







 Chameleon算法是一种层次聚类方法,以变色龙得名,分为形成小簇集和合并聚类两个阶段。它弥补了传统聚类忽视簇间互连性和近似性的不足,通过相对互连性(RI)和相对近似性(RC)度量函数判断簇是否合并。算法首先构造k最近邻图,然后通过hMetric算法分割得到小簇,最后通过度量函数和阈值判断并合并聚类,适用于发现任意形状的高质量簇。然而,k的选取和时间复杂度是其挑战。
Chameleon算法是一种层次聚类方法,以变色龙得名,分为形成小簇集和合并聚类两个阶段。它弥补了传统聚类忽视簇间互连性和近似性的不足,通过相对互连性(RI)和相对近似性(RC)度量函数判断簇是否合并。算法首先构造k最近邻图,然后通过hMetric算法分割得到小簇,最后通过度量函数和阈值判断并合并聚类,适用于发现任意形状的高质量簇。然而,k的选取和时间复杂度是其挑战。
参考文献:http://www.cnblogs.com/zhangchaoyang/articles/2182752.html(用了很多的图和思想)
博客园(华夏35度) 作者:Orisun
数据挖掘算法-Chameleon算法.百度文库
我的算法库:https://github.com/linyiqun/lyq-algorithms-lib(里面可能有你正想要的算法)
算法介绍
本篇文章讲述的还是聚类算法,也是属于层次聚类算法领域的,不过与上篇文章讲述的分裂实现聚类的方式不同,这次所讲的Chameleon算法是合并形成最终的聚类,恰巧相反。Chamelon的英文单词的意思是变色龙,所以这个算法又称之为变色龙算法,变色龙算法的过程如标题所描绘的那样,是分为2个主要阶段的,不过他可不是像BIRCH算法那样,是树的形式。继续看下面的原理介绍。
算法原理
先来张图来大致了解整个算法的过程。

上面图的显示过程虽然说有3个阶段,但是这其中概况起来就是两个阶段,第一个是形成小簇集的过程就是从Data Set 到k最近邻图到分裂成小聚餐,第二个阶段是合并这些小聚簇形成最终的结果聚簇。理解了算法的大致过程,下面看看里面定义的一些概念,还不少的样子。
为了引出变色龙算法的一些定义,这里先说一下以往的一些聚类算法的不足之处。
1、忽略簇与簇之间的互连性。就会导致最终的结果形成如下:
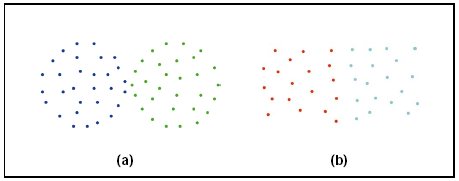
2、忽略簇与簇之间的近似性。就会导致最终的聚类结果变成这样“:
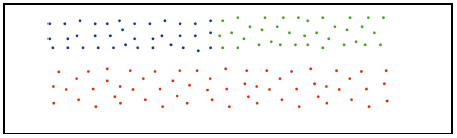
为什么提这些呢,因为Chameleon算法正好弥补了这2点要求,兼具互连性和近似性。在Chameleon算法中定义了相对互连性,RI表示和相对近似性,RC表示,最后通过一个度量函数:
function value = RI( Ci, Cj)× RC( Ci, Cj)α,α在这里表示的多少次方的意思,不是乘法。
来作为2个簇是否能够合并的标准,其实这些都是第二阶段做的事情了。
在第一阶段,所做的一件关键的事情就是形成小簇集,由零星的几个数据点连成小簇,官方的作法是用hMetic算法根据最小化截断的边的权重和来分割k-最近邻图,然后我网上找了一些资料,没有确切的hMetic算法,借鉴了网上其他人的一些办法,于是用了一个很简单的思路,就是给定一个点,把他离他最近的k个点连接起来,就算是最小簇了。事实证明,效果也不会太差,最近的点的换一个意思就是与其最大权重的边,采用距离的倒数最为权重的大小。因为后面的计算,用到的会是权重而不是距离。
我们再回过头来细说第二阶段所做的事情,首先是2个略复杂的公式(直接采用截图的方式):
相对互连性RI=
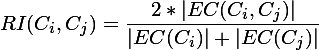
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2772
2772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









