sh
[root@hadoop conf]#mv hive-default.xml.template hive-site.xml修改$HIVE_HOME/bin的hive-config.sh,增加以下三行
export JAVA_HOME=/usr/local/jdk
export HIVE_HOME=/usr/local/hive
export HADOOP_HOME=/usr/local/hadoop- 修改hadoop配置文件
修改hadoop的hadoop-env.sh(否则启动hive汇报找不到类的错误)
export HADOOP_CLASSPATH=.:$CLASSPATH:$HADOOP_CLASSPATH:
$HADOOP_HOME/bin4.启动HIVE
之前在环境变量中已经添加hive的环境信息,所以在命令行中直接输入hive就可以进入hive中
[root@hadoop bin]# hive














 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









