






WonderJourney(Stanford University, Google Research)
论文:https://arxiv.org/pdf/2312.03884
代码:https://kovenyu.com/WonderJourney/
WonderWorld(Stanford University, MIT)
论文:https://arxiv.org/pdf/2406.09394
代码:https://kovenyu.com/WonderWorld/
Wonderland(Stanford University, MIT)
论文:https://arxiv.org/abs/2412.12091
代码:https://snap-research.github.io/wonderland/
概要
随着LLM、VLM、Diffusion模型、深度估计等技术的进步,3D场景视频的生成可能也是下一个热门方向,并在虚拟现实(VR)、增强现实(AR)和娱乐领域具有广泛的应用前景。本文主要介绍Stanford团队的Wonder系列3D场景漫游视频生成技术。
技术方案
WonderJourney
该方法无需任何训练,给定文本或单图均可,通过text2image或者caption得到图像-文本对,将文本输入LLM生成Next scene description,同时用MIDAS v3.1预测单目深度,根据深度渲染出新视角,输入Next scene description进行图像和深度补全,并将补全结果输入VLM判断场景生成是否有合理.
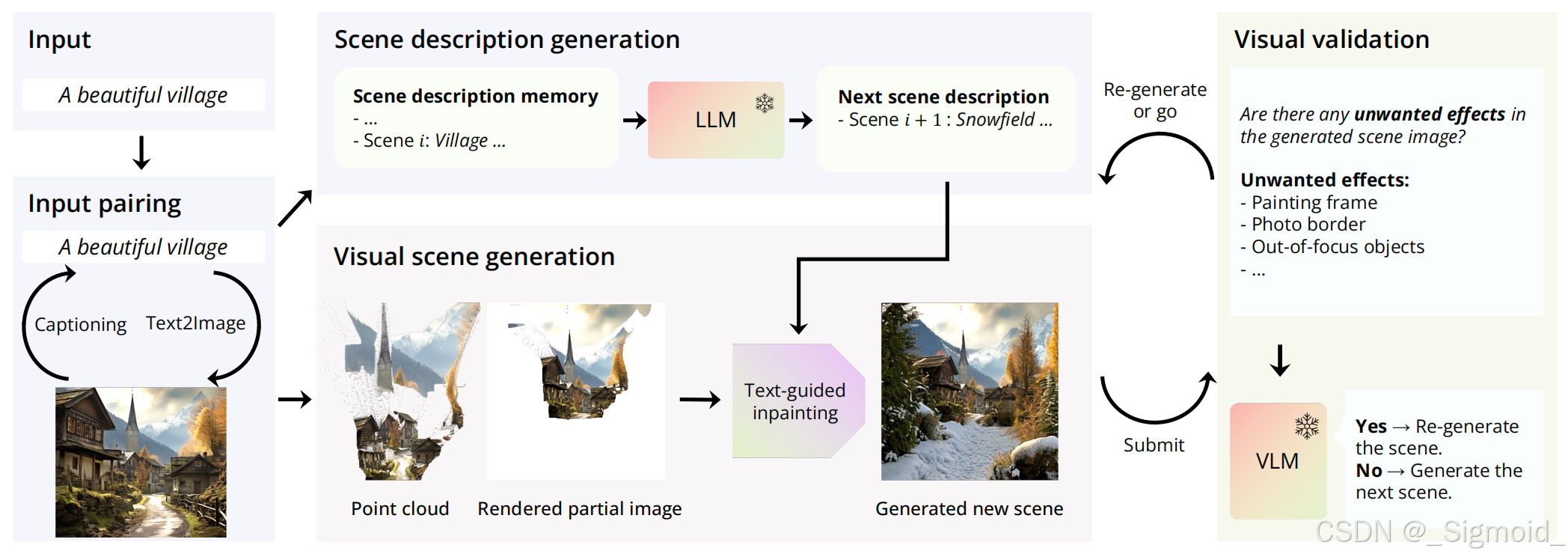
新视图生成流程如下,需要加入Depth Refinement,通过SAM对像素分组
s
e
g
j
j
=
1
N
{seg_j}^N_{j=1}
segjj=1N,每个片段中对边缘执行中值滤波。
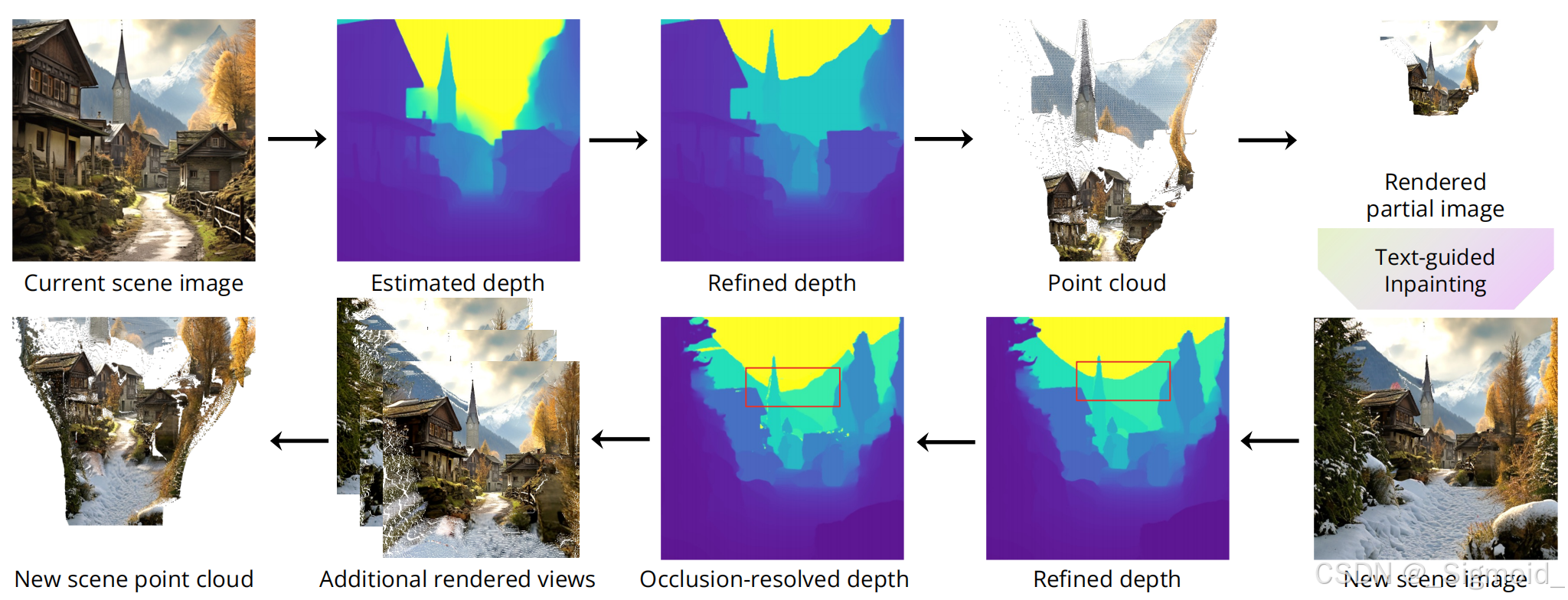

其他技术点:Stable Diffusion inpainting model,被遮挡深度后移,VLM判断“Is there any Xt in this image”
WonderWorld
本文方法第一个实现用户以低延迟交互式创建多样化、连通的场景,并引入了FLAGS表示法,用于快速场景生成,以及从单个视角生成场景。进一步引入深度引导扩散模型来减轻几何畸变。
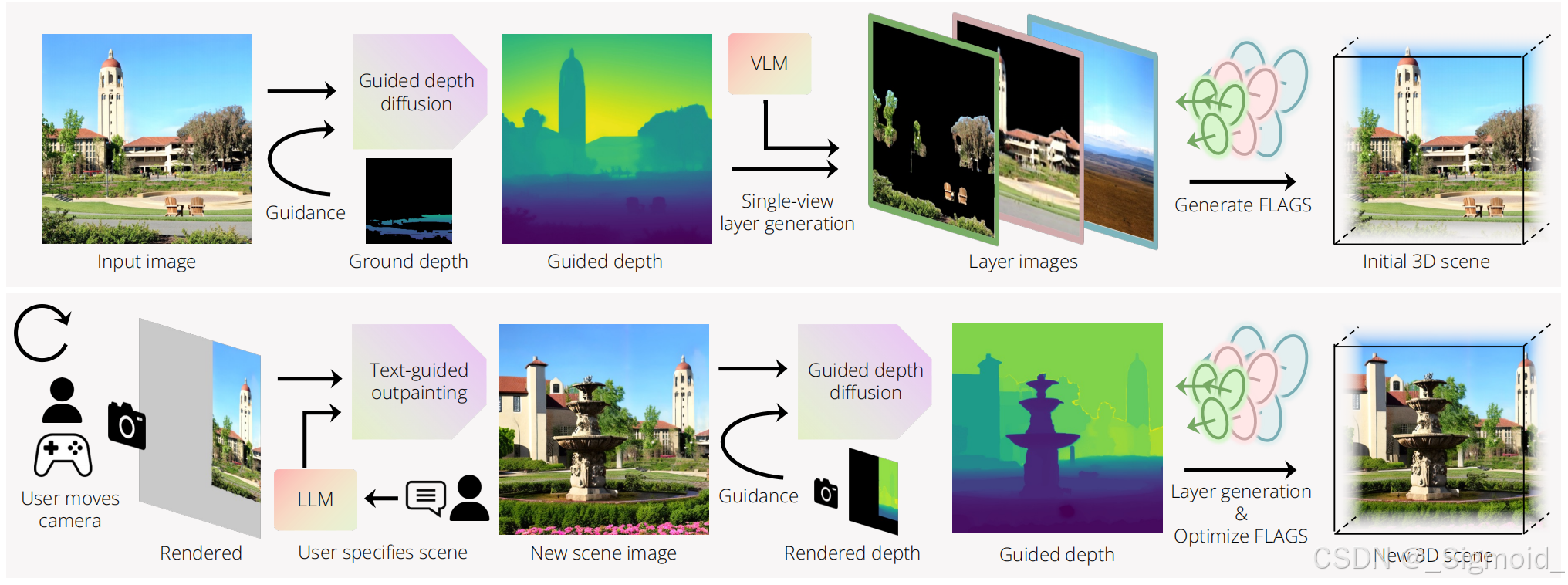
**Fast LAyered Gaussian Surfels (FLAGS)**将每个场景分为景、背景和天空,每一层由面元集合表示,每个面元是一个2DGS盘(位置p、方向四元数q、xy轴长s、不透明度o和颜色c参数构成)。方差计算和渲染原理同3DGS,只移除了z轴和球谐颜色。Geometry-based initialization根据深度执行pixel-aligned生成,每个像素点对应一个gaussian盘,c初始化为像素颜色,gs盘位置p由位姿、内参和深度计算得到,GS球的旋转矩阵
Q
=
[
Q
x
,
Q
y
,
Q
z
]
Q = [Q_x, Q_y, Q_z]
Q=[Qx,Qy,Qz],可以从估计像素法向量
n
c
a
m
n_cam
ncam,其中
u
=
[
0
,
1
,
0
]
T
u=[0,1,0]^T
u=[0,1,0]T表示单位向上向量,
n
=
R
−
1
n
c
a
m
n=R^{-1}n_{cam}
n=R−1ncam表示世界坐标系下像素法向量,
n
c
a
m
n_{cam}
ncam表示相机坐标系下法向量。
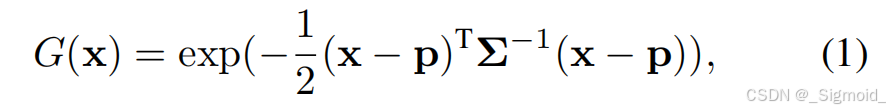
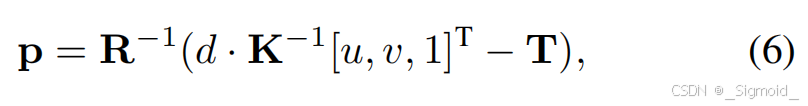
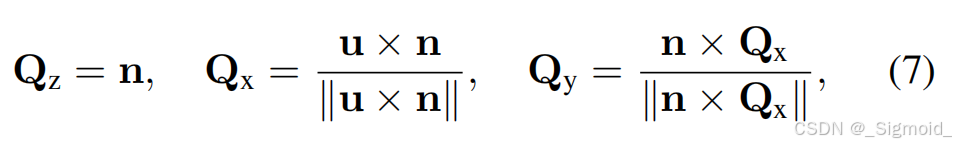
尺度根据Nyquist采样理论计算如下,不透明度opacity=0.1。优化过程则从后向前微调,先训练天空,再训练背景,最后训练前景,执行100次Adam优化,且无需密集化操作。
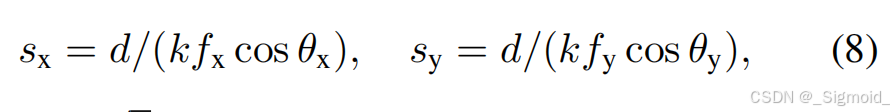
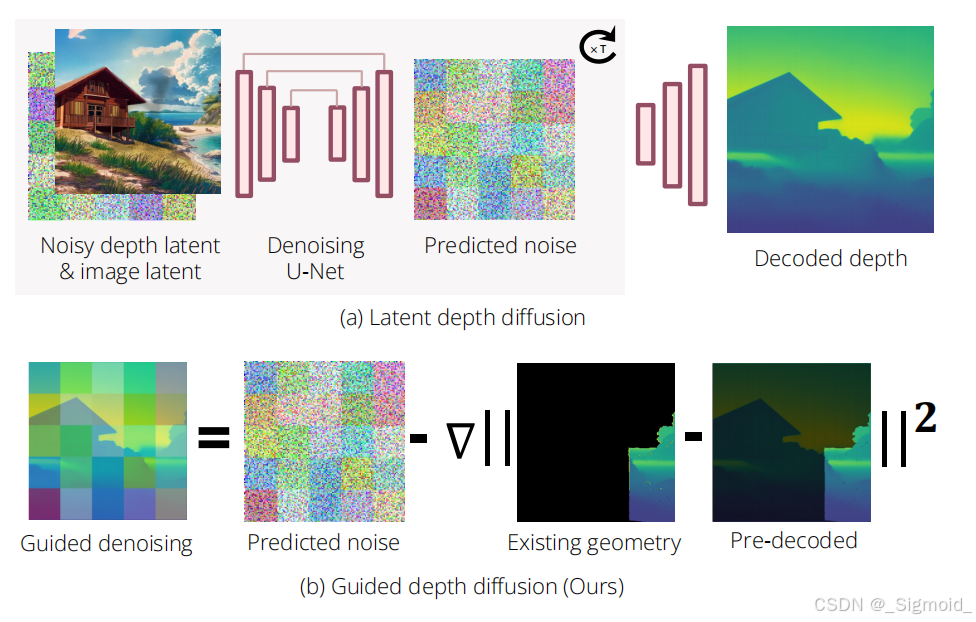
Guided Depth Diffusion采用training-free的latent depth diffusion model,输入图像+引导深度+mask经过多次去噪外插出新视角的深度。
?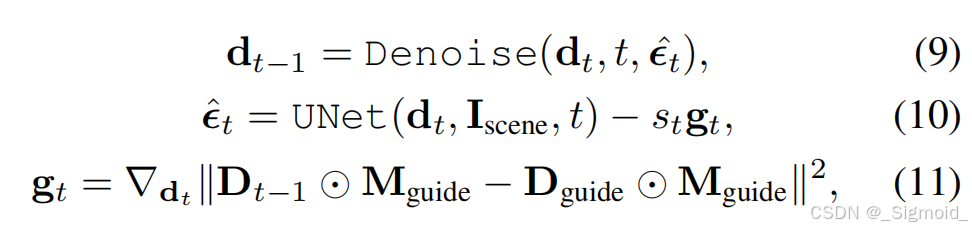
执行细节:Stable Diffusion Inpaint model补全、OneFormer分割天空和前景、Marigold Normal估计像素法向量、Marigold Depth作为深度扩散模型、
Wonderland
为了解决多视角数据的匮乏和漫长3D重建优化过程,本文提出了一个相机引导的可控视频生成模型,设计双分支结构将单图根据相机参数生成一段视频,并提出LaLRM的前馈网络直接从视频隐特征预测3DGS参数。
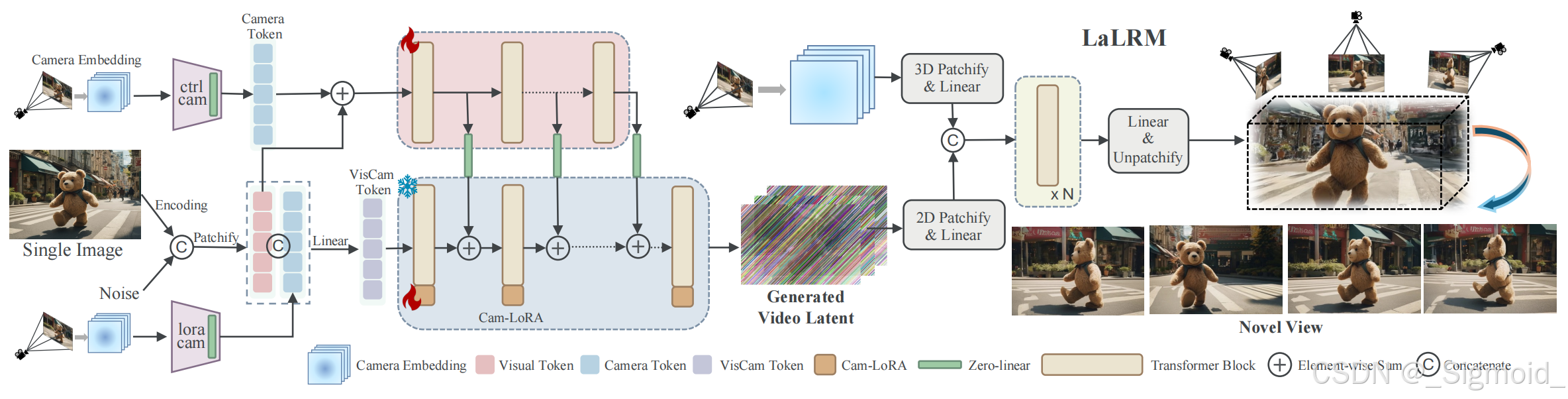
Camera-Guided Video Latent Generation首先采用3D-VAE对视频进行时间和空间压缩,得到视频隐特征
z
∈
R
t
×
h
×
w
×
c
z ∈ R^{t×h×w×c}
z∈Rt×h×w×c。利用Transformer扩散模型进行视频生成。为了加入相机轨迹控制条件,采用更精细的像素级位置表示,即Plucker embedding的相机表示
p
u
,
v
=
(
t
×
d
u
,
v
,
d
u
,
v
)
∈
R
6
p_{u,v} = (t × d_{u,v}, d_{u,v}) ∈ R^6
pu,v=(t×du,v,du,v)∈R6,其中
d
u
,
v
=
n
o
r
m
(
R
K
−
1
[
u
,
v
,
1
]
T
+
t
)
d_{u,v}=norm(RK^{-1}[u,v,1]^T+t)
du,v=norm(RK−1[u,v,1]T+t)。
Dual Branch Camera Guidance为了保证加入相机条件控制后预训练模型效果不变差,提出了双分支的相机引导模型,类似于ControlNet和LoRA,不改变原始权重即可达到优秀的扩展性。如图所示,相机参数经过两个轻量化encoder得到
o
c
t
r
l
o_{ctrl}
octrl和
o
l
o
r
a
o_{lora}
olora(均使用3DConv压缩时空),前者输入ControlNet分支,在每个block之后通过zero convolution注入到主分支,后者通过concat注入到主分支。通过这种方式,冻结主分支,只微调ControlNet分之和LoRA参数,即可实现精确的相机引导控制视频生成效果。
Latent Large Reconstruction Model(LaLRM) 使用前馈网络直接从视频的隐特征中预测12维的3DGS参数,输入video latent和相机Plucker embedding,前者2D分块化处理,后者采用3DConv进行时空压缩到与video latent一致的维度上,再进行两者的concat,经过Transformer和3D DeConv模块解码出12维的3DGS参数。
Progressive Training Strategy为了保证LaLRM模型的3D一致性性和泛化性,需要在大量in-the-wild数据集上训练。因此,本文采用渐进式训练策略。第一阶段,在benchmark数据集上用低分辨率视频进行训练,采用步长s采样T帧可见帧集合V,剩余不可见帧维U,V和U用于重建3DGS监督LaLRM前馈网络预测的3DGS系数。第二阶段,合并benchmark数据与相机引导模型生成的域外数据,在高分辨率上训练,以提升LaLRM的泛化性和高保真性。
实验细节视频生成模型采用CogVideoX-5B-I2V,3D VAE以spatial ratios r t = 4 r_t = 4 rt=4 and r s = 8 r_s = 8 rs=8压缩时空得到13×60×90隐特征,ControlNet用到视频模型前21个Transformer模块作为初始化,LoRA最小维度256, LaLRM采用24个Transformer构建,先在49 × 240 × 360分辨率上训练,再在49 × 480 × 720分辨率上训练,监督时48帧全用,随机采样24帧作为可见帧,剩下24作为不可见帧。
实验结果
WonderJourney结果 可以生成各种风格的3D场景视频,且优于InfiniteNature-Zero和SceneScape,但在实测中,生成的视频前后景边缘artifact较多


WonderWorld结果 基于WonderJourney稍微提升了边缘处理效果,引入3DGS后渲染质量有一定提升,但深度估计的几何一致性仍然较差(如墙面与地面不垂直)

Wonderland结果. 相机控制的视频生成模型效果优于MotionCtrl、VD3D和ViewCrafter模型,重建效果优于ViewCrafter和ZeroNVS,视觉效果上也比WonderJourney好,后者有较多的边缘artifact。

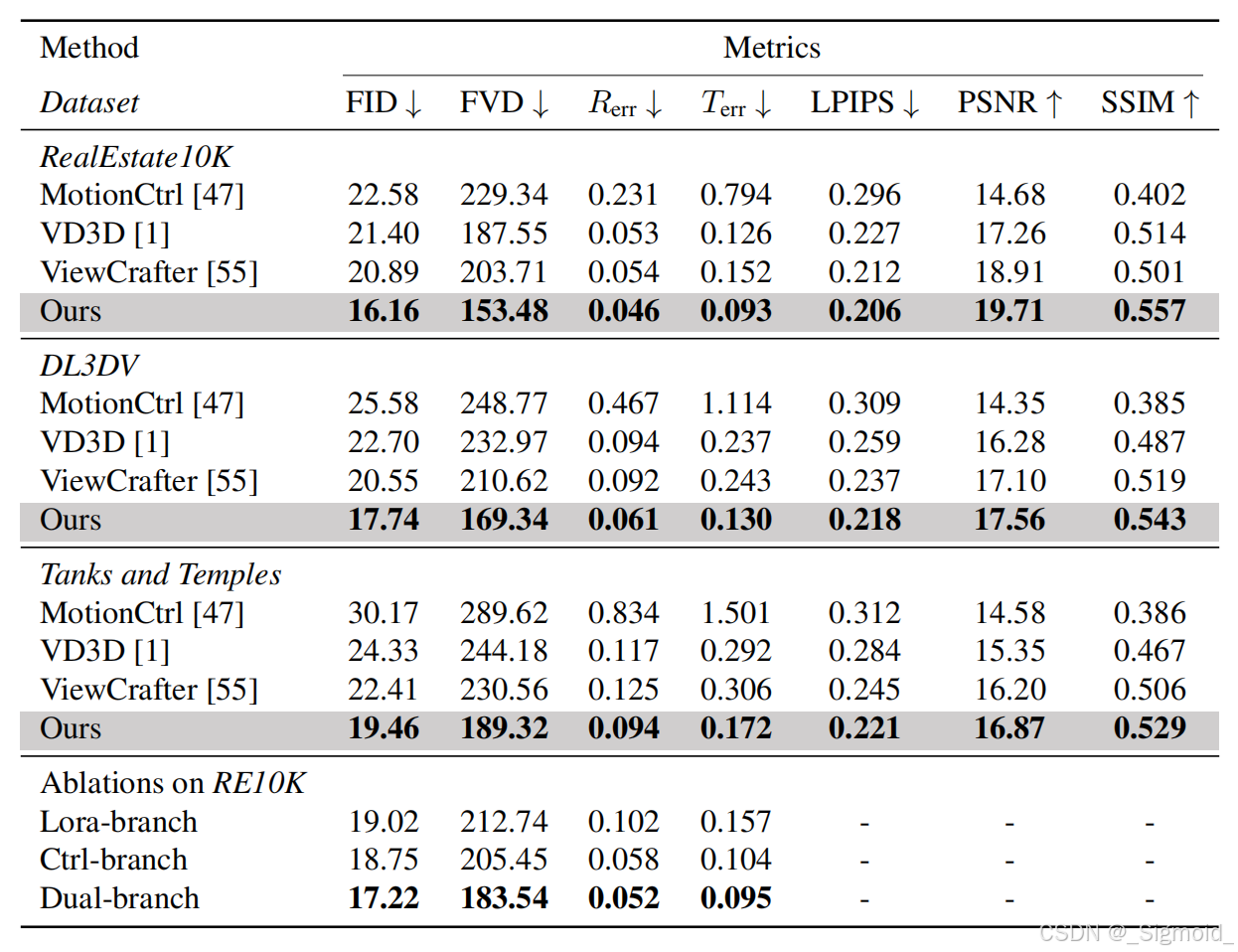
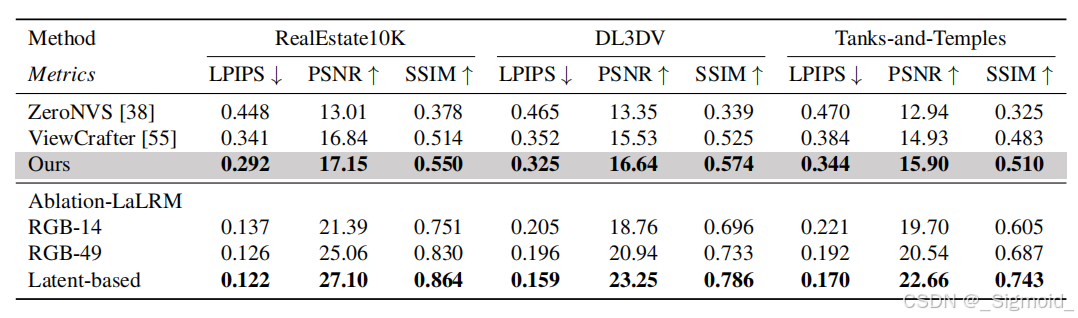


小结
3D场景视频生成技术逐步趋于成熟。传统的深度估计由于几何一致性较差(可能是训练数据内参不一致导致反投影出现墙面倾斜),逐步被3DGS前馈网络替代,可以缓解反投影带来几何一致性问题;传统的上一帧投影+补全模型逐步被视频生成模型所替代,流程上更简洁,内存占用上也有减少。新技术的应用会逐步解决3D场景重建和3D视频生成的挑战


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









