






StereoCrafter(Tencent AI Lab ARC Lab, Tencent PCG)
论文:https://arxiv.org/abs/2409.07447
代码:https://github.com/TencentARC/StereoCrafter
SVG(Google, The University of Hong Kong)
论文:https://arxiv.org/pdf/2407.00367
代码:https://daipengwa.github.io/SVG_ProjectPage/
StereoDiffusion
论文:https://arxiv.org/abs/2403.04965
代码:https://github.com/lez-s/StereoDiffusion
概要
随着AR、VR设备的兴起,双目立体视频在虚拟现实(VR)、增强现实(AR)和娱乐领域具有广泛的应用前景。然而,生成立体视频面临技术挑战,尤其是如何生成自然的立体视差(stereo parallax),即从两个视角观察时物体位置的差异。传统方法通常需要复杂的3D建模或专用的立体录制设备,这限制了其广泛应用。本文主要介绍最新的基于Diffusion的双目视频生成技术。
技术方案
StereoDiffusion
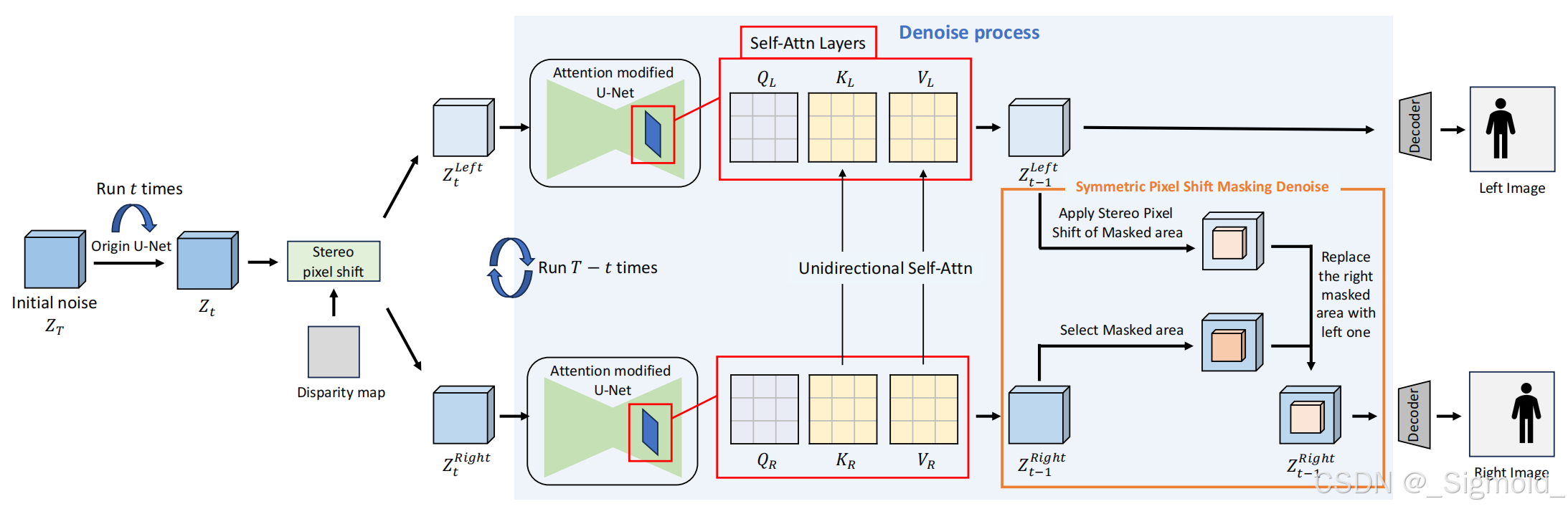
StereoDiffusion主要用于单图的左右视图合成,利用原始输入生成左侧图像并为其估算时差图(DPT或MiDas模型预测),然后通过立体像素移动操作生成右侧图像的潜在向量,通过Self-Attn对齐左右视图,每隔固定时间步,通过Symmetric Pixel Shift Masking Denoise将左视图特征拷贝到右视进行融合,以保证前景不被扩散过程模糊掉(猜测)。
StereoCrafter
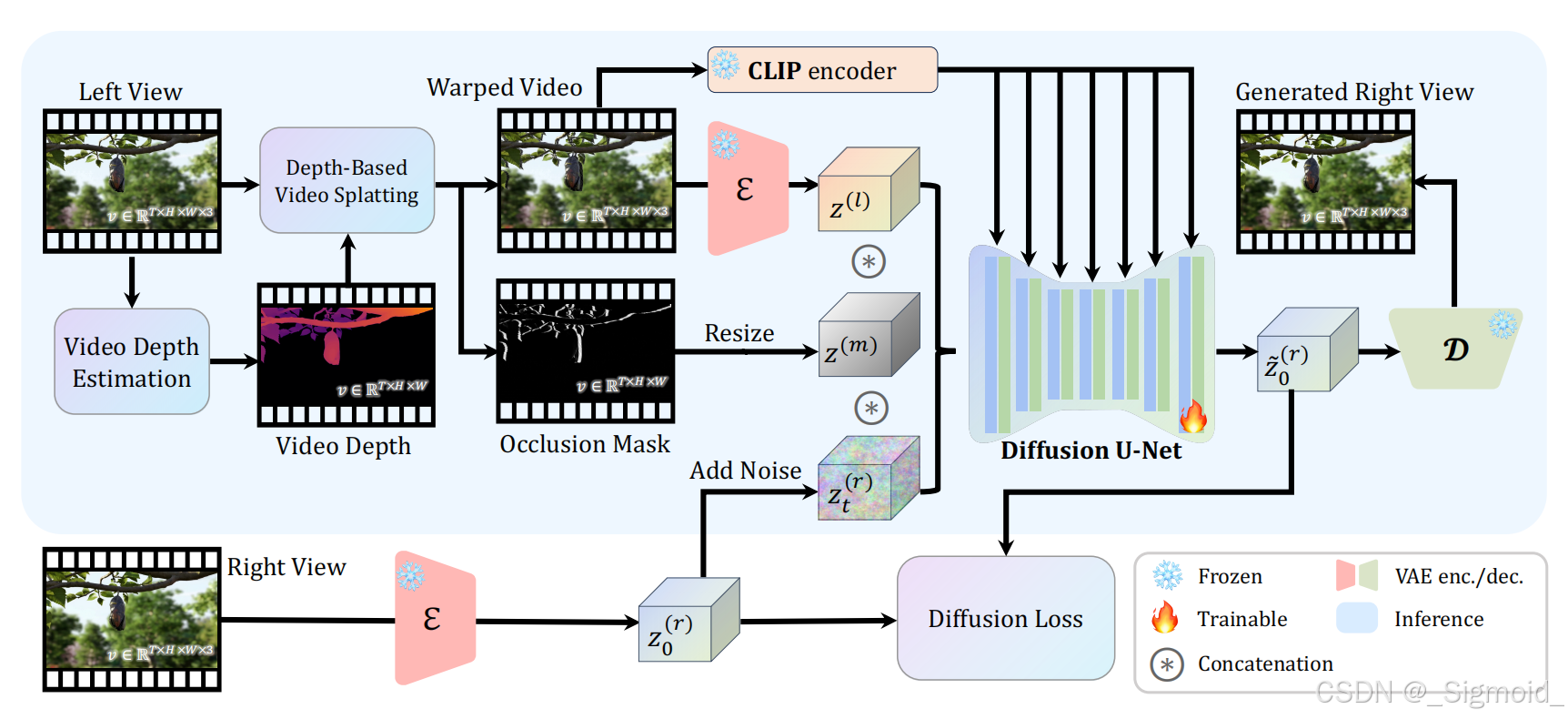
StereoCrafter 利用Diffusion模型能力和构建新数据集实现2D视频转换为具有沉浸式体验的立体3D视频。具体步骤如下:
-
首先,使用视频深度估计模型DepthCrafter或Depth Anything V2获取到精细的视频深度;
-
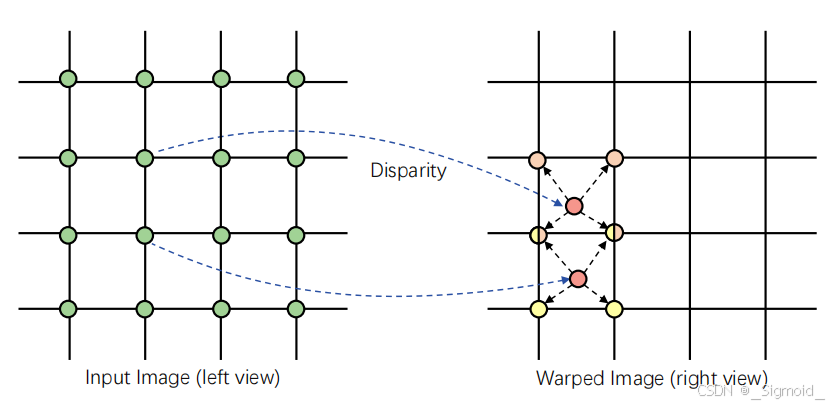
然后将左视图根据视差warp到右视角,具体采用Splatting机制将左视图像素投射到右视图,并采用深度感知方法解决多个像素投影到一个像素的模糊性(类似于OpenGL的深度TEST),同时提取没有像素的mask作为遮挡区域;
-
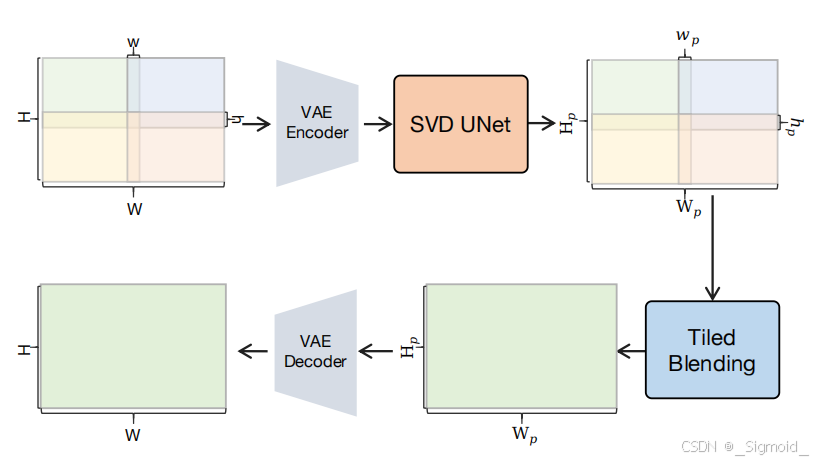
给定warp后的右视图视频,修改了Stable Video Diffusion(SVD)模型用于立体视频补全(Stereo Video Inpainting):1) 将SVD的condition由图像改为warp后的视频帧;2) Unet输入加入额外通道遮挡mask(8->9),并将该通道权重初始化为0;通过两个措施解决视频补全不一致问题和高分辨率补全显存不够的问题:
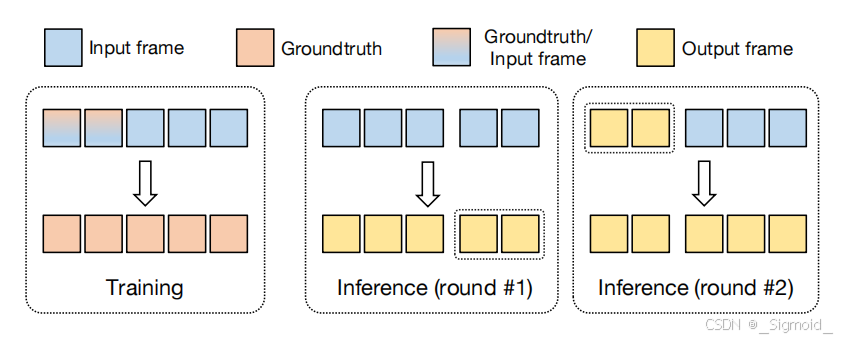
Auto-regressive modeling 自回归建模将视频分为不同的片段,每个片段会把上个片段生成结果的m帧作为当前片段拼接输入,这样模型可以结合上一轮的修复结果来生成时序上更一致的内容(训练过程则保留0-n帧gt,只预测n~N的补全结果)。
Tiled diffusion 逐瓦片扩散,将高分辨率图分为4个重叠的patch,逐个patch进行扩散补全,最后将4个patch的重叠区域进行融合,即 b l e n d e d = w ∗ l e f t + ( 1 − w ) ∗ r i g h t blended = w ∗ lef t + (1 − w) ∗ right blended=w∗left+(1−w)∗right, 其中w从1到0逐步衰减。
SVG
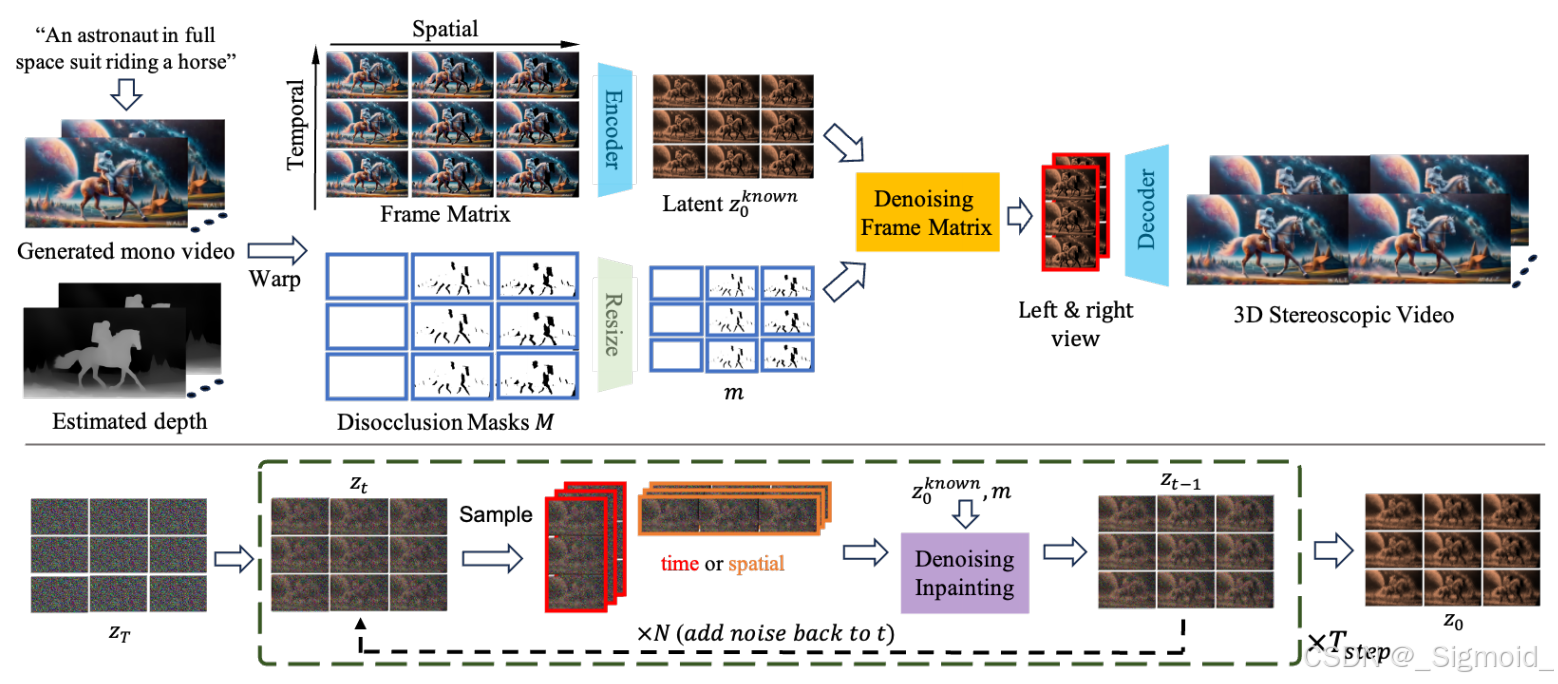
本文方法无需相机位姿估计,无需特定数据集微调即可实现3D立体视频生成。主要采用新颖的Frame Matrix表示进行扩散补全和重新注入方法减少未遮挡区域的负面影响,具体流程如下:
- 给定文本提示词,视频生成模型输出单目视频,采用深度估计模型Depth Anything预测所有帧的深度值,预测光流对深度帧进行对齐,沿时间轴做高斯核卷积平滑深度。根据深度将所有帧warp到目标视图。
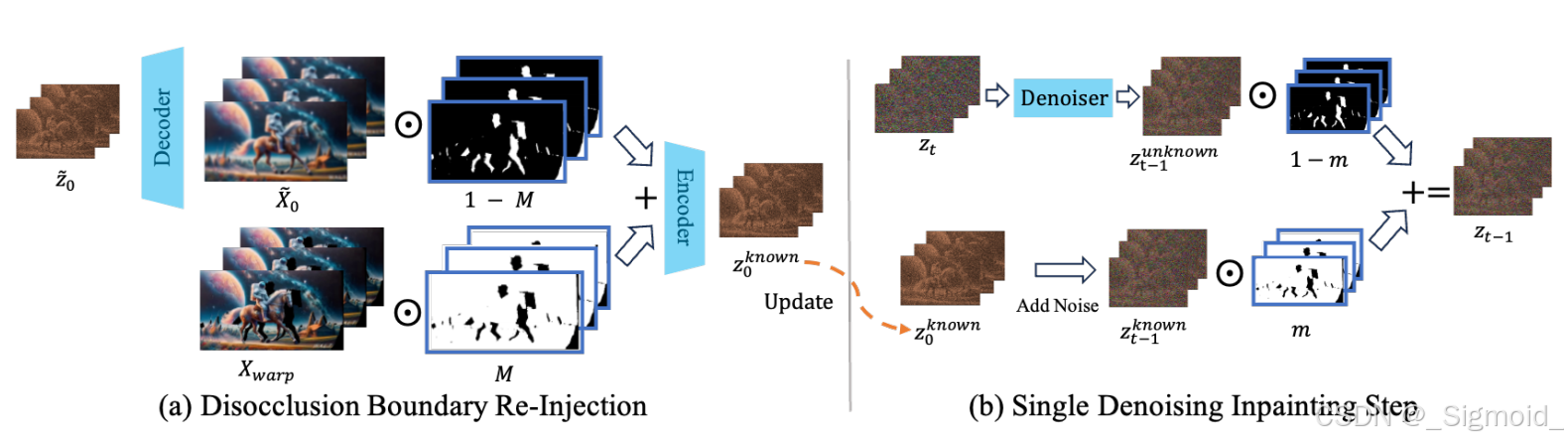
- Video Inpainting with Frame Matrix 单目视频补全采用RePaint或Zeroscope模型,初始的随机噪声和warp图根据遮挡mask进行加权融合得到 z k n o w z_{know} zknow,后续每次生成结果都会和 z k n o w z_{know} zknow进行加权融合。Frame Matrix表示每一列代表不同视角的新视图(共8列),每一行是不同的时间t,训练过程中,每次会采样一行和一列,进行弹幕视频补全。
T-SVG
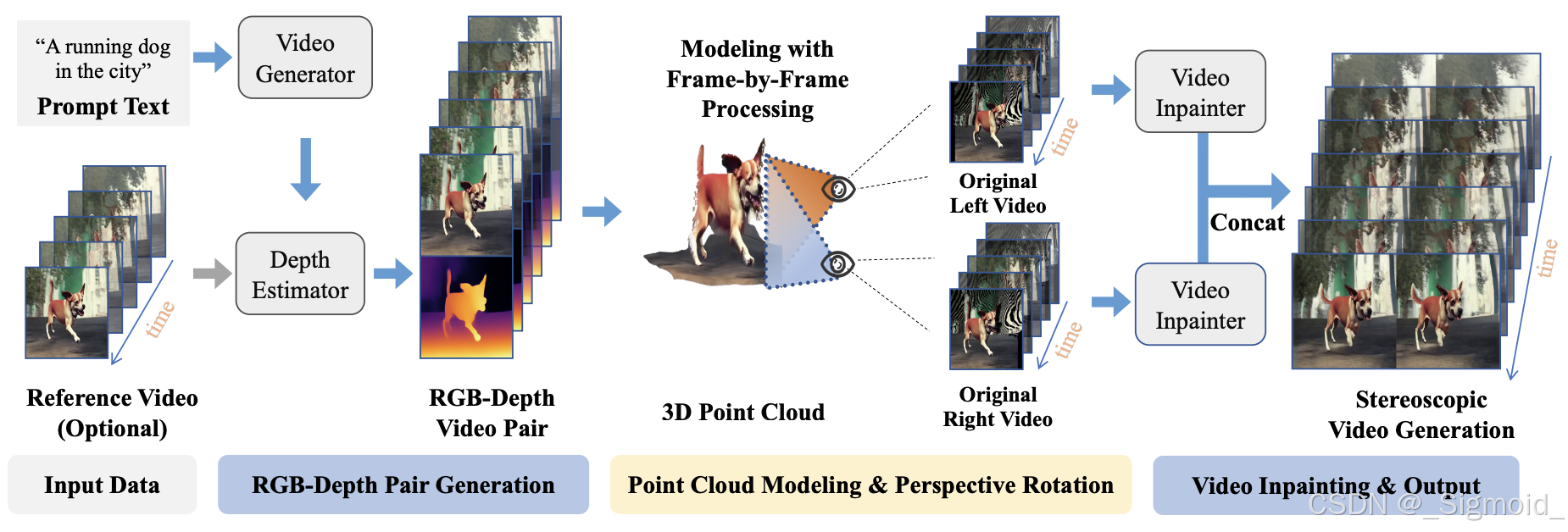
本文在视频估计前加了文生视频模型,生成的视频再预测深度,根据深度warp到左右视图,分别执行Video补全,最后得到双目立体视频
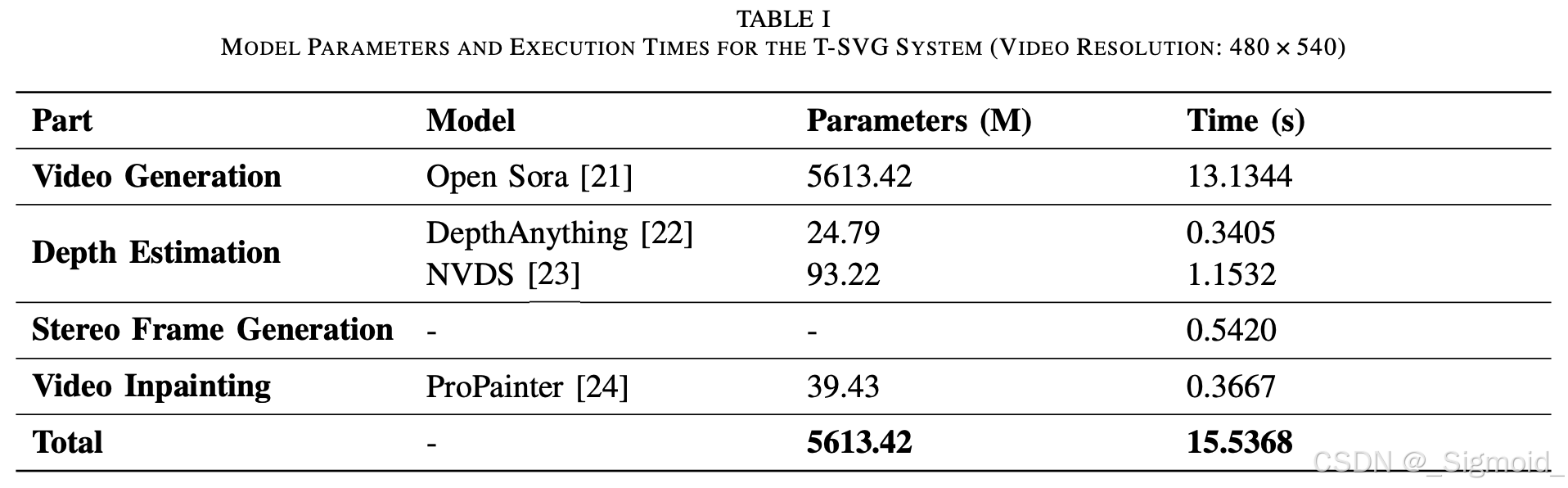
实验结果
StereoCrafter结果


SVG结果


小结
目前SVG和StereoCrafter方法最新,效果也较好,前者视差距离更广,但没有解决前后帧的一致性;后者则采用了较新的视频深度估计模型,有一定的时序一致性。

















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









