







 机器翻译领域面临因测试集和度量评价不一致带来的挑战。BLEU分数受参数化和参考预处理的影响,导致分数差异高达1.8。文章建议采用WMT的BLEU方案,仅使用detokenized处理,避免用户提供的预处理。为支持这一建议,作者发布了一个名为SACREBLEU的Python脚本,简化了分数计算和比较。
机器翻译领域面临因测试集和度量评价不一致带来的挑战。BLEU分数受参数化和参考预处理的影响,导致分数差异高达1.8。文章建议采用WMT的BLEU方案,仅使用detokenized处理,避免用户提供的预处理。为支持这一建议,作者发布了一个名为SACREBLEU的Python脚本,简化了分数计算和比较。
https://arxiv.org/pdf/1804.08771v1.pdf
Github:https://github.com/awslabs/sockeye/tree/master/contrib/sacrebleu
由于在不同的环境下经常产生新的测试集,机器翻译领域面临着新的挑战,而且在如何进行度量评价方面缺乏共识。常用的 BLEU score 会随着 parameterization、尤其是 reference processing schemes 的变化而变化,而这些细节通常在论文中是没有的,也难以确定。作者量化了这种变化,发现常用配置之间的分数差异高达1.8。鉴于 parsing community 的成功,作者建议机器翻译研究人员采用 annual Conference on Machine (WMT) 使用的 BLEU 方案,该方案不允许 user-supplied preprocessing of the reference 用户提供的参考的预处理,并提供了一个新的工具来促进这一点。
1 Introduction
科学是形成假设、做出预测并衡量其结果的过程。在机器翻译研究中,模型的研发是研究的重点,模型做出预测后,通常是由 BLEU 进行评价,BLEU 相对的语言独立性、易于计算以及与人类判断的合理相关性使其成为机器翻译研究的主导度量标准,为研究人员提供了一种快速、廉价的方式来评估他们的模型的性能,与手动评估一起引导了质量评估领域15年。但这并不是说 BLEU 没有问题,它的缺点很多,关于它们的文章也很多(cf. CallisonBurch et al., 2006),然而本文并没有涉及到这些缺点,主要的目的是引起人们对报告 BLEU 分数的一些问题进行关注:
• BLEU 不是一个单一的度量标准,而是需要大量的参数;
• 预处理方法对分数影响很大,不同预处理的 BLEU 分数是不可比较的;
• 论文使用的隐藏参数和方案各不相同,以前的工作没有提及、或者提到但没有研究细节问题。
这些问题阻碍了论文 BLEU 比较和成果复现,在量化了这些问题后,发现分数的方差大于许多论文报告的提升,而且用户提供的参考分词常为不兼容性的来源。作为一种解决方案,建议只使用 detokenized 处理,就像 WMT 所做的那样。为了支持这一点,作者发布了一个 Python 脚本 SACREBLEU,计算度量并返回记录参数的字符串,还可以自动下载和管理公共测试集。
2 Problem Description
2.1 Problem: BLEU is underspecified
BLEU 的参数包括:
• 参考的个数;
• 多参考时长度惩罚的计算;
• 最大 n-gram 的长度;
• 平滑 0-count 时的 n-gram。
这些在实践中往往不是问题,因为:通常只有一个参考;因此长度惩罚的计算是没有意义的;最大 n-gram 的长度总是设置为4;由于 BLEU 是语料库级别的,所以很少出现 0-count。
WMT 2017 英语-芬兰语的参考翻译有两个,评价 online-B 系统时使用一个参考的 BLEU 分数为22.04,使用两个参考的分数为25.25。
2.2 Problem: Different reference preprocessings cannot be compared
预处理包括输入文本的修改,如 normalization(collapsing punctuation 分解标点,删除特殊字符)、tokenization(splitting off punctuation 标点分割)、compound-splitting 复合分解、去除大小写等,目标是向 MT 系统输入有意义的空白分隔的 tokens。其中 tokenization 是最为重要的,这是因为 BLEU 是准确率度量,更改参考的处理会更改 n-gram 的集合,类似地,在 parsing community 中使用F1值作为跨语言解析难度的粗略估计也是不可靠的。注意到虽然 BLEU 分数经常被报告为 tokenized 或 detokenized,但在计算 BLEU 时,系统输出和参考都是 tokenized,区别是参考的预处理是用户提供的还是 metric-internal 内部度量的(分别由实现度量的代码决定)。由于只能在参考处理相同的情况下比较 BLEU,用户提供的预处理很容易出错,而且不适合在不同论文之间进行比较。
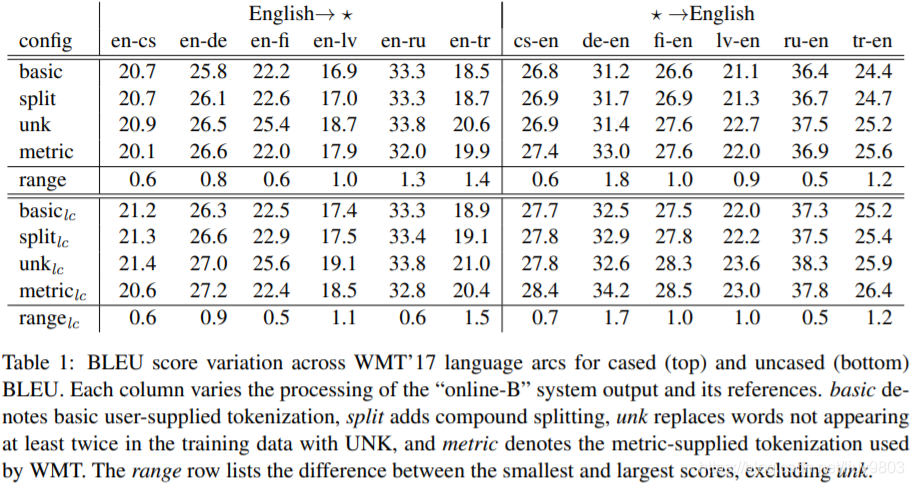
表1为使用不同参考分词计算的 BLEU,作者采用 oneline-B 的输出,并对其和参考进行如下处理:
• basic 用户提供的预处理,使用了 MOSES tokenizer (Koehn et al., 2007) ;
• split 拆分复合词,例如,rich-text → rich - text (Luong et al., 2015a);
• unk 所有未在 WMT 训练数据中至少出现两次的单词(使用 basic tokenization)都被映射为 UNK,如果不小心将这种常见的用户提供的预处理应用于参考数据时,就很容易出错;
• metric 只提供官方 WMT 评分脚本的内部度量 tokenization,mteval-v13a.pl。
每一列的变化显示了这些不同方案的效果,其中一个的arc高达1.8,平均在1.0左右。最大的问题是对大小写的处理,这是众所周知的,但是许多论文并不清楚它们是使用了大小写敏感的 BLEU 还是使用了大小写不敏感的 BLEU。
允许用户对参考预处理还有其他问题,例如,许多系统(特别是在进行 sub-word splitting 之前被提出)在处理未知词时限制了词汇量,无法确定他们没有将相同的未知词屏蔽应用于参考数据,从而使词更有可能匹配?这类错误很容易犯。
2.3 Problem: Details are hard to come by
一般难以从用户提供的参考处理中获得详细信息,无法对已发表的数值进行直接比较,但如果论文中提供了足够的详细信息,至少可以重现出可比较的数值。
不幸的是,这并不是一种趋势,即使对于一丝不苟的研究人员来说,包含这种程度的技术细节也常常很麻烦。无论如何,它为读者创造了不确定性和工作,必须阅读实验部分,浏览脚注,并寻找其他有时分散在论文中的线索,搞清楚另一个团队做了什么并不容易。表1中的变化只是一些可能的配置,因为一个组可以应用的预处理没有限制。在表2中,作者尝试从一些有影响力的论文中确定哪一些配置经常被使用,系统不仅因为不同的方案而不具有可比性,而且在许多情况下,难以做出简单的测定。

2.4 Summary
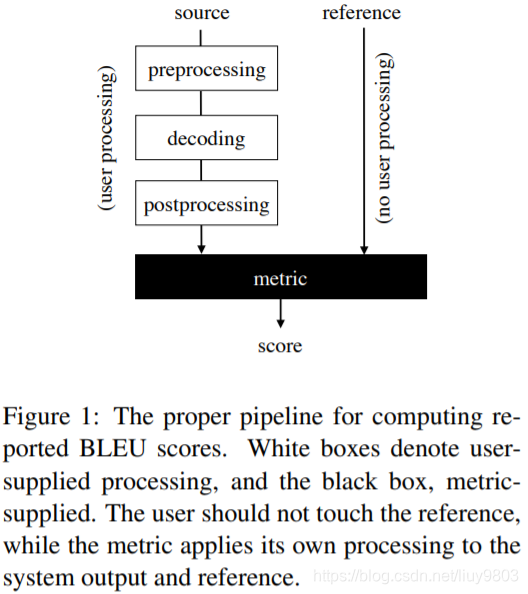
为了使分数具有可比性,参考的分词必须相同,如图1所示,用户提供的参考预处理妨碍了这一点,会出现不必要的复杂比较,而且缺乏预处理的管道细节将进一步加重这个问题。
3 A way forward
3.1 The example of PARSEVAL
PARSEVAL 计算解析器精度的度量 (Black et al., 1991) 方式是获取表单 (N, i, j) 的标记跨度,表示一个由词 i 到词 j 组成的 nonterminal N spanning 非终结 N 跨度,它们是从解析器的输出中提取的,用于与从正确的解析树中提取的标准集计算准确率和召回率,然后将 P 和 R 结合起来,计算通常在分析论文中报告和比较的 F1 度量。
计算解析器 F1 的一些极端例子有:是否要计算顶部(根)节点?-None-?标点?标签是否是等价的?社区通过采用一个标准的代码库 evalb 来解决这些问题,evalb 中的一个参数文件可以解决每个问题,这促进了30年来解析社区中不同论文之间的 treebanks 的比较。
3.2 Existing scripts
MOSES 有许多评分脚本,但不幸的是,每个都有问题,Moses 的 multi-bleu.perl 不能使用,因为它需要用户提供的预处理。另一个评估框架 MultEval (Clark et al., 2011) 也是如此,明确地提倡用户提供分词。Moses 的 mteval-v13a.pl 是一个不错的选择,利用了内部度量的预处理,并被 WMT 的评估所采用,但是这个脚本需要将数据包装成 XML。Nematus (Sennrich et al., 2017) 包含了一个没有 XML 要求的脚本(multi-bleu-detok.perl),但是仍然需要用户手动处理参考数据。作者认为更好的方法是让用户彻底远离参考数据。
3.3 SACREBLEU
SACREBLEU 是一个 Python 脚本,它:
• 期望 detokenized 输出,应用它自己的内部度量预处理,并产生与 WMT 相同的值;
• 产生一个简短的版本字符串,记录所使用的设置;
• 自动下载及管理 WMT (2008-2018) 和 IWSLT 2017 (Cettolo et al., 2017) 的测试集,并将它们处理为纯文本。
SACREBLEU 可以通过 Python 包管理系统安装:pip3 install sacrebleu,它是 Apache 2.0许可下的开源软件。
4 Summary
机器翻译得益于从学术、行业等渠道定期引入的许多不同语言领域的测试集,这使共享和比较一组新数据的分数变得容易,令人遗憾的是,现在还不能轻易做到这一点。人们可能会认为这都是一些无关紧要的细节,但正如作者所展示的那样,这些细节的差异实际上是非常重要的,导致巨大的分数差异往往比新方法报告的提升要大得多。解决方法是,团队应只报告使用内部度量分词和预处理计算参考的 BLEU,每次处理参考数据的方法都一样,这样就可以直接比较各个论文的分数。作者推荐 WMT 使用的版本,并提供了一个更加易于使用的新工具。

















 1347
1347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









