






因为自己对图像处理、模式识别比较有兴趣,所以从学校图书馆借了几本书,这3天看了《图像模式识别——VC++技术实现》这本书对分类器的介绍,介绍了4种分类器,模板匹配分类器,Bayes分类器,几何分类器,神经网络分类器。
注意分类判别和聚类判别的区别:
分类判别的前提是已知若干个样品的类别以及每个样品的特征,在此基础上才能对待测样品进行分类判别。例如,手写阿拉伯数字的判别是一个具有10类的分类问题,由于同一个数字,不同的人有不同的写法,甚至同一个人对同一个数字也有多种写法,及其首先要知道大多数手写数字的形状特征,它们属于哪一类。因此对分类问题需要建立样品库。根据这些样品库建立判别分类函数,这一过程是由机器来实现的,称为学习过程,然后对一个未知的新对象分析它的特征,决定它属于哪一类。
聚类分析前提是已知若干对象和它们的特征,但是不知道每个对象属于哪一类,而且事先并不知道究竟分成多少类,在此基础上用某种相似性度量的方法,把特征相似的归为一类。例如,手写了若干个阿拉伯数字,把相同的数字归为一类。这是一种非监督学习的方法。
一、模板匹配分类器
关于这个问题,从书里看我觉得最让人明白模板匹配分类器的一段话,就是“譬如A类有10个训练样品,就有10个模板,B类有8个训练样品,就有8个模板。任何一个待测样品在分类时与这18个模板都算一算相似度,找出最相似的模板,如果该模板是B类中的一个,就确定待测样品为B类,否则为A类。”意思很简单吧,算相似度就是算距离。就是说,模板匹配就要用你想识别的样品与各类中每个样品的各个模板用距离公式计算距离,距离最短的那个就是最相似的。这样的匹配方法明显的缺点就是在计算量大,存储量大,每个测试样品要对每个模板计算一次相似度,如果模板量大的时候,计算量就十分的大。
模板匹配的过程:1、对待测样品进行;2、对待测样品进行特征提取;3、计算待测样品与所有类别的所有模板进行近似值计算;4、近似值最小的模板所属类别就是待测样品的类别。
距离:2个D维特征的样品分别为XA(xA1, xA2, ..., xAd), XB(xB1, xB2, ..., xBd)。两样品的距离就是(xAi, xBj为特征)
d(x, y) = [∑(xi - yi)2]1/2 ,其中i = 1 to d
二、Bayes分类器(贝叶斯分类器)
Bayes是的原理是统计概率。其中Bayes分类器分为最小错误率Bayes,和最小错误风险的Bayes。最小错误率是指划分错误最小的划分方法,最小错误风险是指带风险权值去进行划分,划分后令划分错误所带来的风险最低。
Bayes公式:
已知总共有M类样品,根据概率的知识,可以通过样品库得知已知类别wi =1, 2, ...., M的先验概率P(wi)及类条件概率密度P(X | wi)。对于待检测样品,Bayes公式可以计算出该样品分属各类别的概率,叫做后验概率,看P(wi | X)哪个最大,就属于哪各分类。
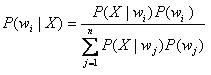
经过若干化简后,得出实现的一般步骤。
1、最小错误率:
①、求出每一类样品的均值, Ni代表类别wi的样品个数,n代表特征数目,Xij代表第i类样品的第j个特征,m为类别数
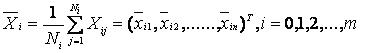
②、求每一类的协方差矩阵
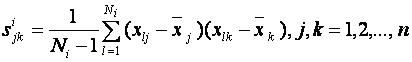
l代表样品在wi类中的序号,l = 0, 1, 2, ..., Ni。
xlj代表wi类的第l个样品,第j个特征值。
xj代表wi类的Ni个样品第j个特征的平均值。
xjk代表wi类的第l个样品,第k个特征值。
xk代表wi类的Ni个样品第k个特征的平均值。
wi的协方差矩阵为
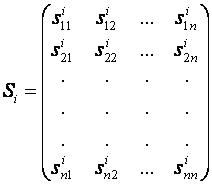
③、计算出每一类的协防差矩阵的逆矩阵![]() 以及协方差矩阵的行列式|Si|。
以及协方差矩阵的行列式|Si|。
④、求出每一类的先验概率
![]()
其中P(wi)是类别为样品i的先验概率,Ni为样品i的样品数,N为样品总数。
⑤、将以上各个数值代入判别函数,X为待测样品特征向量,hi(X)为后验概率P(wi | X)
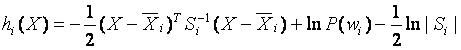
⑥、判别函数最大值所对应类别就是待测样品的类别。
①到④是学习训练的时候做的。
⑤、⑥是识别时的操作。
1、最小错误风险:
前6部跟最小错误率相同,添加最后一步;
⑦、定义损失数组为loss[m][m](λ(αu, v)), 意义如下:
如样品是第C类,但被误分为第D类,那么所造成的风险是loss[c][d](u类被认为是V类所造成的风险为λ(αu, v))。
设置损失数组的值,定义Ri(X)为待测值X被判为i类时损失的均值。计算每一类风险的均值。
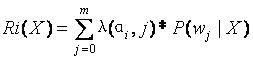
Ri(X)最小则风险最小,即i为待测样品的类别。
①到④是学习训练的时候做的。
⑤到⑦是识别时的操作。
剩下的留下此记吧...累哦。
转载请留言并注明啊,写个东西不容易呢,谢谢。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









