







博主最近在做机器翻译相关的工作,需要用到BLEU作为翻译结果的评价指标。
这里对概念及计算方法不多做介绍,只记录一些个人对不同的库计算bleu值过程的粗浅的理解。
NLTK
首先是nltk.translate.bleu_score,其中包含了sentence_bleu和corpus_bleu,其中sentence_bleu也是通过调用corpus_bleu来实现的。

其中reference是参考句,即答案,形如[ref1,ref2,ref3,...](可能存在多个参考句),其中ref1形如['This','is','a','test'];hypothesis是模型翻译句子,形如['This','is','a','test']。
smoothing_function是平滑函数,由于bleu是几何平均,如果某些gram计算匹配数量为0,则bleu值应该为0,通过平滑函数,可以让最后的结果不是0。默认smoothing_function为None,也就是不进行平滑处理,对于参考句"It is a good idea"和翻译句子“It is a idea",由于4-gram匹配数为0,如果考虑4-gram,那么BLEU值为0。

其中reference是参考句,即答案,形如[ref1,ref2,ref3...],ref1和ref2是不同句子的参考句列表,其中ref1形如[ref11,ref12,ref13,...],ref11形如['This','is','a','test'],ref11和ref12是同一个句子的不同参考句;hypothesis是模型翻译句子,形如[hyp1,hyp2,...]。
corpus_bleu的计算过程是,对于每组数据,计算出相应的Pi和Ni,其中Pi是i-gram匹配的数量,Ni是翻译句子i-gram的总数,将所有数据的i-gram的Pi和Ni分别累加,得到最终的Pi和Ni;根据每组数据的翻译句子的长度,找到最接近的参考句子的长度,同样分别累加,作为最终的翻译句子和参考句子的长度,计算BP;weights是函数参数。然后通过smoothing_function对Pi为0的进行平滑处理(但是默认是不进行平滑处理的),根据Pi和Ni计算得到pi(并且由于之后需要经过math.log(),如果Pi为0,这里会给pi赋值系统的最小浮点数)。最后再根据weights、pi和BP计算BLEU值,由于pi的计算原因,当某个Pi为0时,最后的bleu值可能是一个极小的浮点数,而不是0。
multi-bleu.perl
multi-bleu.perl是一个perl脚本,因为不懂perl,只是大致看了一下内容。
感觉脚本实现的过程与nltk中的corpus_bleu类似,不过脚本是固定的1-gram到4-gram的几何平均,wn是1/4,并且没有使用平滑。
并且,对于Pi为0的情况,multi-bleu通过实现my_log计算,如果Pi为0则返回-99999999类似的数作为pi,从而使得最后的结果接近0。(下同)
据说很多机器翻译项目都是用这个脚本的结果作为评估依据,例如Facebook的XLM,直接调用该脚本进行评估。
脚本的命令行输入为,perl multi-bleu.perl ref.txt [ref2.txt ...]< pre.txt
其中可以有多个ref参考文件。
不过下面是脚本中的提示,建议使用mteval-v14.pl而不是multi-bleu.perl,因为tokenizer不同,multi-bleu.perl的分数可能不同,而mteval-v14.pl中实现了标准化的tokenizer。
"It is not advisable to publish scores from multi-bleu.perl. The scores depend on your tokenizer, which is unlikely to be reproducible from your paper or consistent across research groups. Instead you should detokenize then use mteval-v14.pl, which has a standard tokenization. Scores from multi-bleu.perl can still be used for internal purposes when you have a consistent tokenizer.\n";
sacrebleu
如果说multi-bleu.perl还能勉强看懂,mteval-v13.pl是真的看的难受,因此就跳过了,主要看了一下据说可以得到和mteval-v13.pl一样结果的python实现的sacrebleu。
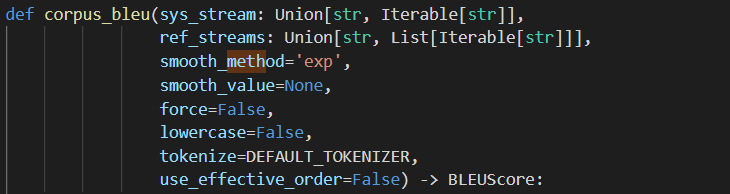
下面是sacrebleu中corpus_bleu的一个例子。
import sacrebleu
refs = [['The dog bit the man.', 'It was not unexpected.', 'The man bit him first.'],
['The dog had bit the man.', 'No one was surprised.', 'The man had bitten the dog.']]
sys = ['The dog bit the man.', "It wasn't surprising.", 'The man had just bitten him.']
bleu = sacrebleu.corpus_bleu(sys, refs)
print(bleu.score)顺着corpus_bleu,我找到了corpus_score,真正的计算过程是在这里进行的。
经过查看,我发现corpus_score和nltk的corpus_bleu的计算其实差不多,不同的是对匹配的n-gram数为0时的处理。
对于sacrebleu中corpus_bleu,smooth_method默认为'exp',和mteval-v13.pl中的平滑方法是一样的,如果将smooth_method设置为"none",则又和multi-bleu.perl一样。而nltk中,与'exp'对应的平滑函数是Smoothing_Function().method3。
总结
corpus_bleu的计算方法,和我最先以为的,计算出每组数据的bleu值,再根据数据条数取平均是不一样的。
这二者有何优劣我目前还没想清楚,如果读者朋友有所了解,也希望能够不吝赐教。

















 5384
5384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









