







Python实践提升-函数
假如你把编程语言里的所有常见概念,比如循环、分支、异常、函数等,全部一股脑儿摆在我面前,问我最喜欢哪个,我会毫不犹豫地选择“函数”(function)。
我对函数的喜爱,最直接的原因来自于对重复代码的厌恶。通过函数,我可以把一段段逻辑封装成可复用的小单位,成片地消除项目里的重复代码。
试想你正在给系统开发一个新功能,在写代码时,你发现新功能的主要逻辑和一个旧功能非常类似,于是你认真读了一遍旧代码,并从中提炼出了好几个函数。通过复用这些函数,你只增加了寥寥几行代码,就完成了新功能开发——还有比这更让人有成就感的事情吗?
而消除重复代码,只是函数所提供给我们的众多好处之一。如果以它为起点,向四周继续发散,你会发现更多有趣的编程概念,包括高阶函数(higher-order function)、闭包(closure)、装饰器(decorator),等等。深入理解和掌握这些概念,是成为一名合格程序员的必经之路。
话题回到 Python 里的函数。我们知道,Python 是一门支持面向对象(object-oriented)的编程语言,但除此之外,Python 对函数的支持也毫不逊色。
从基础开始,我们最常用的函数定义方式是使用 def 语句:
# 定义函数
def add(x, y):
return x + y
# 调用函数
add(3, 4)
除了 def 以外,你还可以使用 lambda 关键字来定义一个匿名函数:
# 效果与 add 函数一样
add = lambda x, y: x + y
函数在 Python 中是一等对象,这意味着我们可以把函数自身作为函数参数来使用。最常用的内置排序函数 sorted() 就利用了这个特性:
>>> l = [13, 16, 21, 3]
# key 参数接收匿名函数作为参数
>>> sorted(l, key=lambda i: i % 3)
[21, 3, 13, 16]
创建一个函数很容易——只要写下一行 def,丢进去一些代码就行。但要写出一个好函数就没那么简单了。在编写函数时,有许多环节值得我们仔细推敲:
函数的名字是否易读好记?dump_fields 是个好名字吗?
函数的参数设计是否合理?接收 4 个参数会太多吗?
函数应该返回 None 吗?
类似的问题还有很多。
假如函数设计得当,其他人在阅读代码时,不光能更快地理解代码的意图,调用函数时也会觉得轻松惬意。而设计糟糕的函数,不光读起来晦涩难懂,想调用它时也常会碰一鼻子灰。
在本章中,我将分享一些在 Python 里编写函数的技巧,帮你避开一些常见陷阱,写出更清晰、更健壮的函数。
7.1 基础知识
7.1.1 函数参数的常用技巧
参数(parameter)是函数的重要组成部分,它是函数最主要的输入源,决定了调用方使用函数时的体验。
接下来,我将介绍与 Python 函数参数有关的几个常用技巧。
别将可变类型作为参数默认值
在编写函数时,我们经常需要为参数设置默认值。这些默认值可以是任何类型,比如字符串、数值、列表,等等。而当它是可变类型时,怪事儿就会发生。
以下面这个函数为例:
def append_value(value, items=[]):
"""向 items 列表中追加内容,并返回列表"""
items.append(value)
return items
这样的函数定义看上去没什么问题,但当你多次调用它以后,就会发现函数的行为和预想的不太一样:
>>> append_value('foo')
['foo']
>>> append_value('bar')
['foo', 'bar']
可以看到,在第二次调用时,函数并没有返回正确结果 [‘bar’],而是返回了 [‘foo’, ‘bar’],这意味着参数 items 的值不再是函数定义的空列表 [ ],而是变成了第一次执行后的结果 [‘foo’]。
之所以出现这个问题,是因为 Python 函数的参数默认值只会在函数定义阶段被创建一次,之后不论再调用多少次,函数内拿到的默认值都是同一个对象。
假如再多花点儿功夫,你甚至可以通过函数对象的保留属性 defaults 直接读取这个默认值:
>>> append_value.__defaults__[0] ➊
['foo', 'bar']
>>> append_value.__defaults__[0].append('baz') ➋
>>> append_value('value')
['foo', 'bar', 'baz', 'value']
❶ 通过 defaults 属性可以直接获取函数的参数默认值
❷ 假如修改这个参数默认值,可以直接影响函数调用结果
因此,熟悉 Python 的程序员通常不会将可变类型作为参数默认值。这是因为一旦函数在执行时修改了这个默认值,就会对之后的所有函数调用产生影响。
为了规避这个问题,使用 None 来替代可变类型默认值是比较常见的做法:
def append_value(value, items=None):
if items is None:
items = []
items.append(value)
return item
这样修改后,假如调用方没有提供 items 参数,函数每次都会构建一个新列表,不会再出现之前的问题。
定义特殊对象来区分是否提供了默认参数
当我们为函数参数设置了默认值,不强制要求调用方提供这些参数以后,会引入另一件麻烦事儿:无法严格区分调用方是不是真的提供了这个默认参数。
以下面这个函数为例:
def dump_value(value, extra=None):
if extra is None:
# 无法区分是否提供 None 是不是主动传入
...
# 两种调用方式
dump_value(value)
dump_value(value, extra=None)
对于 dump_value() 函数来说,当调用方使用上面两种方式来调用它时,它其实无法分辨。因为在这两种情况下,函数内拿到的 extra 参数的值都是 None。
要解决这个问题,最常见的做法是定义一个特殊对象(标记变量)作为参数默认值:
# 定义标记变量
# object 通常不会单独使用,但是拿来做这种标记变量刚刚好
_not_set = object()
def dump_value(value, extra=_not_set):
if extra is _not_set:
# 调用方没有传递 extra 参数
...
相比 None,_not_set 是一个独一无二、无法随意获取的标记值。假如函数在执行时判断 extra 的值等于 _not_set,那我们基本可以认定:调用方没有提供 extra 参数。
定义仅限关键字参数
在经典编程图书《代码整洁之道》1 中,作者 Robert C. Martin 提到:“函数接收的参数不要太多,最好不要超过 3 个。”这个建议很有道理,因为参数越多,函数的调用方式就会变得越复杂,代码也会变得更难懂。
下面这段代码就是个反例:
# 参数太多,根本不知道函数在做什么
func_with_many_args(user, post, True, 30, 100, 'field')
但建议归建议,在真实的 Python 项目中,接收超过 3 个参数的函数比比皆是。
为什么会这样呢?大概是因为 Python 里的函数不光支持通过有序位置参数(positional argument)调用,还能指定参数名,通过关键字参数(keyword argument)的方式调用。
比如下面这个用户查询函数:
def query_users(limit, offset, min_followers_count, include_profile):
"""查询用户
:param min_followers_count: 最小关注者数量
:param include_profile: 结果包含用户详细档案
"""
...
假如完全使用位置参数来调用它,会写出非常让人糊涂的代码:
# 时间长了,谁能知道 100 和 True 分别代表什么呢?
query_users(20, 0, 100, True)
但如果使用关键字参数,代码就会易读许多:
query_users(limit=20, offset=0, min_followers_count=100, include_profile=True)
# 关键字参数可以不严格按照函数定义参数的顺序来传递
query_users(min_followers_count=100, include_profile=True, limit=20, offset=0)
所以,当你要调用参数较多(超过 3 个)的函数时,使用关键字参数模式可以大大提高代码的可读性。
虽然关键字参数调用模式很有用,但有一个美中不足之处:它只是调用函数时的一种可选方式,无法成为强制要求。不过,我们可以用一种特殊的参数定义语法来弥补这个不足:
# 注意参数列表中的 * 符号
def query_users(limit, offset, *, min_followers_count, include_profile):
通过在参数列表中插入 * 符号,该符号后的所有参数都变成了“仅限关键字参数”(keyword-only argument)。如果调用方仍然想用位置参数来提供这些参数值,程序就会抛出错误:
>>> query_users(20, 0, 100, True)
# 执行后报错:
TypeError: query_users() takes 2 positional arguments but 4 were given
# 正确的调用方式
>>> query_users(20, 0, min_followers_count=100, include_profile=True)
当函数参数较多时,通过这种方式把部分参数变为“仅限关键字参数”,可以强制调用方提供参数名,提升代码可读性。
仅限位置参数
除了“仅限关键字参数”外,Python 还在 3.8 版本后提供另一个对称特性:“仅限位置参数”(positional-only argument)。
“仅限位置参数”的使用方式是在参数列表中插入 / 符号。比如 def query_users(limit, offset, /, min_followers_count, include_profile) 表示,limit 和 offset 参数都只能通过位置参数来提供。
不过在日常编程中,我发现需要使用“仅限位置参数”的场景,远没有“仅限关键字参数”的多,所以就不做过多介绍了。假如你感兴趣,可以阅读 PEP-570 了解详细说明。
1原版书名 Clean Code: A Handbook of Agile Software Craftsmanship,作者 Robert C. Martin,出版于 2007 年。
7.1.2 函数返回的常见模式
除了参数以外,函数还有另一个重要组成部分:返回值。下面是一些和返回值有关的常见模式。
尽量只返回一种类型
Python 是一门动态语言,它在类型方面非常灵活,因此我们能用它轻松完成一些在其他静态语言里很难做到的事情,比如让一个函数同时返回多种类型的结果:
def get_users(user_id=None):
if user_id is not None:
return User.get(user_id)
else:
return User.filter(is_active=True)
# 返回单个用户
user = get_users(user_id=1)
# 返回多个用户
users = get_users()
当使用方调用这个函数时,如果提供了 user_id 参数,函数就会返回单个用户对象,否则函数会返回所有活跃用户列表。同一个函数搞定了两种需求。
虽然这样的“多功能函数”看上去很实用,像瑞士军刀一样“多才多艺”,但在现实世界里,这样的函数只会更容易让调用方困惑——“明明 get_users() 函数名字里写的是 users,为什么有时候只返回了单个用户呢?”
好的函数设计一定是简单的,这种简单体现在各个方面。返回多种类型明显违反了简单原则。这种做法不光会给函数本身增加不必要的复杂度,还会提高用户理解和使用函数的成本。
像上面的例子,更好的做法是将它拆分为两个独立的函数。
(1) get_user_by_id(user_id):返回单个用户。
(2) get_active_users():返回多个用户列表。
这样就能让每个函数只返回一种类型,变得更简单易用。
谨慎返回 None 值
在编程语言的世界里,“空值”随处可见,它通常用来表示某个应该存在但是缺失的东西。“空值”在不同编程语言里有不同的名字,比如 Go 把它叫作 nil,Java 把它叫作 null,Python 则称它为 None。
在 Python 中,None 是独一无二的存在。因为它有着一种独特的“虚无”含义,所以经常会用作函数返回值。
当我们需要让函数返回 None 时,主要是下面 3 种情况。
操作类函数的默认返回值
当某个操作类函数不需要任何返回值时,通常会返回 None。与此同时,None 也是不带任何 return 语句的函数的默认返回值:
def close_ignore_errors(fp):
# 操作类函数,默认返回 None
try:
fp.close()
except IOError:
logger.warning('error closing file')
在这种场景下,返回 None 没有任何问题。标准库里有许多这类函数,比如 os.chdir()、列表的 append() 方法等。
意料之中的缺失值
还有一类函数,它们所做的事情天生就是在尝试,比如从数据库里查找一个用户、在目录中查找一个文件。视条件不同,函数执行后可能有结果,也可能没有结果。而重点在于,对于函数的调用方来说,“没有结果”是意料之中的事情。
针对这类函数,使用 None 作为“没有结果”时的返回值通常也是合理的。
在标准库中,正则表达式模块 re 下的 re.search()、re.match() 函数均属于此类。这两个函数在找到匹配结果时,会返回 re.Match 对象,否则返回 None。
在执行失败时代表“错误”
有时候,None 也会用作执行失败时的默认返回值。以下面这个函数为例:
def create_user_from_name(username):
"""通过用户名创建一个 User 实例"""
if validate_username(username):
return User.from_username(username)
else:
return None
user = create_user_from_name(username)
if user is not None:
user.do_something()
当 username 通过校验时,函数会返回正常的用户对象,否则返回 None。
这种做法看上去合情合理,甚至你会觉得,这和上一个场景“意料之中的缺失值”是同一回事儿。但它们之间其实有着微妙的区别。拿两个典型的具体函数来说,这种区别如下。
re.search():函数名 search,代表从目标字符串里搜索匹配结果,而搜索行为一向是可能有结果,也可能没有结果的。而且,当没有结果时,函数也不需要向调用方说明原因,所以它适合返回 None。
create_user_from_name():函数名的含义是“通过名字构建用户”,里面并没有一种可能没有结果的含义。而且如果创建失败,调用方大概率会想知道失败原因,而不仅仅是拿到一个 None。
从上面的分析来看,适合返回 None 的函数需要满足以下两个特点:
(1) 函数的名称和参数必须表达“结果可能缺失”的意思;
(2) 如果函数执行无法产生结果,调用方也不关心具体原因。
所以,除了“搜索”“查询”几个场景外,对绝大部分函数而言,返回 None 并不是一个好的做法。
对这些函数来说,用抛出异常来代替返回 None 会更为合理。这也很好理解:当函数被调用时,如果无法返回正常结果,就代表出现了意料以外的状况,而“意料之外”正是异常所掌管的领域。
使用异常改写函数后,代码会变成下面这样:
class UnableToCreateUser(Exception):
"""当无法创建用户时抛出"""
def create_user_from_name(username):
"""通过用户名创建一个 User 实例
:raises: 当无法创建用户时抛出 UnableToCreateUser
"""
if validate_username(username):
return User.from_username(username)
else:
raise UnableToCreateUser(f'unable to create user from {username}')
try:
user = create_user_from_name(username)
except UnableToCreateUser:
# 此处编写异常处理逻辑
else:
user.do_something()
与返回 None 相比,这种方式要求调用方使用 try 语句来捕获可能出现的异常。虽然代码比之前多了几行,但这样做有一个明显的优势:调用方可以从异常对象里获取错误原因——只返回一个 None 可做不到这点。
早返回,多返回
自打我开始写代码以来,常常会听人说起一条叫“单一出口”的原则。这条原则是说:“函数应该保证只有一个出口。”如果从字面上理解,符合这条原则的函数大概如下所示:
def user_get_tweets(user):
"""获取用户已发布状态
- 如果配置"展示随机状态",获取随机状态
- 如果配置"不展示任何状态",返回空的占位符状态
- 默认返回最新状态
"""
tweets = []
if user.profile.show_random_tweets:
tweets.extend(get_random_tweets(user))
elif user.profile.hide_tweets:
tweets.append(NULL_TWEET_PLACEHOLDER)
else:
# 最新状态需要用 token 从其他服务获取,并转换格式
token = user.get_token()
latest_tweets = get_latest_tweets(token)
tweets.extend([transorm_tweet(item) for item in latest_tweets])
return tweets
在这段代码里,user_get_tweets() 函数首先在头部初始化了结果变量 tweets,然后统一在尾部用一条 return 语句返回,符合“单一出口”原则。
如果以 4.3.1 节的“避免多层分支嵌套”的要求来看,上面的代码是完全符合标准的——函数内部只有一层分支,没有多层嵌套。
但这种风格的代码可读性不是很好,主要原因在于,读者在阅读函数的过程中,必须先把所有逻辑一个不落的装进脑子里,只有等到最后的 return 出现时,才能搞清楚所有事情。
拿具体场景举例,假如我在读 user_get_tweets() 函数时,只想弄明白“展示随机状态”这个分支会返回什么,那当我读完第二行代码后,仍然需要继续看完剩下的所有代码,才能确认函数最终会返回什么。
当函数逻辑较为复杂时,这种遵循“单一出口”风格编写的代码,为阅读代码增加了不少负担。
如果我们稍微调整一下写代码的思路:一旦函数在执行过程中满足返回结果的要求,就直接返回,代码会变成下面这样:
def user_get_tweets(user):
"""获取用户已发布状态"""
if user.profile.show_random_tweets:
return get_random_tweets(user)
if user.profile.hide_tweets:
return [NULL_TWEET_PLACEHOLDER]
# 最新状态需要用 token 从其他服务获取,并转换格式
token = user.get_token()
latest_tweets = get_latest_tweets(token)
return [transorm_tweet(item) for item in latest_tweets]
在这段代码里,函数的 return 数量从 1 个变成了 3 个。试着读读上面的代码,是不是会发现函数的逻辑变得更容易理解了?
产生这种变化的主要原因是,对于读代码的人来说,return 是一种有效的思维减负工具。当我们自上而下阅读代码时,假如遇到了 return,就会清楚知道:“这条执行路线已经结束了”。这部分逻辑在大脑里占用的空间会立刻得到释放,让我们可以专注于下一段逻辑。
因此,在编写函数时,请不要纠结函数是不是应该只有一个 return,只要尽早返回结果可以提升代码可读性,那就多多返回吧。
“单一出口”的由来
在写这部分内容时,我特意查询了“单一出口”原则的历史,以下是我的发现。
在几十年前,汇编与 FORTRAN 语言流行的年代,编程语言拥有令人头疼的灵活性,你可以用各种花样在代码内随意跳转,这导致程序员很容易写出各种难以调试的代码。
为了解决这个问题,著名计算机科学家 Dijkstra 提出了“单一入口,单一出口”(Single Entry, Single Exit)原则。在这个原则中,“单一出口”的意思是:函数(子程序)应该只从同一个地方跳出。
这样一来事情就很明朗了。在现代编程语言里,无论函数内部有多少个 return 语句,函数的出口都是统一的——通往上层调用栈,所以这完全不属于最初的“单一出口”原则所担心的范围。
即使后来“单一出口”原则发展出了别的含义,它也只针对一些特定的编程语言、编程场景有意义。比如在特定环境下,不恰当的返回会导致程序资源泄露等问题,所以要把返回统一起来管理。
但在 Python 中,“单一出口原则建议函数只写一个 return”只能算是一种误读,在“单一出口”和“多多返回”之间,我们完全可以选择可读性更强的那个。
7.1.3 常用函数模块:functools
在 Python 标准库中,有一些与函数关系紧密的模块,其中最有代表性的当属 functools。
functools 是一个专门用来处理函数的内置模块,其中有十几个和函数相关的有用工具,我会挑选比较常用的两个,简单介绍它们的功能。
functools.partial()
假如在你的项目中,有一个负责进行乘法运算的函数
multiply():
def multiply(x, y):
return x * y
同时,还有许多调用 multiplay() 函数进行运算的代码:
result = multiply(2, value)
val = multiply(2, number)
# ...
这些代码有一个共同的特点,那就是它们调用函数时的第一个参数都是 2——全都是对某个值进行 *2 操作。
为了简化函数调用,让代码更简洁,我们其实可以定义一个接收单个参数的 double() 函数,让它通过 multiply() 完成计算:
def double(value):
# 返回 multiply 函数调用结果
return multiply(2, value)
# 调用代码变得更简单
result = double(value)
val = double(number)
这是一个很常见的函数使用场景:首先有一个接收许多参数的函数 a,然后额外定义一个接收更少参数的函数 b,通过在 b 内部补充一些预设参数,最后返回调用 a 函数的结果。
针对这类场景,我们其实不需要像前面一样,用 def 去完全定义一个新函数——直接使用 functools 模块提供的高阶函数 partial() 就行。
partial 的调用方式为 partial(func, *arg, **kwargs),其中:
func 是完成具体功能的原函数;
*args/**kwargs 是可选位置与关键字参数,必须是原函数 func 所接收的合法参数。
举个例子,当你调用 partial(func, True, foo=1) 后,函数会返回一个新的可调用对象(callable object)——偏函数 partial_obj。
拿到这个偏函数后,如果你不带任何参数调用它,效果等同于使用构建 partial_obj 对象时的参数调用原函数:partial_obj() 等同于 func(True, foo=1)。
但假如你在调用 partial_obj 对象时提供了额外参数,前者就会首先将本次调用参数和构造 partial_obj 时的参数进行合并,然后将合并后的参数透传给原始函数 func 处理,也就是说,partial_obj(bar=2) 与 func(True, foo=1, bar=2) 效果相同。
使用 functools.partial,上面的 double() 函数定义可以变得更简洁:
import functools
double = functools.partial(multiply, 2)
functools.lru_cache()
在编码时,我们的函数常常需要做一些耗时较长的操作,比如调用第三方 API、进行复杂运算等。这些操作会导致函数执行速度慢,无法满足要求。为了提高效率,给这类慢函数加上缓存是比较常见的做法。
在缓存方面,functools 模块为我们提供一个开箱即用的工具:lru_cache()。使用它,你可以方便地给函数加上缓存功能,同时不用修改任何函数内部代码。
假设我有一个分数统计函数 caculate_score(),每次执行都要耗费一分钟以上:
def calculate_score(class_id):
print(f'Calculating score for class: {class_id}...')
# 模拟此处存在一些速度很慢的统计代码……
time.sleep(60)
return 42
因为 caculate_score() 函数执行耗时较长,而且每个 class_id 的统计结果都是稳定的,所以我可以直接使用 lru_cache() 为它加上缓存:
@lru_cache(maxsize=None)
def calculate_score(class_id):
print(f'Calculating score for class: {class_id}...')
time.sleep(60)
return 42
加上 lru_cache() 后的效果如下:
>>> calculate_score(100)
# 缓存未命中,耗时较长
Calculating score for class: 100...
42
# 第二次使用同样的参数调用函数,就不会触发函数内部的计算逻辑,
# 结果立刻就返回了。
>>> calculate_score(100)
42
在使用 lru_cache() 装饰器时,可以传入一个可选的 maxsize 参数,该参数代表当前函数最多可以保存多少个缓存结果。当缓存的结果数量超过 maxsize 以后,程序就会基于“最近最少使用”(least recently used,LRU)算法丢掉旧缓存,释放内存。默认情况下,maxsize 的值为 128。
如果你把 maxsize 设置为 None,函数就会保存每一个执行结果,不再剔除任何旧缓存。这时如果被缓存的内容太多,就会有占用过多内存的风险。
除了 partial() 与 lru_cache() 以外,functools 模块里还有许多有趣的函数工具,比如 wraps()、reduce() 等。如果有兴趣,可以到官方文档查阅更详细的资料,这里就不再一一赘述。
7.2 案例故事
在函数式编程(functional programming)领域,有一个术语纯函数(pure function)。它最大的特点是,假如输入参数相同,输出结果也一定相同,不受任何其他因素影响。换句话说,纯函数是一种无状态的函数。
比如下面的 mosaic() 函数就符合我们对纯函数的定义:
def mosaic(s):
"""把输入字符串替换为等长的星号字符"""
return '*' * len(s)
调用结果如下:
>>> mosaic('input')
'*****'
让函数保持无状态有不少好处。相比有状态函数,无状态函数的逻辑通常更容易理解。在进行并发编程时,无状态函数也有着无须处理状态相关问题的天然优势。
但即便如此,我们的日常工作还是免不了要和“状态”打交道,比如在下面这个故事里,小 R 遇到的问题就需要用“状态”来解决。
函数与状态
热身运动
小 R 正在自学 Python,一天,他从网上看到一道和字符串处理有关的练习题:
有一段文字,里面包含各类数字,比如数量、价格等,编写一段代码把文字里的所有数字都用星号替代,实现脱敏的效果。
原始文本:商店共 100 个苹果,小明以 12 元每斤的价格买走了 8 个。
目标文本:商店共 * 个苹果,小明以 * 元每斤的价格买走了 * 个。
看完这道题目,小 R 心想:“前段时间刚学过正则表达式,用它来处理这个问题正合适!”翻了翻正则表达式模块 re 的官方文档后,他很快锁定了目标:re.sub() 函数。
re.sub(pattern, repl, string, count, flags) 是正则表达式模块所提供的字符串替换函数,它接收五个参数。
(1)pattern:需要匹配的正则模式。
(2)repl:用于替换的目标内容,可以是字符串或函数。
(3)string:待替换的目标字符串。
(4)count:最大替换次数,默认为 0,表示不限制次数。
(5) flags:正则匹配标志,比如 re.IGNORECASE 代表不区分大小写。
使用 re.sub() 函数,小 R 很快解出了练习题的答案,如代码清单 7-1 所示。
代码清单 7-1 用正则替换连续数字的函数代码
import re
def mosaic_string(s):
"""用 * 替换输入字符串里面所有的连续数字"""
return re.sub(r'\d+', '*', s) ➊
❶ 正则小知识入门:此处 pattern 中的 \d 表示 0~9 的所有数字,+ 表示重复 1 次以上
调用效果如下:
>>> mosaic_string("商店共 100 个苹果,小明以 12 元每斤的价格买走了 8 个")
'商店共 * 个苹果,小明以 * 元每斤的价格买走了 * 个'
完成练习题后,小 R 点击了“下一步”按钮,没想到屏幕上出现了新的要求。
恭喜你完成了第一步,但这只是热身运动。
现在请进一步修改函数,保留每个被替换数字的原始长度,比如 100 应该被替换成 ***。
使用函数
看到新的问题说明后,小 R 觉得这个需求仍然可以用 re.sub() 函数满足,于是他重新认真翻了一遍函数文档,果然找到了办法。
原来,在使用 re.sub(pattern, repl, string) 函数时,第二个参数 repl 不光可以是普通字符串,还可以是一个可调用的函数对象。
如果要用等长的星号来替换所有数字,只要先定义如代码清单 7-2 所示的函数。
代码清单 7-2 用等长星号替换数字
def mosaic_matchobj(matchobj): ➊
"""将匹配到的模式替换为等长星号字符串"""
length = len(matchobj.group())
return '*' * length
❶ 用作 repl 参数的函数必须接收一个参数:matchobj,它的值是当前匹配到的对象。
然后将它作为 repl 参数,就能实现题目要求的效果:
def mosaic_string(s):
"""用等长的 * 替换输入字符串里面所有的连续数字"""
return re.sub(r'\d+', mosaic_matchobj, s)
调用结果如下:
>>> mosaic_string("商店共 100 个苹果,小明以 12 元每斤的价格买走了 8 个")
'商店共 *** 个苹果,小明用 ** 元的价格买走了 * 个'
解决问题后,小 R 高兴地点击了“下一步”。不出所料,屏幕上又出现了新的需求。
恭喜你完成了问题,现在请迎接最终挑战。
请在替换数字时加入一些更有趣的逻辑——全部使用星号 * 来替换,显得有些单调,如果能轮换使用 * 和 x 两种符号就好了。
举个例子,“商店共 100 个苹果,小明以 12 元每斤的价格买走了 8 个”被替换后应该变成“商店共 *** 个苹果,小明以 xx 元每斤的价格买走了 * 个”。
给函数加上状态:全局变量
看到新的问题后,小 R 陷入了思考。
截至上一个问题,小 R 所写的 mosaic_matchobj() 函数只是一个无状态函数。但为了满足新需求,小 R 需要调整 mosaic_matchobj() 函数,把它从一个无状态函数改为有状态函数。
这里的“状态”,当然就是指它需要记录每次调用时应该使用 * 还是 x 符号。
给函数加上状态的办法有很多,而全局变量通常是最容易想到的方式。
为了实现每次调用时轮换马赛克字符,小 R 可以直接定义一个全局变量 _mosaic_char_index,用它来记录函数当前使用了 ‘*’ 还是 ‘x’ 字符。只要在每次调用函数时修改它的值,就能实现轮换功能。
函数代码如代码清单 7-3 所示。
代码清单 7-3 使用全局变量的有状态替换函数
_mosaic_char_index = 0
def mosaic_global_var(matchobj):
"""
将匹配到的模式替换为其他字符,使用全局变量实现轮换字符效果
"""
global _mosaic_char_index ➊
mosaic_chars = ['*', 'x']
char = mosaic_chars[_mosaic_char_index]
# 递增马赛克字符索引值
_mosaic_char_index = (_mosaic_char_index + 1) % len(mosaic_chars)
length = len(matchobj.group())
return char * length
❶ 使用 global 关键字声明一个全局变量
经过测试,函数可以满足要求:
>>> print(re.sub(r'\d+', mosaic_global_var, '商店共 100 个苹果,小明以 12 元每斤的价格买走了 8 个'))
商店共 *** 个苹果,小明以 xx 元每斤的价格买走了 * 个
虽然全局变量能满足需求,而且看上去似乎挺简单,但千万不要被它的外表蒙蔽了双眼。用全局变量保存状态,其实是写代码时最应该避开的事情之一。
为什么这么说?其中的原因有很多。
首先,上面这种方式封装性特别差,代码里的 mosaic_global_var() 函数不是一个完整可用的对象,必须配合一个模块级状态 _mosaic_char_index 使用。
其次,上面这种方式非常脆弱。如果多个模块在不同线程里,同时导入并使用 mosaic_global_var() 函数,整个字符轮换的逻辑就会乱掉,因为多个调用方共享同一个全局标记变量 _mosaic_char_index。
最后,现在的函数提供的调用结果甚至都不稳定。如果连续调用函数,就会出现下面这种情况:
>>> print(re.sub(r'\d+', mosaic_global_var, '商店共 100 个苹果,小明以 12 元每斤的价格买走了 8 个')) ➊
商店共 *** 个苹果,小明以 xx 元每斤的价格买走了 * 个
>>> print(re.sub(r'\d+', mosaic_global_var, '商店共 100 个苹果,小明以 12 元每斤的价格买走了 8 个')) ➋
商店共 xxx 个苹果,小明以 ** 元每斤的价格买走了 x 个
❶ 首次调用,从 * 符号开始
❷ 第二次调用,因为全局标记没有被重置,刚好轮换到从 x 而不是 * 开始
总而言之,用全局变量管理状态,在各种场景下几乎都是下策,仅可在迫不得已时作为终极手段使用。
除了全局变量以外,小 R 还可以使用另一个办法:闭包。
给函数加上状态:闭包
闭包(closure)是编程语言领域里的一个专有名词。简单来说,闭包是一种允许函数访问已执行完成的其他函数里的私有变量的技术,是为函数增加状态的另一种方式。
正常情况下,当 Python 完成一次函数执行后,本次使用的局部变量都会在调用结束后被回收,无法继续访问。但是,如果你使用下面这种“函数套函数”的方式,在外层函数执行结束后,返回内嵌函数,后者就可以继续访问前者的局部变量,形成了一个“闭包”结构,如代码清单 7-4 所示。
代码清单 7-4 闭包示例
def counter():
value = 0
def _counter():
# nonlocal 用来标注变量来自上层作用域,如不标明,内层函数将无法直接修改外层函数变量
nonlocal value
value += 1
return value
return _counter
调用 counter 返回的结果函数,可以继续访问本该被释放的 value 变量的值:
>>> c = counter()
>>> c()
1
>>> c()
2
>>> c2 = counter() ➊
>>> c2()
1
❶ 创建一个与 c 无关的新闭包对象 c2
得益于闭包的这个特点,小 R 可以用它来实现“会轮换字符的马赛克函数”,如代码清单 7-5 所示。
代码清单 7-5 使用闭包的有状态替换函数
def make_cyclic_mosaic():
"""
将匹配到的模式替换为其他字符,使用闭包实现轮换字符效果
"""
char_index = 0
mosaic_chars = ['*', 'x']
def _mosaic(matchobj):
nonlocal char_index
char = mosaic_chars[char_index]
char_index = (char_index + 1) % len(mosaic_chars)
length = len(matchobj.group())
return char * length
return _mosaic
调用效果如下:
>>> re.sub(r'\d+', make_cyclic_mosaic(), '商店共 100 个苹果,小明以 12 元每斤的价格买走了
8 个') ➊
'商店共 *** 个苹果,小明以 xx 元每斤的价格买走了 * 个'
>>> re.sub(r'\d+', make_cyclic_mosaic(), '商店共 100 个苹果,小明以 12 元每斤的价格买走了
8 个') ➋
'商店共 *** 个苹果,小明以 xx 元每斤的价格买走了 * 个'
❶ 注意:此处是 make_cyclic_mosaic() 而不是 make_cyclic_mosaic,因为 make_cyclic_mosaic() 函数的调用结果才是真正的替换函数
❷ 重复调用时使用新的闭包函数对象,计数器重新从 0 开始,没有结果不稳定问题
相比全局变量,使用闭包最大的特点就是封装性要好得多。在闭包代码里,索引变量 called_cnt 完全处于闭包内部,不会污染全局命名空间,而且不同闭包对象之间也不会相互影响。
总而言之,闭包是一种非常有用的工具,非常适合用来实现简单的有状态函数。
不过,除了闭包之外,还有一个天生就适合用来实现“状态”的工具:类。
给函数加上状态:类
类(class)是面向对象编程里最基本的概念之一。在一个类中,状态和行为可以被很好地封装在一起,因此它天生适合用来实现有状态对象。
通过类,我们可以生成一个个类实例,而这些实例对象的方法,可以像普通函数一样被调用。正因如此,小 R 也可以完全用类来实现一个“会轮换屏蔽字符的马赛克对象”,如代码清单 7-6 所示。
代码清单 7-6 基于类实现有状态替换方法
class CyclicMosaic:
"""使用会轮换的屏蔽字符,基于类实现"""
_chars = ['*', 'x']
def __init__(self):
self._char_index = 0 ➊
def generate(self, matchobj):
char = self._chars[self._char_index]
self._char_index = (self._char_index + 1) % len(self._chars)
length = len(matchobj.group())
return char * length
❶ 类实例的状态一般都在 init 函数里初始化
在调用时,需要先初始化一个 CycleMosaic 实例,然后使用它的 generate 方法:
>>> re.sub(r'\d+', CycleMosaic().generate, '商店共 100 个苹果,小明以 12 元每斤的价格买走了 8 个')
'商店共 *** 个苹果,小明以 xx 元每斤的价格买走了 * 个'
使用类和使用闭包一样,也可以很好地满足需求。
不过严格说来,这个方案最终依赖的 CycleMosaic().generate,并非一个有状态的函数,而是一个有状态的实例方法。但无论是函数还是实例方法,它们都是“可调用对象”的一种,都可以作为 re.sub() 函数的 repl 参数使用。
权衡了这三种方案的利弊后,小 R 最终选择了第三种基于类的方案,完成了这道练习题。
小结
在小 R 解答练习题的过程中,一共出现了三种实现有状态函数的方式,这三种方式各有优缺点,总结如下。
基于全局变量:
学习成本最低,最容易理解;
会增加模块级的全局状态,封装性和可维护性最差。
基于函数闭包:
学习成本适中,可读性较好;
适合用来实现变量较少,较简单的有状态函数。
创建类来封装状态:
学习成本较高;
当变量较多、行为较复杂时,类代码比闭包代码更易读,也更容易维护。
在日常编码中,如果你需要实现有状态的函数,应该尽量避免使用全局变量,闭包或类才是更好的选择。
7.3 编程建议
7.3.1 别写太复杂的函数
你有没有在项目中见过那种长达几百行、逻辑错综复杂的“巨无霸”函数?那样的函数不光难读,改起来同样困难重重,人人唯恐避之不及。所以,我认为编写函数最重要的原则就是:别写太复杂的函数。
为了避免写出太复杂的函数,第一个要回答的问题是:什么样的函数才能算是过于复杂?我一般会通过两个标准来判断。
长度
第一个标准是长度,也就是函数有多少行代码。
诚然,我们不能武断地说,长函数就一定比短函数复杂。因为在不同的编程风格下,相同行数的代码所实现的功能可以有巨大差别,有人甚至能把一个完整的俄罗斯方块游戏塞进一行代码内。
但即便如此,长度对于判断函数复杂度来说仍然有巨大价值。在著作《代码大全(第 2 版)》中,Steve McConnell 提到函数的理想长度范围是 65 到 200 行,一旦超过 200 行,代码出现 bug 的概率就会显著增加。
从我自身的经验来看,对于 Python 这种强表现力的语言来说,65 行已经非常值得警惕了。假如你的函数超过 65 行,很大概率代表函数已经过于复杂,承担了太多职责,请考虑将它拆分为多个小而简单的子函数(类)吧。
圈复杂度
第二个标准是“圈复杂度”(cyclomatic complexity)。
“圈复杂度”是由 Thomas J. McCabe 在 1976 年提出的用于评估函数复杂度的指标。它的值是一个正整数,代表程序内线性独立路径的数量。圈复杂度的值越大,表示程序可能的执行路径就越多,逻辑就越复杂。
如果某个函数的圈复杂度超过 10,就代表它已经太复杂了,代码编写者应该想办法简化。优化写法或者拆分成子函数都是不错的选择。
接下来,我们通过实际代码来体验一下圈复杂度的计算过程。
在 Python 中,你可以通过 radon 工具计算一个函数的圈复杂度。radon 基于 Python 编写,使用 pip install radon 即可完成安装。
安装完成后,接下来就是找到一份需要计算圈复杂度的代码。在这里,我将使用第 4 章案例里的“按照电影分数计算评级”的函数:
def rank(self):
rating_num = float(self.rating)
if rating_num >= 8.5:
return 'S'
elif rating_num >= 8:
return 'A'
elif rating_num >= 7:
return 'B'
elif rating_num >= 6:
return 'C'
else:
return 'D'
执行 radon 命令,就可以查看上面这个函数的圈复杂度:
> radon cc complex_func.py -s
complex_func.py
F 1:0 rank - A (5)
可以看到,有着大段 if/elif 的 rank() 函数的圈复杂度为 5,评级为 A。虽然这个值没有达到危险线 10,但考虑到函数只有短短 10 行,5 已经足够引起重视了。
作为对比,我们再计算一下案例中使用 bisect 模块重构后的 rank() 函数:
def rank(self):
breakpoints = (6, 7, 8, 8.5)
grades = ('D', 'C', 'B', 'A', 'S')
index = bisect.bisect(breakpoints, float(self.rating))
return grades[index]
重构后函数的圈复杂度如下:
radon cc complex_func.py -s
complex_func.py
F 1:0 rank - A (1)
可以看到,新函数的圈复杂度从 5 降至 1。1 是一个非常理想化的值,如果一个函数的圈复杂度为 1,就代表这个函数只有一条主路径,没有任何其他执行路径,这样的函数通常来说都十分简单、容易维护。
当然,在正常的项目开发流程中,我们一般不会在每次写完代码后,都手动执行一次 radon 命令检查函数圈复杂度是否符合标准,而会将这种检查配置到开发或部署流程中自动执行。在第 13 章中,我将继续介绍这部分内容。
7.3.2 一个函数只包含一层抽象
在 5.2.2 节中,我分享过一个与抽象一致性有关的案例。在那个案例中,函数抛出了高于自身抽象级别的异常,导致代码很难复用。于是我们得出结论:保证函数抛出的异常与自身抽象级别一致非常重要。
但抽象级别对函数设计的影响远不止于此。在本节中,我们将继续探讨这个话题。不过在那之前,我先提出一个问题:“抽象级别到底是什么?”
要解释抽象级别,得从解释“抽象”开始。
什么是抽象
打开维基百科的 Abstraction 词条页面,你可以找到抽象的定义。通用领域里的“抽象”,是指在面对复杂事物(或概念)时,主动过滤掉不需要的细节,只关注与当前目的有关的信息的过程。
光看概念,抽象似乎挺玄乎,但其实不然,抽象不光不玄乎,而且很自然——人类每天都在使用抽象能力。
举个例子,我吃完饭在大街上散步,走得有点儿累了,于是对自己说:“腿真疼啊,找把椅子坐吧。”此时此刻,“椅子”在我脑中就是一个抽象的概念。
我脑中的椅子:
有一个平坦的表面可以把屁股放上去;
离地 20 到 50 厘米,能支撑 60 千克以上的重量。
对这个抽象概念来说,路边的金属黑色长椅是我需要的椅子,饭店门口的塑料扶手椅同样也是我需要的椅子,甚至某个一尘不染的台阶也可以成为我要的“椅子”。
在这个抽象下,椅子的其他特征,比如使用什么材料(木材还是金属)、涂的什么颜色(白色还是黑色),对于我来说都不重要。于是在一次逛街中,我不知不觉完成了一次对椅子的抽象,解决了屁股坐哪儿的问题。
所以简单来说,抽象就是一种选择特征、简化认知的手段。接下来,我们看看抽象与软件开发的关系。
抽象与软件开发
在计算机科学领域里,人们广泛使用了抽象能力,并围绕抽象发明了许多概念和理论,而分层思想就是其中最重要的概念之一。
什么是分层?分层就在设计一个复杂系统时,按照问题抽象程度的高低,将系统划分为不同的抽象层(abstraction layer)。低级的抽象层里包含较多的实现细节。随着层级变高,细节越来越少,越接近我们想要解决的实际问题。
举个例子,计算机网络体系里的 7 层 OSI 模型(如图 7-1 所示),就应用了这种分层思想。
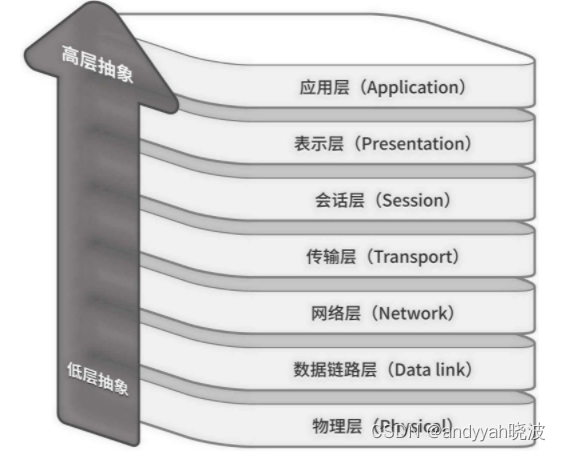
图 7-1 计算机网络 7 层 OSI 模型示意图
在 OSI 模型的第一层物理层,主要关注原始字节流如何通过物理媒介传输,牵涉针脚、集线器等各种细节。而第七层应用层则更贴近终端用户,这层包含的都是我们日常用到的东西,比如浏览网页的 HTTP 协议、发送邮件的 SMTP 协议,等等。
在这种分层结构下,每一层抽象都只依赖比它抽象级别更低的层,同时对比它抽象级别更高的层一无所知。因此,每层都可以脱离更高级别的层独立工作。比如活跃在传输层的 TCP 协议,可以对应用层的 HTTP、HTTPS 等应用协议毫无感知,独立工作。
分层是一种特别有用的设计理念。基于分层,我们可以把复杂系统的诸多细节封装到各个独立的抽象层中,每一层只关注特定内容,复杂度得到大大降低,系统也变得更容易理解。
正因为抽象与分层理论特别有用,所以不管你有没有意识到,其实在各个维度上都活跃着“分层”的身影,如下所示。
项目间的分层:电商后端 API(高层抽象)→数据库(低层抽象)。
项目内的分层:账单模块(高层抽象)→ Django 框架(低层抽象)。
模块内的分层:函数名–获取账户信息(高层抽象)→函数内–处理字符串(低层抽象)。
无论在哪个维度上,随意混合抽象级别、打破分层都会导致不好的后果。
举个例子,电商网站需要开发一个用户抽奖功能。不在电商后端项目里增加模块,而是通过堆砌大量数据库内置函数,写出长达 1000 行的 SQL 语句实现了需求的核心逻辑。试问,这样的 SQL 语句有几个人能看明白,再过一个月,恐怕作者自己都看不懂吧。
因此,即便是在非常微观的层面上,比如编写一个函数时,我们同样需要考虑函数内代码与抽象级别的关系。假如一个函数内同时包含了多个抽象级别的内容,就会引发一系列的问题。
接下来,我们通过一份真实的代码来看看如何确定函数的抽象级别。
脚本案例:调用 API 查找歌手的第一张专辑
iTunes 是苹果公司提供的内容商店服务,在里面可以购买世界各地的电影、音乐等数字内容。
同时,iTunes 还提供了一个公开的可免费调用的内容查询 API。下面这个脚本就通过调用该 API 实现了查找歌手的第一张专辑的功能。
first_album.py 脚本的完整代码如下:
"""通过 iTunes API 搜索歌手发布的第一张专辑"""
import sys
from json.decoder import JSONDecodeError
import requests
from requests.exceptions import HTTPError
ITUNES_API_ENDPOINT = 'https://itunes.apple.com/search'
def command_first_album():
"""通过脚本输入查找并打印歌手的第一张专辑信息"""
if not len(sys.argv) == 2:
print(f'usage: python {sys.argv[0]} {{SEARCH_TERM}}')
sys.exit(1)
term = sys.argv[1]
resp = requests.get(
ITUNES_API_ENDPOINT,
{
'term': term,
'media': 'music',
'entity': 'album',
'attribute': 'artistTerm',
'limit': 200,
},
)
try:
resp.raise_for_status()
except HTTPError as e:
print(f'Error: failed to call iTunes API, {e}')
sys.exit(2) ➊
try:
albums = resp.json()['results']
except JSONDecodeError:
print(f'Error: response is not valid JSON format')
sys.exit(2)
if not albums:
print(f'Error: no albums found for artist "{term}"')
sys.exit(1)
sorted_albums = sorted(albums, key=lambda item: item['releaseDate'])
first_album = sorted_albums[0]
# 去除发布日期里的小时与分钟信息
release_date = first_album['releaseDate'].split('T')[0]
# 打印结果
print(f"{term}'s first album: ")
print(f" * Name: {first_album['collectionName']}")
print(f" * Genre: {first_album['primaryGenreName']}")
print(f" * Released at: {release_date}")
if __name__ == '__main__':
command_first_album()
❶ 当脚本执行异常时,应该使用非 0 返回码,这是编写脚本的规范之一
执行看看效果:
> python first_album.py ➊
usage: python first_album.py {SEARCH_TERM}
> python first_album.py "linkin park" ➋
linkin park's first album:
* Name: Hybrid Theory
* Genre: Hard Rock
* Released at: 2000-10-24
> python first_album.py "calfoewf#@#FE" ➌
Error: no albums found for artist "calfoewf#@#FE"
❶ 没有提供参数时,打印错误信息并返回
❷ 执行正常,打印专辑信息(《Hybrid Theory》超好听!)
❸ 输入参数没有匹配到任何专辑,打印错误信息
脚本抽象级别分析
这个脚本实现了我们想要的效果,那么它的代码质量怎么样呢?我们从长度、圈复杂度、嵌套层级几个维度来看看:
(1) 主函数 command_first_album() 共 40 行代码;
(2) 函数圈复杂度为 5;
(3) 函数内最大嵌套层级为 1。
看上去每个维度都在合理范围内,没有什么问题。但是,除了上面这些维度外,评价函数好坏还有一个重要标准:函数内的代码是否在同一个抽象层内。
上面脚本的主函数 command_first_album() 显然不符合这个标准。在函数内部,不同抽象级别的代码随意混合在了一起。比如,当请求 API 失败时(数据层),函数直接调用 sys.exit() 中断了程序执行(用户界面层)。
这种抽象级别上的混乱,最终导致了下面两个问题。
函数代码的说明性不够:如果只是简单读一遍 command_first_album(),很难搞清楚它的主流程是什么,因为里面的代码五花八门,什么层次的信息都有。
函数的可复用性差:假如现在要开发新需求——查询歌手的所有专辑,你无法复用已有函数的任何代码。
所以,如果缺乏设计,哪怕是一个只有 40 行代码的简单函数,内部也很容易产生抽象混乱问题。要优化这个函数,我们需要重新梳理程序的抽象级别。
在我看来,这个程序至少可以分为以下三层。
(1) 用户界面层:处理用户输入、输出结果。
(2) “第一张专辑”层:找到第一张专辑。
(3) 专辑数据层:调用 API 获取专辑信息。
在每一个抽象层内,程序所关注的事情都各不相同,如图 7-2 所示。
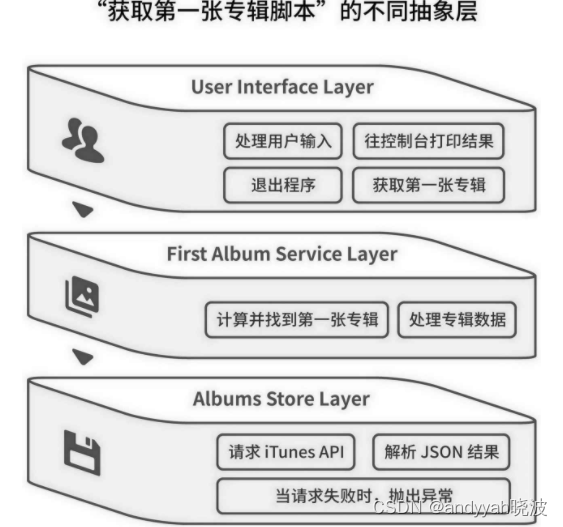
图 7-2 “获取第一张专辑脚本”的不同抽象层
基于这样的层级设计,我们可以对原始函数进行拆分。
基于抽象层重构代码
重构后的脚本 first_album_new.py 的代码如下:
""" 通过 iTunes API 搜索歌手发布的第一张专辑"""
import sys
from json.decoder import JSONDecodeError
import requests
from requests.exceptions import HTTPError
ITUNES_API_ENDPOINT = 'https://itunes.apple.com/search'
class GetFirstAlbumError(Exception):
""" 获取第一张专辑失败"""
class QueryAlbumsError(Exception):
"""获取专辑列表失败"""
def command_first_album():
"""通过输入参数查找并打印歌手的第一张专辑信息"""
if not len(sys.argv) == 2:
print(f'usage: python {sys.argv[0]} {{SEARCH_TERM}}')
sys.exit(1)
artist = sys.argv[1]
try:
album = get_first_album(artist)
except GetFirstAlbumError as e:
print(f"error: {e}", file=sys.stderr)
sys.exit(2)
print(f"{artist}'s first album: ")
print(f" * Name: {album['name']}")
print(f" * Genre: {album['genre_name']}")
print(f" * Released at: {album['release_date']}")
def get_first_album(artist):
"""根据专辑列表获取第一张专辑
:param artist: 歌手名字
:return: 第一张专辑
:raises: 获取失败时抛出 GetFirstAlbumError
"""
try:
albums = query_all_albums(artist)
except QueryAlbumsError as e:
raise GetFirstAlbumError(str(e))
sorted_albums = sorted(albums, key=lambda item: item['releaseDate'])
first_album = sorted_albums[0]
# 去除发布日期里的小时与分钟信息
release_date = first_album['releaseDate'].split('T')[0]
return {
'name': first_album['collectionName'],
'genre_name': first_album['primaryGenreName'],
'release_date': release_date,
}
def query_all_albums(artist):
"""根据歌手名字搜索所有专辑列表
:param artist: 歌手名字
:return: 专辑列表,List[Dict]
:raises: 获取专辑失败时抛出 GetAlbumsError
"""
resp = requests.get(
ITUNES_API_ENDPOINT,
{
'term': artist,
'media': 'music',
'entity': 'album',
'attribute': 'artistTerm',
'limit': 200,
},
)
try:
resp.raise_for_status()
except HTTPError as e:
raise QueryAlbumsError(f'failed to call iTunes API, {e}')
try:
albums = resp.json()['results']
except JSONDecodeError:
raise QueryAlbumsError('response is not valid JSON format')
if not albums:
raise QueryAlbumsError(f'no albums found for artist "{artist}"')
return albums
if __name__ == '__main__':
command_first_album()
在新代码中,旧的主函数被拆分成了三个不同的函数。
command_first_album():程序主入口,对应用户界面层。
get_first_album():获取第一张专辑,对应“第一张专辑”层。
query_all_albums():调用 API 获取数据,对应专辑数据层。
经过调整后,脚本里每个函数内的所有代码都只属于同一个抽象层。这大大提升了函数代码的说明性。现在,当你在阅读每个函数时,可以很清晰地知道它在做什么事情。
同时,把大函数拆分成几个更小的函数后,代码的可复用性也得到了提升。假如现在要开发“查询所有专辑”功能,我们可以直接复用 query_all_albums() 函数完成工作。
在设计函数时,请时常记得检查函数内代码是否在同一个抽象级别,如果不是,那就需要把函数拆成更多小函数。只有保证抽象级别一致,函数的职责才更简单,代码才更易读、更易维护。
7.3.3 优先使用列表推导式
函数式编程是一种编程风格,它最大的特征,就是通过组合大量没有副作用的“纯函数”来实现复杂的功能。如果你想在 Python 中实践函数式编程,最常用的几个工具如下所示。
(1) map(func, iterable):遍历并执行 func 获取结果,迭代返回新结果。
(2) filter(func, iterable):遍历并使用 func 测试成员,仅当结果为真时返回。
(3) lambda:定义一个一次性使用的匿名函数。
举个例子,假如你想获取所有处于活跃状态的用户积分,代码可以这么写:
points = list(map(query_points, filter(lambda user: user.is_active(), users)))
不需要任何循环和分支,只要一条函数式的表达式就能完成工作。
但比起上面这种 map 套 filter 的写法,我们其实完全可以使用列表推导式来搞定这个问题:
points = [query_points(user) for user in users if user.is_active()]
在大多数情况下,相比函数式编程,使用列表推导式的代码通常更短,而且描述性更强。所以,当列表推导式可以满足需求时,请优先使用它吧。
7.3.4 你没有那么需要 lambda
Python 中有一类特殊的函数:匿名函数。你可以用 lambda 关键字来快速定义一个匿名函数,比如 lambda x, y: x + y。匿名函数最常见的用途就是作为 sorted() 函数的排序参数使用。
但有时,我们会过于习惯使用 lambda,而写出下面这样的代码:
>>> l = ['87', '3', '10']
# 转换为整数后排序
>>> sorted(l, key=lambda n: int(n))
['3', '10', '87']
仔细观察上面的代码,你能发现问题在哪吗?在这段代码里,为了排序,我们定义了一个 lambda 函数,但这个函数其实什么都没干,只是把调用透传给 int() 而已。
所以,上面代码里的匿名函数完全是多余的,可以直接去掉:
>>> sorted(l, key=int)
['3', '10', '87']
这样的代码更短,也更好理解。
在使用 lambda 函数时,还有一类常见的使用场景——用匿名函数做一些简单的操作运算,比如通过 key 获取字典值、通过属性名获取对象值,等等。
用 lambda 获取字典某个 key 的值:
>>> sorted(data, key=lambda obj: obj['name'])
对于这种进行简单操作的匿名函数,我们其实完全可以用 operator 模块里的函数来替代。比如使用 operator.itemgetter() 就可以直接实现“获取某个 key 的值”操作:
>>> from operator import itemgetter
>>> itemgetter('name')({'name': 'foo'}) ➊
'foo'
❶ 调用 itemgetter(‘name’) 会生成一个新函数,使用 obj 参数调用新函数,效果等同于表达式 obj[‘name’]
前面 sorted() 使用的 lambda 函数也可以直接用 itemgetter() 替代:
>>> sorted(data, key=itemgetter('name'))
除了 itemgetter() 以外,operator 模块里还有许多有用的函数,它们都可以用来替代简单的操作运算类匿名函数,比如 add()、attrgetter() 等,详细列表可以查询官方文档。
总之,Python 中的 lambda 函数只是一颗简单的语法糖。它的许多使用场景,要么本身就不存在,要么更适合用 operator 模块来满足。lambda 并非无可替代。
当你确实想要编写 lambda 函数时,请尝试问自己一个问题:“这个功能用 def 写一个普通函数是不是更合适?”尤其当需求比较复杂时,千万别试着把大段逻辑糅进一个巨大的匿名函数里。请记住,没什么特殊功能是 lambda 能做而普通函数做不到的。
7.3.5 了解递归的局限性
递归(recursion)是指函数在执行时依赖调用自身来完成工作,是一种非常有用的编程技巧。在实现一些特定算法时,使用递归的代码更符合人们的思维习惯,有着天然的优势。
比如,下面计算斐波那契数列(Fibonacci sequence)的函数就非常容易理解:
def fib(n):
if n < 2:
return n
return fib(n-1) + fib(n-2)
斐波那契数列的第一个成员和第二个成员是 0 和 1,随后的每个成员都是前两个成员之和,比如 [0, 1, 1, 2, 3, 5, …]。
使用它获取数列的前 10 位成员:
>>> [fib(i) for i in range(10)]
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
虽然上面的函数代码很直观,但用起来有一些限制。比如当需要计算的数字很大时,上面的 fib(n) 函数在执行时会形成一个非常深的嵌套调用栈,当它的深度超过一定限制后,函数就会抛出 RecursionError 异常:
>>> fib(1000)
Traceback (most recent call last):
...
[Previous line repeated 995 more times]
File "fib.py", line 2, in fib
if n < 2:
RecursionError: maximum recursion depth exceeded in comparison
这个最大递归深度限制由 Python 在语言层面上设置,你可以通过下面的命令查看和修改这个限制:
>>> import sys
>>> sys.getrecursionlimit()
1000
>>> sys.setrecursionlimit(10000) ➊
❶ 你也可以手动把限制修改成 10 000 层,但我们一般不这么做
在编程语言领域,为了避免递归导致调用栈过深,占用过多资源,不少编程语言使用一种被称为尾调用优化(tail call optimization)的技术。这种技术能将 fib() 函数里的递归优化成循环,以此避免嵌套层级过深,提升性能。
但 Python 没有这种技术。因此在使用递归时,你必须对函数的输入数据规模时刻保持警惕,确保它所触发的递归深度,一定远远低于 sys.getrecursionlimit() 的最大限制。
当然,仅针对上面的 fib() 函数来说,它对递归的使用其实有许多值得优化的地方。第一个点就是 fib() 函数会触发太多重复计算,它的算法时间复杂度是 O(2^n)。因此,只要用 @lru_cache 给它加上缓存,就可以极大地提升性能:
from functools import lru_cache
@lru_cache
def fib(n): ...
使用 @lru_cache 优化斐波那契数列计算,其实就是 functools 模块官方文档里的一个例子。
这样做以后,程序就免去了许多重复计算,可以极大地提升执行效率。
不过,添加 @lru_cache 也仅仅能提升它的效率,如果输入数字过大,函数执行时还是会超过最大递归深度限制。对于任何递归代码来说,一劳永逸的办法是将其改写成循环。
下面这个函数就是用循环实现的斐波那契数列,它的调用效果和递归函数 fib() 一模一样:
def fib_loop(n):
a, b = 0, 1
for i in range(n):
a, b = b, a + b
return a
改写为循环后,新函数不会因为输入数字过大而触发递归深度报错,并且它的算法时间复杂度也远比旧函数低,执行效率更高。
总而言之,Python 里的递归因为缺少语言层面的优化,局限性较大。当你想用递归来实现某个算法时,请先琢磨琢磨是否能用循环来改写。如果答案是肯定的,那就改成循环吧。
但像上面的例子一样,能被简单重写为循环的递归代码毕竟是少数。假如递归确实能带来许多方便,当你决意要使用它时,请务必注意不要超过最大递归深度限制。
7.4 总结
在本章中,我们学习了在 Python 中编写函数的相关知识。
在设计函数参数时,请不要使用可变类型作为默认参数,而应该用 None 来替代。你可以定义仅限关键字参数,来提高函数调用的可读性。在函数中返回结果时,应该尽量保证返回值类型的统一,在想要返回 None 值时,应该考虑是否可以用抛出异常来替代。
functools 模块中有许多有用的工具,你可以查阅官方文档了解更多内容。
在案例故事中,我介绍了在函数中保存状态的几种常见方式,包括全局变量、闭包、类方法等。闭包和类是编写有状态函数的两种推荐工具。
最后我想说的是,虽然函数可以消除重复代码,但绝不能只把它看成一种复用代码的工具。函数最重要的价值其实是创建抽象,而提供复用价值甚至可以算成抽象所带来的一种“副作用”。
因此,要想写出好的函数,秘诀就在于设计好的抽象,这就是为什么我说不要写太复杂的函数(导致抽象不精确),每个函数只应该包含一层抽象。
以下是本章要点知识总结。
(1) 函数参数与返回相关基础知识
不要使用可变类型作为参数默认值,用 None 来代替
使用标记对象,可以严格区分函数调用时是否提供了某个参数
定义仅限关键字参数,可以强制要求调用方提供参数名,提升可读性
函数应该拥有稳定的返回类型,不要返回多种类型
适合返回 None 的情况——操作类函数、查询类函数表示意料之中的缺失值
在执行失败时,相比返回 None,抛出异常更为合适
如果提前返回结果可以提升可读性,就提前返回,不必追求“单一出口”
(2) 代码可维护性技巧
不要编写太长的函数,但长度并没有标准,65 行算是一个危险信号
圈复杂度是评估函数复杂程度的常用指标,圈复杂度超过 10 的函数需要重构
抽象与分层思想可以帮我们更好地构建与管理复杂的系统
同一个函数内的代码应该处在同一抽象级别
(3) 函数与状态
没有副作用的无状态纯函数易于理解,容易维护,但大多数时候“状态”不可避免
避免使用全局变量给函数增加状态
当函数状态较简单时,可以使用闭包技巧
当函数需要较为复杂的状态管理时,建议定义类来管理状态
(4) 语言机制对函数的影响
functools.partial() 可以用来快速构建偏函数
functools.lru_cache() 可以用来给函数添加缓存
比起 map 和 filter,列表推导式的可读性更强,更应该使用
lambda 函数只是一种语法糖,你可以使用 operator 模块等方式来替代它
Python 语言里的递归限制较多,可能的话,请尽量使用循环来替代















 9818
9818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









