







浅析ChatGPT-神经网络
用于图像识别等任务的典型模型到底是如何工作的呢?目前最受欢迎而且最成功的方法是使用神经网络。神经网络发明于 20 世纪 40 年代—它在当时的形式与今天非常接近—可以视作对大脑工作机制的简单理想化。
人类大脑有大约 1000 亿个神经元(神经细胞),每个神经元都能够产生电脉冲,最高可达每秒约 1000 次。这些神经元连接成复杂的网络,每个神经元都有树枝状的分支,从而能够向其他数千个神经元传递电信号。粗略地说,任意一个神经元在某个时刻是否产生电脉冲,取决于它从其他神经元接收到的电脉冲,而且神经元不同的连接方式会有不同的“权重”贡献。
当我们“看到一个图像”时,来自图像的光子落在我们眼睛后面的(光感受器)细胞上,它们会在神经细胞中产生电信号。这些神经细胞与其他神经细胞相连,信号最终会通过许多层神经元。在此过程中,我们“识别”出这个图像,最终“形成”我们“正在看数字 2”的“想法”(也许最终会做一些像大声说出“二”这样的事情)。
上一节中的“黑盒函数”就是这样一个神经网络的“数学化”版本。它恰好有 11 层(只有 4 个“核心层”)。

我们对这个神经网络并没有明确的“理论解释”,它只是在 1998 年作为一项工程被构建出来的,而且被发现可以奏效。(当然,这与把我们的大脑描述为通过生物进化过程产生并没有太大的区别。)
好吧,但是这样的神经网络是如何“识别事物”的呢?关键在于吸引子(attractor)的概念。假设我们有手写数字 1 和 2 的图像。

我们希望通过某种方式将所有的 1“吸引到一个地方”,将所有的 2“吸引到另一个地方”。换句话说,如果一个图像“更有可能是 1”而不是 2,我们希望它最终出现在“1 的地方”,反之亦然。
让我们做一个直白的比喻。假设平面上有一些位置,用点表示(在实际生活场景中,它们可能是咖啡店的位置)。然后我们可以想象,自己从平面上的任意一点出发,并且总是希望最终到达最近的点(即我们总是去最近的咖啡店)。可以通过用理想化的“分水岭”将平面分隔成不同的区域(“吸引子盆地”)来表示这一点。
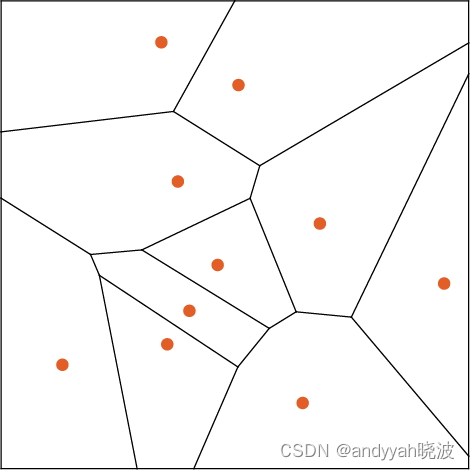
我们可以将这看成是执行一种“识别任务”,所做的不是识别一个给定图像“看起来最像”哪个数字,而是相当直接地看出哪个点距离给定的点最近。[这里展示的沃罗诺伊图(Voronoi diagram)将二维欧几里得空间中的点分隔开来。可以将数字识别任务视为在做一种非常类似的操作—只不过是在由每个图像中所有像素的灰度形成的 784 维空间中。]
那么如何让神经网络“执行识别任务”呢?让我们考虑下面这个非常简单的情况。
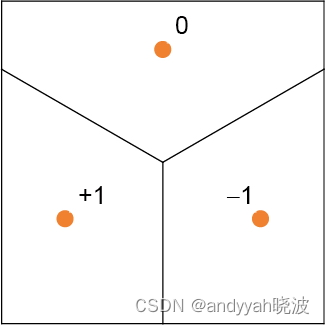
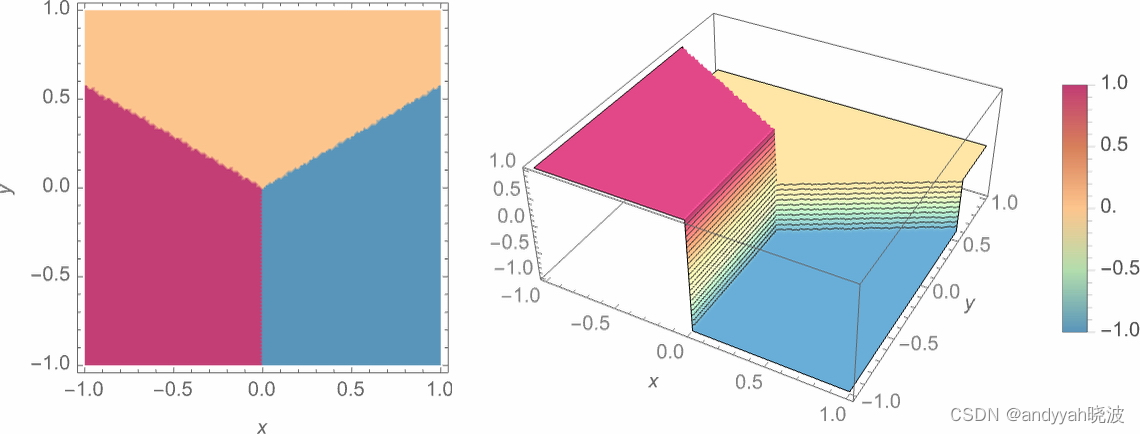
我们的目标是接收一个对应于位置 {x,y} 的输入,然后将其“识别”为最接近它的三个点之一。换句话说,我们希望神经网络能够计算出一个如下图所示的关于 {x,y} 的函数。
如何用神经网络实现这一点呢?归根结底,神经网络是由理想化的“神经元”组成的连接集合—通常是按层排列的。一个简单的例子如下所示。
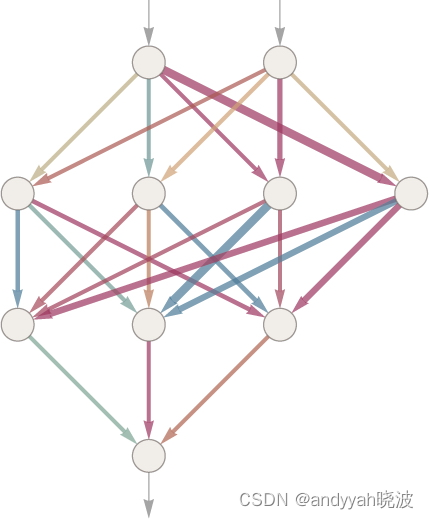
每个“神经元”都被有效地设置为计算一个简单的数值函数。为了“使用”这个网络,我们只需在顶部输入一些数(像我们的坐标 x 和 y),然后让每层神经元“计算它们的函数的值”并在网络中将结果前馈,最后在底部产生最终结果。
在传统(受生物学启发)的设置中,每个神经元实际上都有一些来自前一层神经元的“输入连接”,而且每个连接都被分配了一个特定的“权重”(可以为正或为负)。给定神经元的值是这样确定的:先分别将其“前一层神经元”的值乘以相应的权重并将结果相加,然后加上一个常数,最后应用一个“阈值”(或“激活”)函数。用数学术语来说,如果一个神经元有输入 x={x_1,x_2,\cdots},那么我们要计算 f[w.x+b]。对于权重 w 和常量 b,通常会为网络中的每个神经元选择不同的值;函数 f 则通常在所有神经元中保持不变。
计算 w.x+b 只需要进行矩阵乘法和矩阵加法运算。激活函数 f 则使用了非线性函数(最终会导致非平凡的行为)。下面是一些常用的激活函数,这里使用的是 Ramp(或 ReLU)。

对于我们希望神经网络执行的每个任务(或者说,对于我们希望它计算的每个整体函数),都有不同的权重选择。(正如我们稍后将讨论的那样,这些权重通常是通过利用机器学习根据我们想要的输出的示例“训练”神经网络来确定的。)
最终,每个神经网络都只对应于某个整体的数学函数,尽管写出来可能很混乱。对于上面的例子,它是
同样,ChatGPT 的神经网络也只对应于一个这样的数学函数—它实际上有数十亿项。
现在,让我们回头看看单个神经元。下图展示了一个具有两个输入(代表坐标 x 和 y)的神经元可以通过各种权重和常数(以及激活函数 Ramp)计算出的一些示例。
对于上面提到的更大的网络呢?它的计算结果如下所示。
虽然不完全“正确”,但它接近上面展示的“最近点”函数。
再来看看其他的一些神经网络吧。在每种情况下,我们都使用机器学习来找到最佳的权重选择。这里展示了神经网络用这些权重计算出的结果。
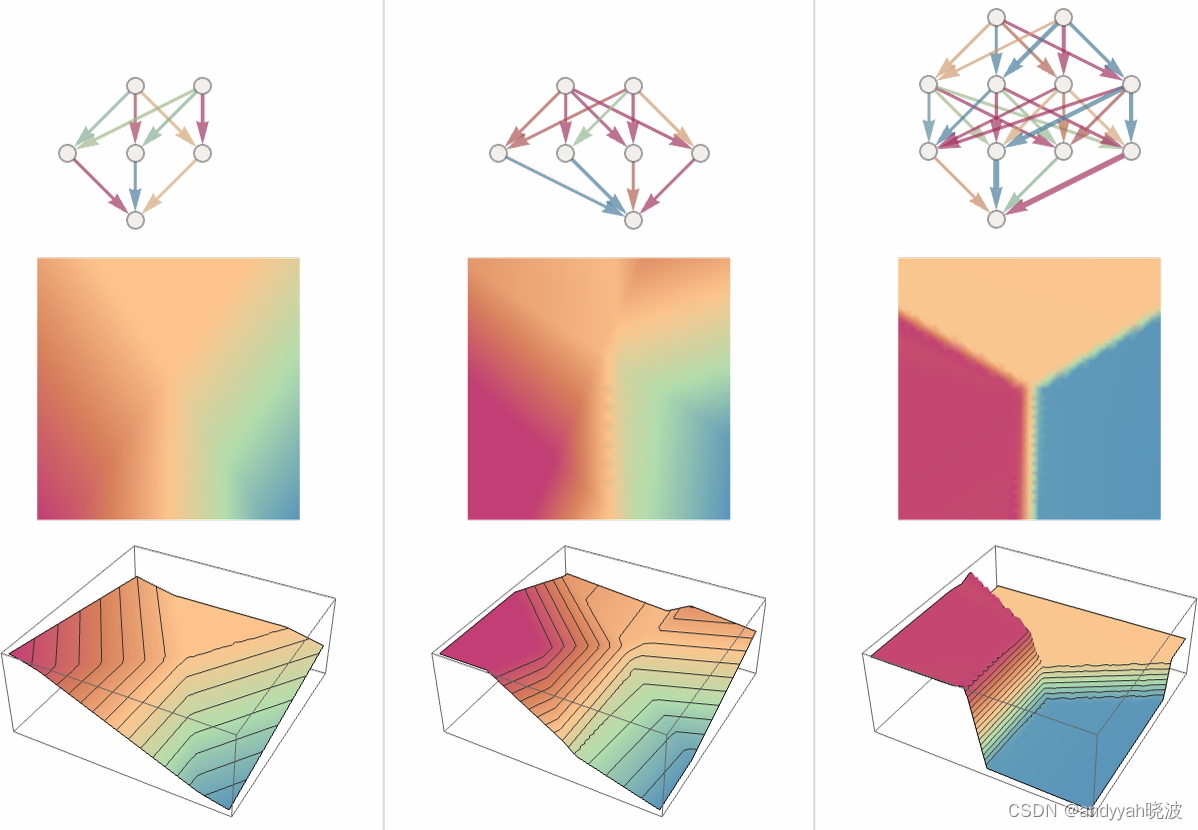
更大的神经网络通常能更好地逼近我们所求的函数。在“每个吸引子盆地的中心”,我们通常能确切地得到想要的答案。但在边界处,也就是神经网络“很难下定决心”的地方,情况可能会更加混乱。
在这个简单的数学式“识别任务”中,“正确答案”显而易见。但在识别手写数字的问题上,答案就不那么明显了。如果有人把 2 写得像 7 一样怎么办?类似的问题非常常见。尽管如此,我们仍然可以询问神经网络是如何区分数字的,下面给出了一个答案。

我们能“从数学上”解释网络是如何做出区分的吗?并不能。它只是在“做神经网络要做的事”。但是事实证明,这通常与我们人类所做的区分相当吻合。
让我们更详细地讨论一个例子。假设我们有猫的图像和狗的图像,以及一个经过训练、能区分它们的神经网络。以下是该神经网络可能对某些图像所做的事情。

这里的“正确答案”更加不明显了。穿着猫咪衣服的狗怎么分?等等。无论输入什么,神经网络都会生成一个答案。结果表明,它的做法相当符合人类的思维方式。正如上面所说的,这并不是我们可以“根据第一性原则推导”出来的事实。这只是一些经验性的发现,至少在某些领域是正确的。但这是神经网络有用的一个关键原因:它们以某种方式捕捉了“类似人类”的做事方式。
找一张猫的图片看看,并问自己:“为什么这是一只猫?”你也许会说“我看到了它尖尖的耳朵”,等等。但是很难解释你是如何把这个图像识别为一只猫的。你的大脑就是不知怎么地想明白了。但是(至少目前还)没有办法去大脑“内部”看看它是如何想明白的。那么,对于(人工)神经网络呢?当你展示一张猫的图片时,很容易看到每个“神经元”的作用。不过,即使要对其进行基本的可视化,通常也非常困难。
在上面用于解决“最近点”问题的最终网络中,有 17 个神经元;在用于识别手写数字的网络中,有 2190 个神经元;而在用于识别猫和狗的网络中,有 60 650 个神经元。通常很难可视化出 60 650 维的空间。但由于这是一个用于处理图像的网络,其中的许多神经元层被组织成了数组,就像它查看的像素数组一样。
下面以一个典型的猫的图像为例。

我们可以用一组衍生图像来表示第一层神经元的状态,其中的许多可以被轻松地解读为“不带背景的猫”或“猫的轮廓”。

到第 10 层,就很难解读这些是什么了。

但是总的来说,我们可以说神经网络正在“挑选出某些特征”(也许尖尖的耳朵是其中之一),并使用这些特征来确定图像的内容。但是,这些特征能否用语言描述出来(比如“尖尖的耳朵”)呢?大多数情况下不能。
我们的大脑是否使用了类似的特征呢?我们多半并不知道。但值得注意的是,一些神经网络(像上面展示的这个)的前几层似乎会挑选出图像的某些方面(例如物体的边缘),而这些方面似乎与我们知道的大脑中负责视觉处理的第一层所挑选出的相似。
假设我们想得到神经网络中的“猫识别理论”,可以说:“看,这个特定的网络可以做到这一点。”这会立即让我们对“问题的难度”有一些了解(例如,可能需要多少个神经元或多少层)。但至少到目前为止,我们没办法对网络正在做什么“给出语言描述”。也许这是因为它确实是计算不可约的,除了明确跟踪每一步之外,没有可以找出它做了什么的一般方法。也有可能只是因为我们还没有“弄懂科学”,也没有发现能总结正在发生的事情的“自然法则”。
当使用 ChatGPT 生成语言时,我们会遇到类似的问题,而且目前尚不清楚是否有方法来“总结它所做的事情”。但是,语言的丰富性和细节(以及我们的使用经验)可能会让我们比图像处理取得更多进展。















 724
724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









