









最近准备AI Challenger的时候要用到BLEU、NIST等评价指标对机器翻译的效果进行评价,BLEU比较好找,NIST就比较麻烦了,在这记录一下使用方法
关于BLEU的介绍可以参考对话响应生成的无监督评估指标的实证研究
NIST(National Institute of standards and Technology)方法是在BLEU方法上的一种改进。最主要的是引入了每个n-gram的信息量(information)的概念。BLEU算法只是单纯的将n-gram的数目加起来,而nist是在得到信息量累加起来再除以整个译文的n-gram片段数目。这样相当于对于一些出现少的重点的词权重就给的大了。
下载NIST
首先进入nist的官网
下载mteval-v13a-20091001.tar.gz
下载完成后直接运行会出现Can't locate XML/Twig.pm in @INC (you may need to install the XML::Twig module)的报错,需要先XML-Twig的库
配置XML-Twig
下载完成后解压XML-Twig-3.52.tar.gz,cd进入XML-Twig-3.52目录
perl Makefile.PL -y
make
sudo make install
Usage
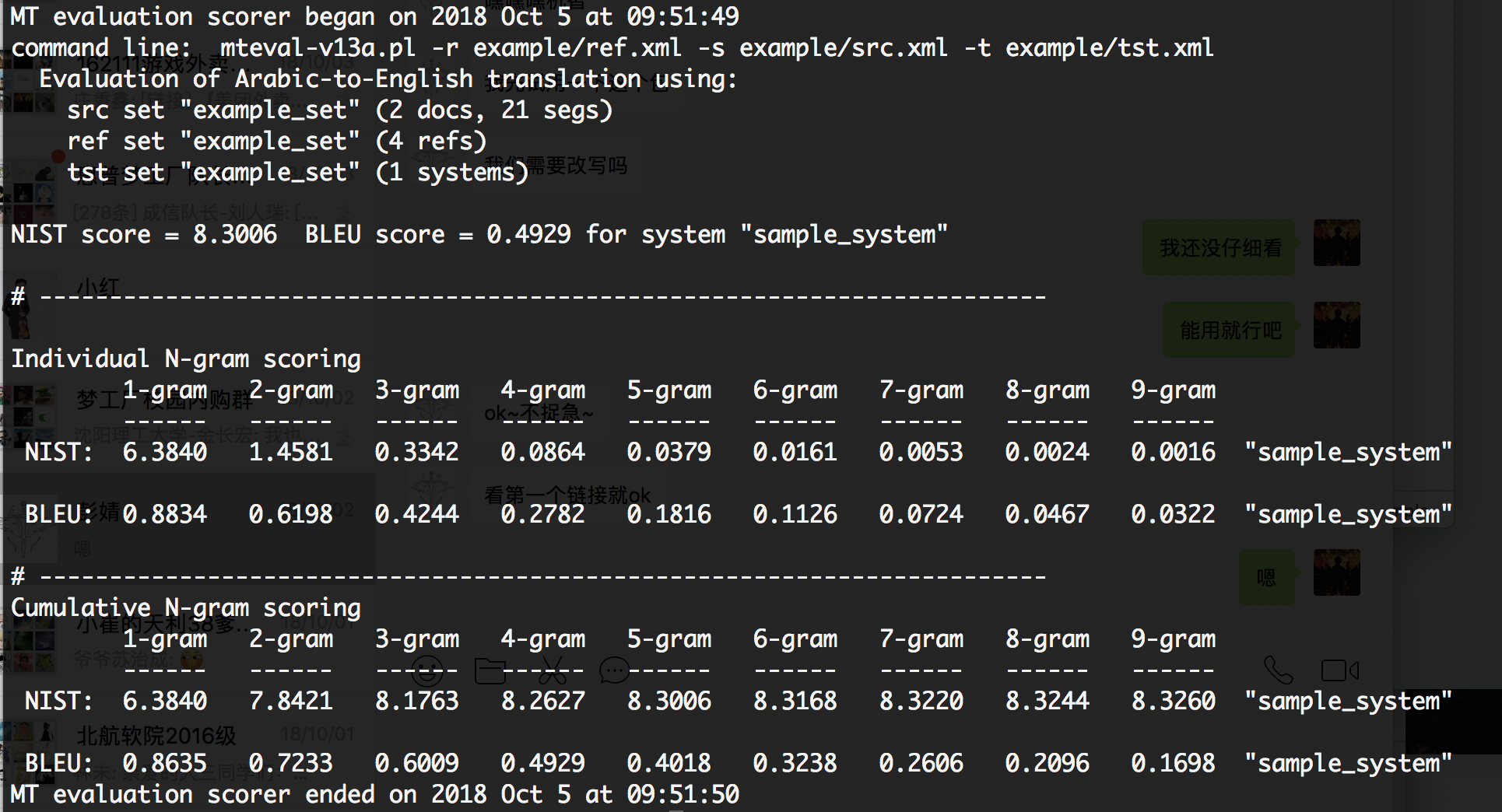
用nist提供的example进行测试
perl mteval-v13a.pl -r example/ref.xml -s example/src.xml -t example/tst.xml
其他用法
- BLEU-4(mteval-v13a,官方OpenMT12评估指标)
- 调用行:
perl mteval-v13a.pl -r REFERENCE_FILE -s SOURCE_FILE -t CANDIDATE_FILE -c -b - 选项-c:区分大小写的得分
- 选项-b:仅BLEU得分
- 调用行:
- IBM BLEU(bleu-1.04a)
- 调用行: perl bleu-1.04.pl -r REFERENCE_FILE -t CANDIDATE_FILE
- 默认情况下,评分是区分大小写的
- NIST(mteval-v13a)
- 调用行: perl mteval-v13a.pl -r REFERENCE_FILE -s SOURCE_FILE -t CANDIDATE_FILE -c -n
- 选项-c:区分大小写的得分
- 选项-n:仅NIST评分
- TER(tercom-0.7.25)
- 调用行: java -jar tercom.7.25.jar -r REFERENCE_FILE -h CANDIDATE_FILE -N -s
- 选项-N:启用归一化
- 选项-s:区分大小写的得分
- METEOR(气象0.7)
- 调用行: perl meteor.pl -s SYSTEM_ID -r REFERENCE_FILE -t CANDIDATE_FILE --modules “exact porter_stem wn_stem wn_synonymy”
- 选项–modules “exact porter_stem wn_stem wn_synonymy”:按照顺序使用所有四个METEOR匹配模块
转换xml脚本
#!/usr/bin/python
# coding=utf8
import sys
import re
import codecs
import os
from xml.etree.ElementTree import ElementTree as etree
from xml.etree.ElementTree import Element, SubElement, ElementTree
# 传入至少5个参数
# 生成译文的xml
# param 1: 要处理的是什么文件,只允许传入 "src","tst","ref"
# param 2:评测集名称
# param 3:源语言
# param 4:目标语言
# param 5..:要处理的文件
# 例如
# 生成原文
# python xml_transform.py src xml_data/test Chinese English bleu_data/src.txt
# 生成译文
# python xml_transform.py tst xml_data/test Chinese English bleu_data/tst.txt
# 生成ref
# python xml_transform.py ref xml_data/test Chinese English bleu_data/ref.txt
# perl mteval-v13a.pl -r ../xml_data/test_ref.xml -s ../xml_data/test_src.xml -t ../xml_data/test_tst.xml
'''
@ 生成ref的xml
@ param 1: 多份ref的list,list中每一个元素为一个ref的list
@ param 2:评测集名称
@ param 3:源语言
@ param 3:目标语言
'''
def genrefxml(reflists, setid, srclang, trglang):
mteval = Element('mteval')
for reflist in reflists:
sysid = reflist[0]
set = SubElement(mteval, "refset")
set.attrib = {"setid": setid, "srclang": srclang, "trglang": trglang, "refid": sysid}
doc = SubElement(set, "doc")
doc.attrib = {"docid": "doc1"}
i = 0
for sentence in reflist:
# 第一位存储具体是哪个引擎
if i != 0:
p = SubElement(doc, "p")
seg = SubElement(p, "seg")
seg.attrib = {"id": str(i)}
seg.text = sentence
i = i + 1
tree = ElementTree(mteval)
tree.write(setid + '_ref.xml', encoding='utf-8')
'''
@ 生成译文的xml
@ param 1: 多份译文的list,list中每一个元素为一个译文的list
@ param 2:评测集名称
@ param 3:源语言
@ param 3:目标语言
'''
def gentstxml(tstlists, setid, srclang, trglang):
mteval = Element('mteval')
for tstlist in tstlists:
sysid = tstlist[0]
set = SubElement(mteval, "tstset")
set.attrib = {"setid": setid, "srclang": srclang, "trglang": trglang, "sysid": sysid}
doc = SubElement(set, "doc")
doc.attrib = {"docid": "doc1"}
i = 0
for sentence in tstlist:
# 第一位存储具体是哪个引擎
if i != 0:
p = SubElement(doc, "p")
seg = SubElement(p, "seg")
seg.attrib = {"id": str(i)}
seg.text = sentence
i = i + 1
tree = ElementTree(mteval)
tree.write(setid + '_tst.xml', encoding='utf-8')
'''
@ 生成原文的xml
@ param 1: 原文内容的list
@ param 2:评测集名称
@ param 3:源语言
'''
def gensrcxml(senlist, setid, srclang):
mteval = Element('mteval')
set = SubElement(mteval, "srcset")
set.attrib = {"setid": setid, "srclang": srclang}
doc = SubElement(set, "doc")
doc.attrib = {"docid": "doc1"}
i = 1
for sentence in senlist:
p = SubElement(doc, "p")
seg = SubElement(p, "seg")
seg.attrib = {"id": str(i)}
seg.text = sentence
i += 1
tree = ElementTree(mteval)
tree.write(setid + '_src.xml', encoding='utf-8')
# 调用具体的生成xml
def genxmltree(filetype, setid, srclang, trglang, files):
if filetype not in ["src", "tst", "ref"]:
print("filetype is error")
return
# 处理原文
if filetype == "src":
srclist = []
for line in open(files[0]):
line = line.strip()
if line:
srclist.append(line)
gensrcxml(srclist, setid, srclang)
# 处理译文
if filetype == "tst":
tstslist = []
for tstfile in files:
tstlist = []
tstlist.append(str(tstfile).strip('.txt'))
for line in open(tstfile):
line = line.strip()
if line:
tstlist.append(line)
tstslist.append(tstlist)
gentstxml(tstslist, setid, srclang, trglang)
# 处理ref
if filetype == "ref":
reflists = []
for reffile in files:
reflist = []
reflist.append(str(reffile).strip('.txt'))
for line in open(reffile):
line = line.strip()
if line:
reflist.append(line)
reflists.append(reflist)
genrefxml(reflists, setid, srclang, trglang)
argv_len = len(sys.argv)
# print argv_len
if argv_len < 6:
print("param error! src/ref tmq English Chinese 1.txt ")
sys.exit()
filetype = sys.argv[1]
setid = sys.argv[2]
srclang = sys.argv[3]
trglang = sys.argv[4]
files = []
for i in range(5, len(sys.argv)):
files.append(sys.argv[i])
genxmltree(filetype, setid, srclang, trglang, files)















 2316
2316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









