






Step1X-Edit(阶跃星辰)
论文:https://arxiv.org/abs/2504.17761
代码:https://github.com/stepfun-ai/Step1X-Edit
主要贡献
- 提出 Step1X-Edit 开源模型,逼近闭源的图像编辑模型,如GPT-4o
- 设计一种高质量的高质量图像编辑数据生成的流程
- 提出一个新的benchmark,GEdit-Bench,全面评估真实世界的用户需求

技术方案
数据生成
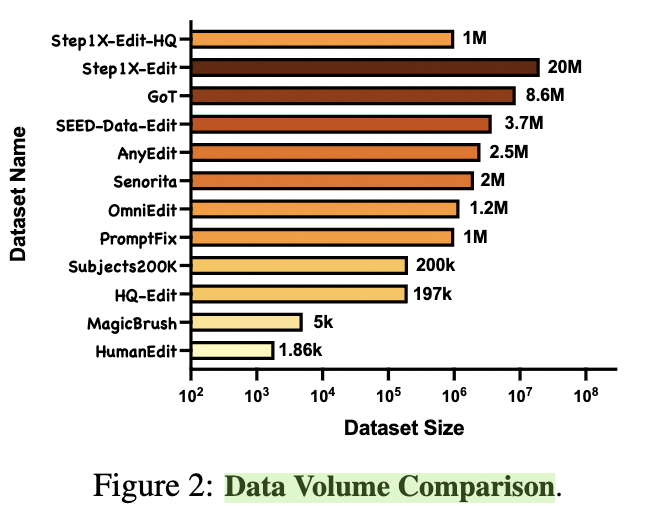
从网上爬取大量图像编辑样例,参考AnyEdit和Ice-bench将图像分为11类任务,设计复杂的数据流程生成2000w的source图、指令和target图的三元组。并经过MLLM如Step 1o和人工标注得到100w高质量三元组。子任务数据生成流程如下
Subject Addition & Removal: 用Florence-2对我们的专有数据进行标注,支持多种语义粒度,空间层级和标注类型,如目标检测、分类。SAM2分割物体,ObjectRemovealAlpha用于补全,指令用Step-1和GPT-4o生成,人工审核保证合理性
Subject Replacement & Background Change: 同上述流程相似,Florence-2标注,SAM2分。但用Qwen2.5-VL和Recognize-Anything识别物体或关键词,Flux-Fill补全内容,指令仍然由Step-1o生成+人工审核
Color Alteration & Material Modification: 采用ZoeDepth估计深度理解目标几何,基于识别的目标变换(例如,颜色或材料的改变),使用ControlNet和扩散模型生成新图像,从而改变外观属性如纹理或颜色的同时保留物体身份。
Text Modification: 需要区分文本编辑的合理与否,用PPOCR关注识别正确的字符,Step-1o模型区分正确和不正确的文本区域,然后生成对应的编辑指令,所有输出会进行人工审核。
Motion Cahnge: 运动相关变换,利用视频数据Koala-36M的pair帧,用BiRefNet和RAFT分割前景和估计flow,计算前景flow范数均值和背景均值,保证只有前景动,GPT-4o描述运动变化作为指令
Portrait Editing and Beautification: 美化数据对:a)从开源得到,人脸检测,通过Step-o1评估layout和背景一致性;b)人体编辑,邀请人来编辑美化,再人工审核
Style Transfer: 吉卜力、水墨、3D动漫生成,从风格化图中生成真实图更好对齐。提取风格图边缘,然后用SD生成真实图;油画、像素风,直接从edge从真实图生成风格化图。
Tone Transformation: 专注于全局色调调整,包括色彩分级、去雾、去雨和季节变换。这些变化主要是由算法工具和自动化过滤器驱动的,以模拟真实的环境变化。

Caption策略
Redundancy-Enhanced Annotation: VLM缺陷有模糊的背景描述和易受幻觉影响,我们采用多轮标注,上轮标注输入迭代细化来增强语义一致性,确定性信息也会反复被强化,保证标注的高可靠性。
Stylized Annotation via Contextual Examples: 在caption制作过程中,会向标注员(或模型)提供大量风格对齐的示例作为上下文参考;这些示例指导字幕的语气、结构和粒度,确保整个数据集保持一致的风格化标注格式。
Cost-Efficient Pipiline: 会先用GPT-4标注caption,再微调内部的Step-o1,最后用Step1o模型大规模标注。
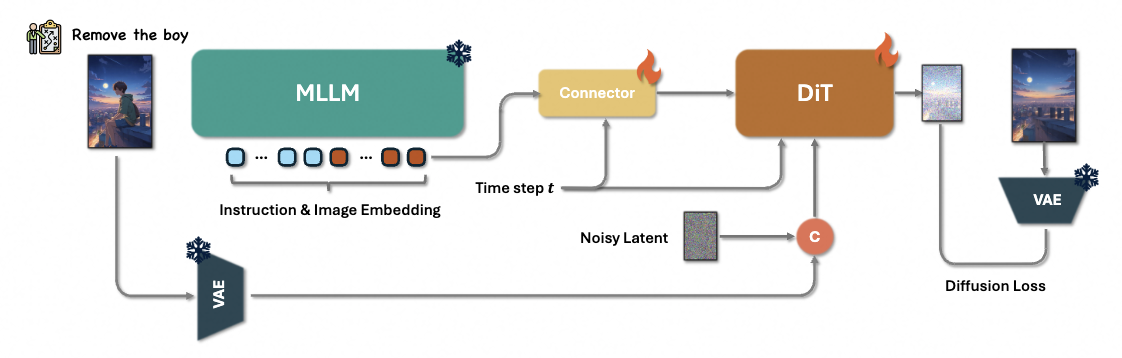
模型结构
模型结构中使用了多模态大语言模型MLLM、connector模块和DiT。Qwen-VL输入参考图像和指令,然后模型捕捉指令和图像间的语义关系,为隔离和强调与编辑任务相关的语义元素,选择性地丢弃与前缀关联的token。过滤过程仅保留与编辑指令直接对齐的token嵌入,确保后续处理精确关注用户指定的编辑要求。
提取的嵌入输入connector如token refiner,将嵌入重组为更紧致的文本特征,然后替换T5的文本嵌入。计算所有Qwen嵌入的均值,均值经过linear生成全局视觉引导向量。这样,图像编辑网络可以利用Qwen提升语义表示能力,编辑更精准
为了有效训练Token Refiner使用更多跨模态条件,使用Token cat,提升模型在视觉情景中的推理能力。训练时,ref和tgt输入,tgt经过VAE编码并加入噪声,然后经过linear映射到token表示,而ref图编码后无需加noise,两个token沿着长度cat得到两倍token输入DiT
实验结果
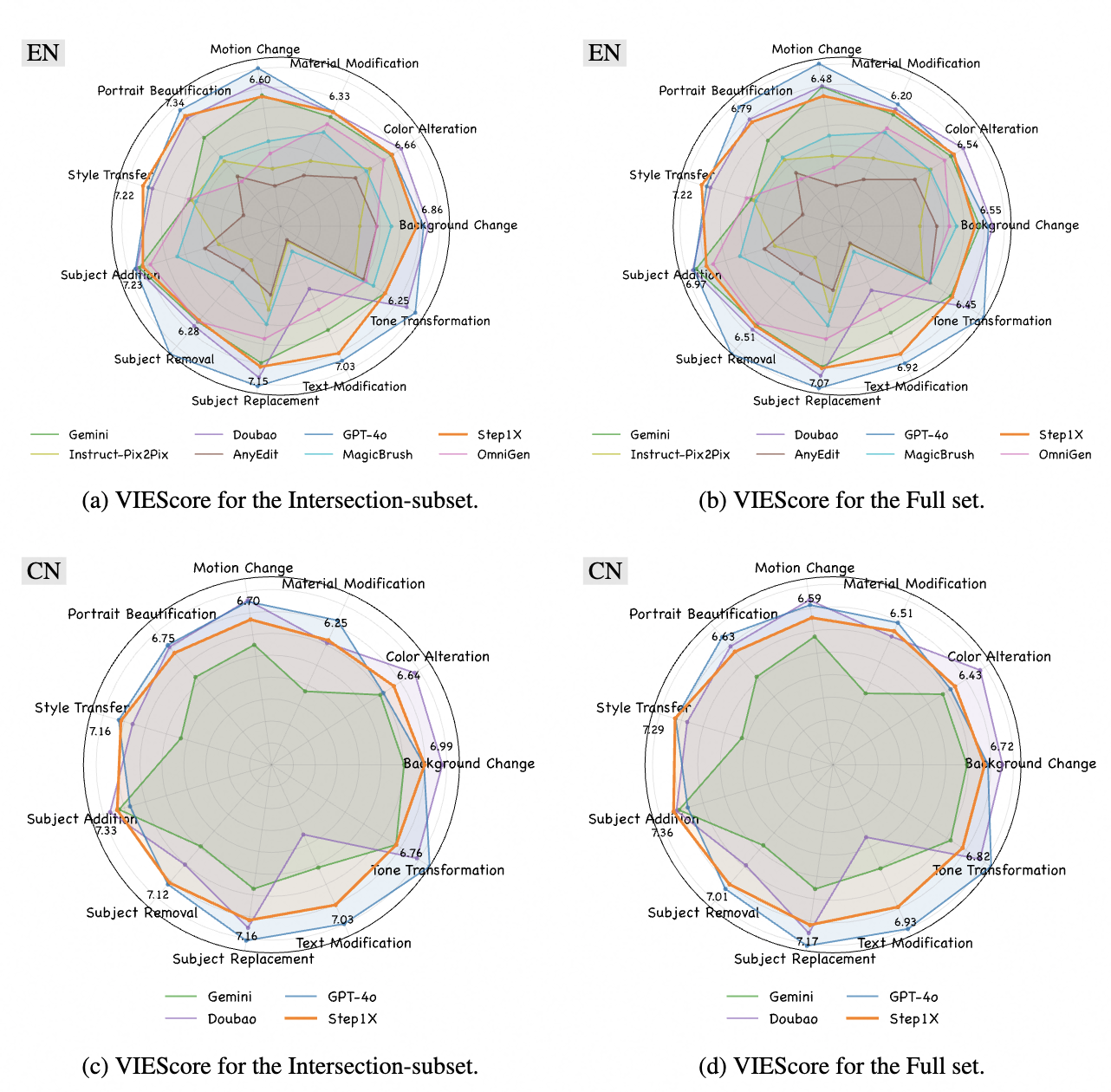
Step1X-Edit确实是开源模型最接近GPT-4o,整体表现与豆包不相上下,但在常见的任务上,会出现分割边缘不准确的异常效果(如背景替换,有残留的背景),在自有数据上微调效果确实会更好,此外,模型中Qwen-VL对中文输入会更友好一些。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









