






BAGEL(字节Seed)
论文:https://arxiv.org/abs/2505.14683
代码:https://github.com/bytedance-seed/BAGEL

技术方案
BAGEL采用两个transformer专家的MoT架构,一个负责多模态理解,另一个做多模态生成;相应的有两个视觉编码器:一个理解,一个生成,两个专家用SA处理同样的token序列。当预测下一个token,BAGEL遵循下一个token预测范式,很好的继承了自回归的优势;视觉token预测,采用Rectified Flow的视觉生成模型
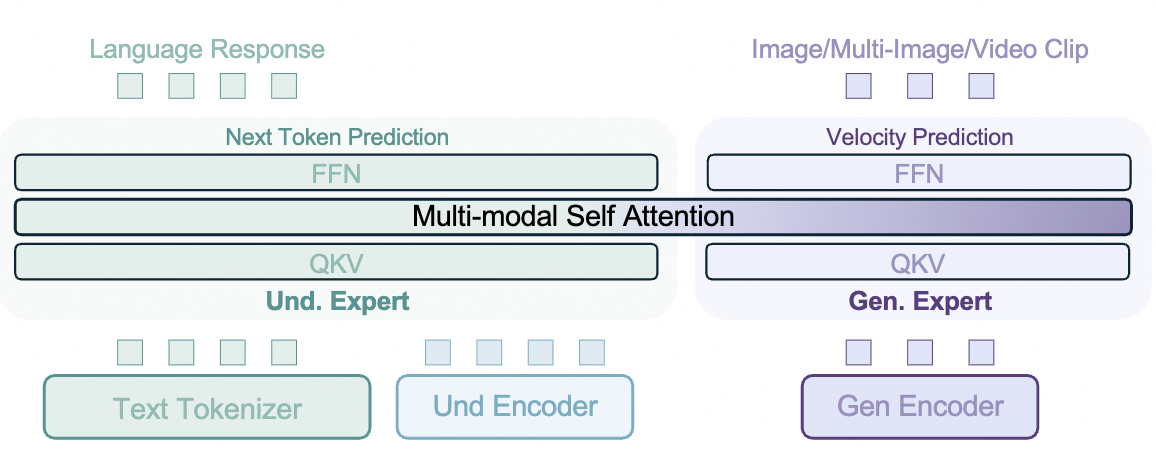
Quantized AR. 可以直接用现有AR框架,缺点是生成质量不如扩散模型,且延时较长。
External Diffuser 外部扩散器,通过轻量、可训练的adaptor链接预训练LLM/VLM到扩散模型。语言模型生成隐token作为语义条件,然后输入扩散模型生成图片,该方法只需要少量数据可以快速收敛,且效果不错;缺点是LLM内容会压缩,导致信息损失,以及理解和生成模块的瓶颈,尤其是长文本推理;
Intergrated Transformer 整合合LLM和扩散模型到一个transformer中,AR和Diffusion优势互补,无缝切换;相比外部扩散模型,要求更高的训练资源;尽管如此,它在整个Transformer块中保持无瓶颈的上下文,从而提供显著优势,使得生成模块和理解模块之间的交互无损失,并且更易于扩展。
本文认为统一模型可以从大规模交错的多模态数据中学习更丰富的多模态能力——这些能力传统基准无法捕捉到。因此,本文采用无瓶颈的整合transformer,作为基模具有巨大潜力处理长文本多模态推理,以及强化学习
Architecture
骨干网络继承了只有解码器的transformer架构,选择Qwen2.5表现最佳,用了RMSNorm、SwiGLU、RoPE位置编码和GQA做KV缓存压缩。额外的,本文加入QK-Norm在每个attention模块中
视觉理解 对于视觉理解,用ViT编码器将像素变成token,采用SigLIP2-so400m/14(输入384分辨率)作为初始化。首先插值到980x980分辨率,融入NaViT处理任意宽高比,分桶训练;两层MLP的connector用于匹配ViT token和LLM的隐状态的维度;
视觉生成. 对于视觉生成,用FLUX的VAE,latent表示下采样8倍、通道变成16,用2x2块编码减少分辨率以匹配LLM骨干的特征维度,并且VAE权重始终固定。
该框架在ViT和VAE中使用2D位置编码,然后整合进LLM骨干中,不用传统DiT中的AdaLN,直接加入时间步嵌入到VAE token中,这样保持了效果,同时结构更干净,多模态相互交错。相同样本的token采用泛化版的因果attention机制,token被划分为多个连续部分,对应不同模态,一个划分中的token会与前面划分的所有token交互,每个划分中,文本token用因果attention,视觉token用双向attention
Generalized Causal Attention
在训练过程中,一个交织的多模态生成样本可能包含多个图像。对于每张图像,我们准备三组视觉标记:
Noised VAE tokens: VAE latent token加入扩散噪声,用Rectified-Flow训练,损失用MSE;
Clean VAE tokens: 原始VAE token,作为条件生成后续图像或文本token;
**ViT tokens: ** ViT token从SigLIP2获得,帮助统一交错生成和理解数据的输入格式并且从经验上看,可以提升交错生成质量。
对于交错的图像和文本生成,后续图文Token关注前边图像的条件VAE token和ViT token,而不关注噪声VAE部分;多图生成用扩散强迫策略,为不同的图像和条件添加独立的噪声水平,并将每张图像条件化为前一张图像的噪声表示;为提升生成一致性,随机分组连续图像,每组用全连接att,且每组噪声水平一样
采用FexAttention,比简单的标量-点积注意力快约2倍,推理时方便缓存生成多模态内容的KV对,加速多模态解码,只有条件VAE token和ViT token的KV对保存,一旦图像完全生成,对应的噪声VAE token会被干净部分替换,为了推理使用CFG,随机丢掉文本、ViT、条件VAE token
Transformer Design
对比三种结构:标准密集Transformer、混合专家transformer和混合transformer
**MoE variant: ** MoE只复制Qwen2.5的FFN网络作为生成专家的初始化;
**MoT variant: ** MoT复制Qwen2.5全部参数作为生成专家;效果更好
新复制的生成专家专门处理VAE token,而原始参数——理解专家——处理文本和ViT token,遵循Qwen-VL系列的策略。尽管MoE和MoT架构相比密集基线将总参数数量大约翻了一番,但在训练和推理期间,所有三种模型变体的FLOPs是相同的。
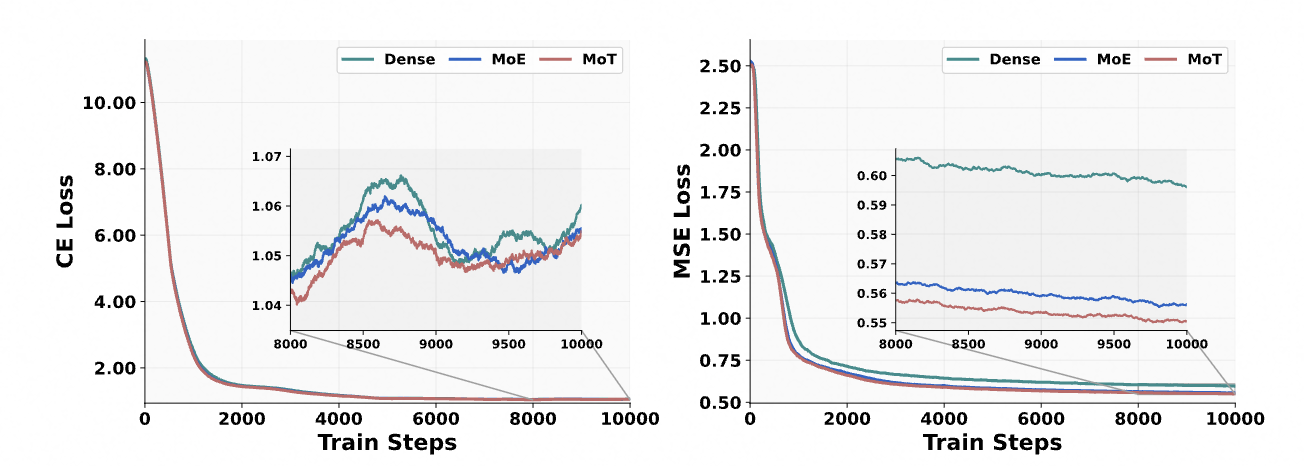
数据采样比例生成4:理解1,可以看出MoT更好
Data
TODO:鉴于FLUX kontext效果更好,暂停本文
实验结果
试用结果:指令理解和遵循不错,生成效果比较模糊、任务偏肥胖、颜色色块明显,不真实。
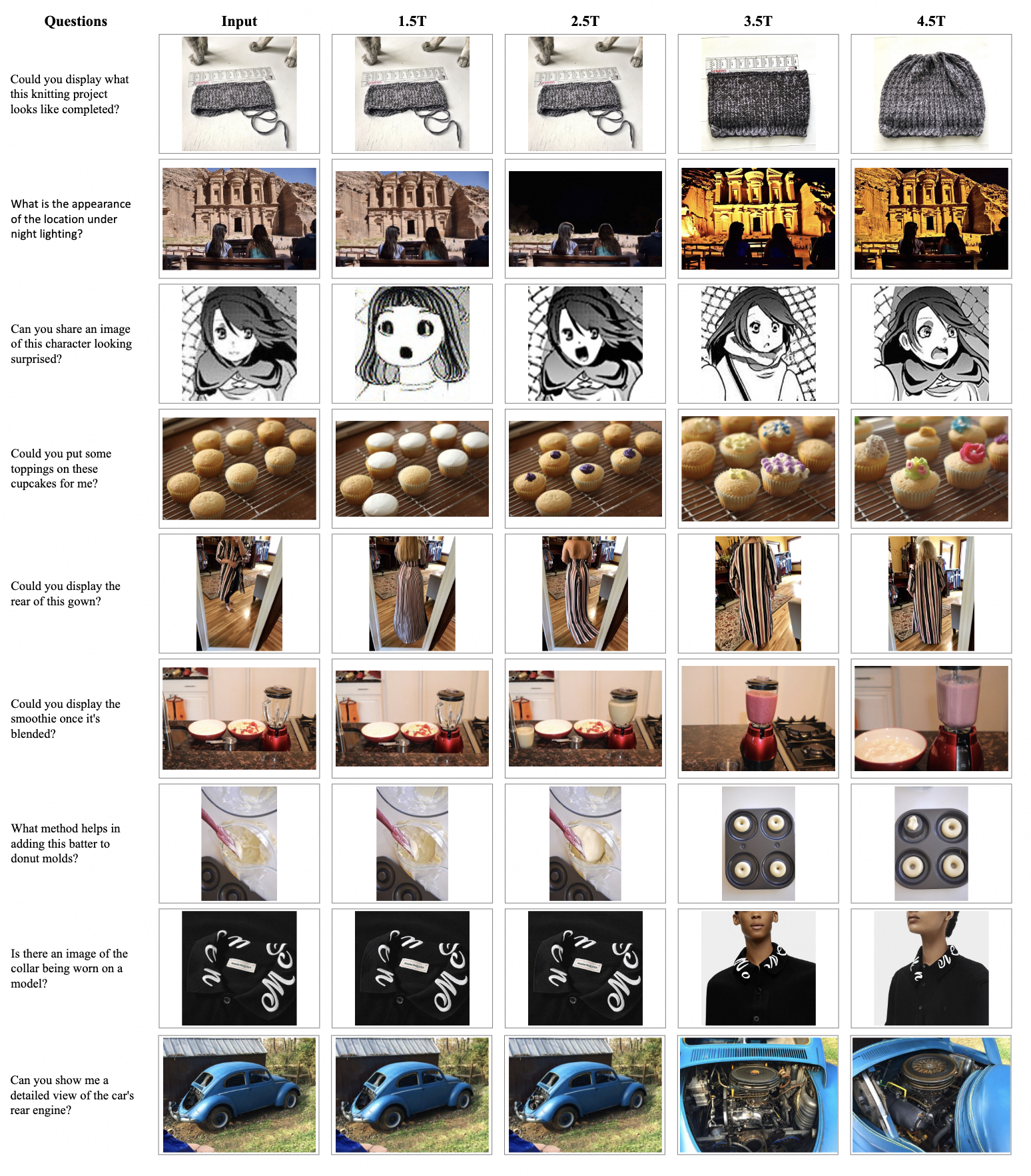



















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









