







fasttext?
fasttext,即快速的文本分类器。它可以根据给定的句子或词语加标签进行训练,从而对句子或词语进行分类。
fasttext原理
主要包含三大部分:模型架构,层次SoftMax,N-gram特征
模型构建
fasttext架构如图所示:
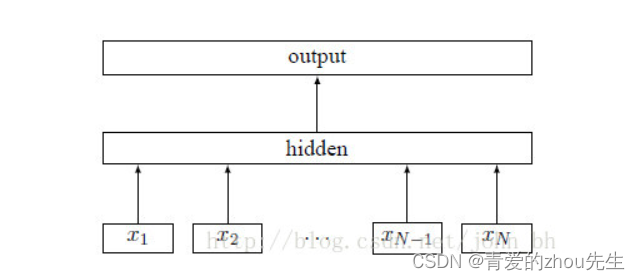
即输入一个词的序列(一段文本或一句话),输出这个序列属于不同类别的概率。
层次SoftMax
对比softmax:softmax又称归一化指数函数。它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解。
即分子通过指数函数,将实数输出映射到0到正无穷,分母将所有的分子结果相加,进行归一化。
层次softmax
对于有大量类别的数据集,fastText使用了一个分层分类器(而非扁平式架构)。不同的类别被整合进树形结构中(想象下二叉树而非 list)。在某些文本分类任务中类别很多,计算线性分类器的复杂度高。为了改善运行时间,fastText 模型使用了层次 Softmax 技巧。层次 Softmax 技巧建立在哈弗曼编码的基础上,对标签进行编码,能够极大地缩小模型预测目标的数量。
N-gram特征
fastText 可以用于文本分类和句子分类。不管是文本分类还是句子分类,我们常用的特征是词袋模型。但词袋模型不能考虑词之间的顺序,因此 fastText 还加入了 N-gram 特征。
即”我 爱 他“,”他 爱 我“ 在词袋模型的特征是一样的,但是在2-gram中,在词袋的基础上,句子文本的顺序特征加入了其中,使得”我 爱 他“,”他 爱 我“ 两句话区别开来。
实现
# 构建模型
model = fasttext.train_supervised(data_path,epoch=20,wordNgrams=2,minCount=1)
data_path:处理完成数据的存放路径
epoch: epochs 数量 default 5
wordNgrams: n-gram 设置 default 1
minCount: 为最小词频处理,小于该数值的词频将会直接被删除,默认为5
保存模型:model.save_model(save_path)
加载模型:model = fasttext.load_model(save_path)
预测模型:model.predict(input)
预测模型输入的是没有标签的文本列表,输出是标签列表和相应概率列表。
参考:https://blog.csdn.net/john_bh/article/details/79268850














 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









