









 本文对对话响应生成的无监督评估指标进行实证研究,指出现存指标缺点,介绍基于单词和嵌入的评估方法,对比检索与生成模型。分析表明部分指标与人类判断相关性弱,还探讨了约束任务、结合多响应及探索合适指标等方向。
本文对对话响应生成的无监督评估指标进行实证研究,指出现存指标缺点,介绍基于单词和嵌入的评估方法,对比检索与生成模型。分析表明部分指标与人类判断相关性弱,还探讨了约束任务、结合多响应及探索合适指标等方向。
对话响应生成的无监督评估指标的实证研究
简介
这个文章的工作:指出现存的metric的缺点,提出一个更好的metric的建议。
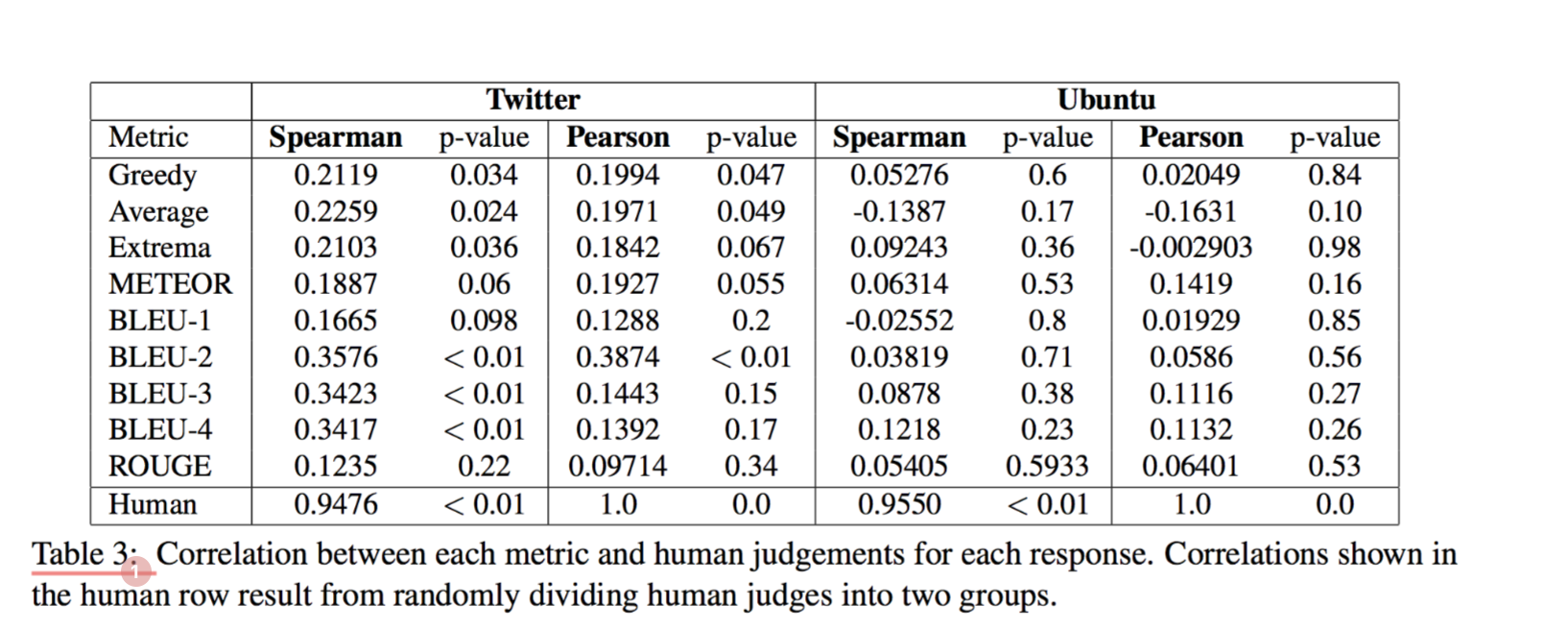
机器学习的评价指标与Twitter领域中人的判断呈现弱相关,Ubuntu领域根本不相关
我们通常使用人工生成的监督信号对生成响应的质量进行评估,使用nn和端到端训练,避免了大规模收集监督标签的需要,但自动评估模型质量仍然是个问题, 自动评估指标有助于加速无监督响应生成系统的部署,这些指标假设有效响应与正确的响应有单词重叠,但两个合理响应可以不共享任何单词并且不具有相同的语义含义
进一步强调了这些指标的缺点:
- 对调查结果进行统计分析
- 对数据中的例子进行定性分析
- 探索指标的敏感性
相关工作
只考虑可用于评估针对实际响应的建议响应的元数据,不考虑基于检索的指标,也没有考虑监督评估方法的评估方法
最近几项关于无监督对话系统的著作采用BLEU评分进行评估。 将无监督学习问题表述为将语境翻译成候选答案。使用统计机器翻译(SMT)模型使用Twitter数据生成对各种上下文的响应,并显示它根据BLEU和人类评估优于信息检索baseline。循环语言模型扩展了这一想法,以上下文敏感的方式生成响应
BLEU的修改版本,deltaBLEU,考虑到几个人类评估的实际反应,显示与使用Twitter对话的人类判断具有弱到中等的相关性,但这种人类注释在实际中是不可行的。
根据会话背景产生对话响应实际上是一个更难的问题
自动评估语言生成模型的困难在于正确答案很多。
Evaluation Metrics
目标:自动评估建议的响应对对话的适当程度;两种方法:基于单词的相似性度量和基于单词嵌入的相似性度量
word overlap-based metrics
首先考虑评估建议的响应和实际响应之间的字重叠量的度量
BLEU
BLEU通常在语料库级别计算,最初设计用于多个引用句子。
BLEU对不改变响应语义的因素敏感
METEOR
为解决BLEU的几个弱点而引入的。 它在候选和目标响应之间创建了一个明确的对齐,METEOR得分是提议响应和实际响应之间的精确度和召回的调和平均值。
BLEU和METEOR对于长度是比较敏感的
GOUGE
分析了基础事实和提出响应中n-gram的共现现象
Embedding-based Metrics
Greedy Matching
贪婪的方法倾向于使用在语义上类似于基本事实响应中的关键词的回答,而不是sentence level的。
Embedding Average
嵌入平均度量使用加性成分计算句子级嵌入,这是一种通过平均其组成单词的向量表示来计算短语含义的方法
Vector Extrema
矢量极值。 计算句子级嵌入的另一种方法是使用向量解析。 对于单词向量的每个维度,在句子中的所有单词向量中取最极值,并在句子级嵌入中使用该值,更可能忽略常用词
Dialogue Response Generation Models
Retrieval Models
TF-IDF
词频-逆文件频率,旨在捕捉给定单词对某些文档的重要性,还分为C-TFIDF(针对context之间的cosine距离)和R-TFIDF(针对input context和response之间的cosine距离)
Dual Encoder
双编码器模型,DE模型由两个RNN组成,它们分别计算输入条件和响应的矢量表示。 然后,模型通过采用加权点积来计算给定响应是给定上下文的基础事实响应的概率。使用负采样训练模型以最小化所有(上下文,响应)对的交叉熵误差。
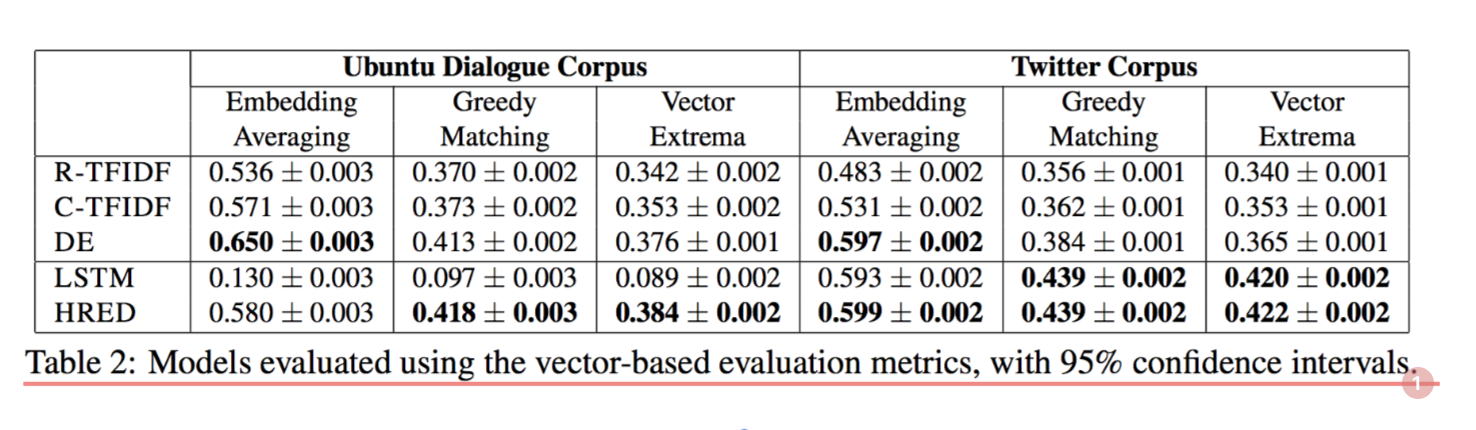
对于检索模型,我们观察到DE模型明显优于两个数据集上所有度量的TFIDF baseline。 此外,HRED模型明显优于两个领域中的基本LSTM生成模型,并且看起来具有与DE模型相似的强度。然而,基于嵌入的指标仅与Twitter语料库中的人类判断相关,而在Ubuntu对话语料库中根本不相关。 这表明,不应使用与新任务上的人类判断特定相关的指标来评估该任务。
Generative Models
如果模型能够生成训练集中没有的全新句子,我们将模型称为生成模型。
LSTM语言模型
HERD模型(Hierarchical Recurrent Encoder-Decoder)
分层递归编码-解码, HRED模型使用了一系列编码器; 上下文中的每个话语都通过“话语级”编码器,这些编码器的输出通过另一个“上下文级”编码器传递,这使得能够处理长期依赖性。
Human Correlation Analysis
数据集描述
给定上下文和一个回复,给这个回复的合适性打分。问题们对应有20种不同的上下文,对应5个回复:1. 从测试集中随机挑的;2-4:上面说的算法产生的;5:人的回复。
有25个人来对此进行1-5的打分,并且对这些打分做了一致性检验(cohen kappa score),去掉了2个kappa系数很低的。
Kappa 系数:用来衡量两种标注结果的吻合程度,标注指的是把N个样本标注为C个互斥类别
分析结果

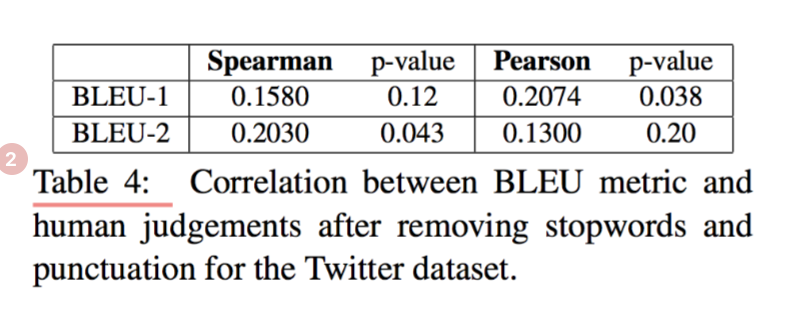
所有基于嵌入的度量和BLEU-1对提议的响应的评分与人类的显着不同,这表明基于嵌入的度量将受益于单词显着性的加权
对于Ubuntu对话语料库没有与人相关度的度量标准,这是因为正确的Ubuntu响应包含特定的技术词汇,这些词汇不太可能由我们的模型生成。此外,Ubuntu对话语料库中的响应可能具有比Twitter更大的内在可变性(或熵),这使得评估问题变得更加困难。
讨论
Constrained tasks (约束的任务)
一般是把对话系统分为dialogue planner和natural language generation模块。因为把dialogue acts mapping到一个自然语言句子的过程比较接近MT, 所以BLEU metrics在这个方面的任务中可能是使用的。但是仍需要验证。
Incorporating multiple responses (结合多个响应)
就是在评估的时候不只有一个ground truth response,而是用retrieval的方法选出多个可能的response。效果以及对word-overlap metrics的影响仍需要检验。
Searching for suitable metrics (探索合适的指标)
本文只是对现有的metrics进行了批判,但是没有提出新的可行的metrics,但是他们认为embedding-based是一个可行的方向,如果它能够扩展为可把更复杂的模型(for medeling sentence-level compositionality)考虑进去的话。考虑到上下文或者其他utterance的metrics也可能可行。一个模型需要通过human survey的data来学到human-like的打分。

















 1124
1124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









