







http://antkillerfarm.github.io/
拉格朗日对偶(续)
如果w不满足约束,也就是 gi(w)>0 或 hi(w)≠0 。这时由于 L 函数是无约束函数, αi 、 βi 可以任意取值,因此 ∑ki=1αigi(w) 或 ∑li=1βihi(w) 并没有极值,也就是说 θP(w)=∞ 。
反之,如果w满足约束,则 ∑ki=1αigi(w) 和 ∑li=1βihi(w) 都为0,因此 θP(w)=f(w) 。
综上:
我们定义:
下面我们定义对偶函数:
这里的 D 代表原始优化问题的对偶优化问题。仿照原始优化问题定义如下:
这里我们不加证明的给出如下公式:
这样的对偶问题被称作拉格朗日对偶(Lagrange duality)。
KKT条件
拉格朗日对偶公式中使
其中的 w∗,α∗,β∗ 表示满足KKT条件的相应变量的取值。条件1也被称为KKT对偶互补条件(KKT dual complementarity condition)。显然这些 w∗,α∗,β∗ 既是原始问题的解,也是对偶问题的解。
严格的说,KKT条件是非线性约束优化问题存在最优解的必要条件。这个问题的充分条件比较复杂,这里不做讨论。
注:Harold William Kuhn,1925~2014,美国数学家,普林斯顿大学教授。
Albert William Tucker,1905~1995,加拿大数学家,普林斯顿大学教授。
William Karush,1917~1997,美国数学家,加州州立大学北岭分校教授。(注意,California State University和University of California是不同的学校)
支持向量
针对最优边距分类问题,我们定义:
由KKT对偶互补条件可知,如果 αi>0 ,则 gi(w)=0 。
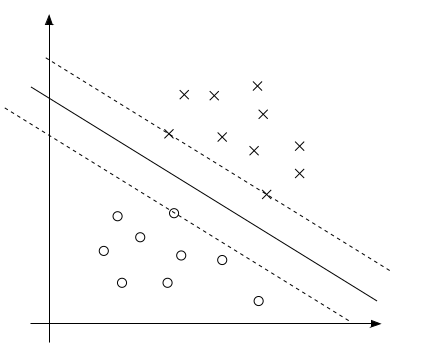
上图中的实线表示最大边距的分割超平面。由之前对于边距的几何意义的讨论可知,只有离该分界线最近的几个点(即图中的所示的两个x点和一个o点)才会取得约束条件的极值,即 gi(w)=0 。也只有这几个点的 αi>0 ,其余点的 αi=0 。这样的点被称作支持向量(support vectors)。显然支持向量的数量是远远小于样本集的数量的。
为我们的问题构建拉格朗日函数如下:
为了求解
可得:
即
对b求导可得:
把公式3代入公式2,可得:
我们定义如下内积符号 ⟨x,y⟩=xTy ,并将公式4代入公式5可得:
最终我们得到如下对偶优化问题:
这个对偶问题的求解,留在后面的章节。这里只讨论求解出 α∗ 之后的情况。
首先,根据公式3可求解 w∗ 。然后
除此之外,我们还有:
在之前的讨论中,我们已经指出只有支持向量对应的 αi 才为非零值,因此:
从上式可以看出,在空间维数比较高的情况下,SVM(support vector machines)可以有效降低计算量。
核函数
假设我们从样本点的分布中看到x和y符合3次曲线,那么我们希望使用x的三次多项式来逼近这些样本点。那么首先需要将特征x扩展到三维 (x,x2,x3) ,然后寻找特征和结果之间的模型。我们将这种特征变换称作特征映射(feature mapping)。
映射函数记作 ϕ(x) ,在这个例子中
有的时候,我们希望将特征映射后的特征,而不是最初的特征,应用于SVM分类。这样做的情况,除了上面提到的拟合问题之外,还在于样例可能存在线性不可分的情况,而将特征映射到高维空间后,往往就可分了。如下图所示:
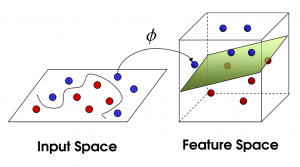
为此,我们给出核函数(Kernel)的形式化定义:
之所以是形式化定义,这主要在于我们并不利用 ϕ(x) 来计算 K(x,z) ,而是给定K(x,z),来倒推 ϕ(x) ,从而建立 ϕ(x) 和 K(x,z) 之间的对应关系。
例如:
根据上式可得:(这里假设 n=3 )
可以看出 ϕ(x) 的计算复杂度是 O(n2) ,而 (xTz)2 的计算复杂度是 O(n) 。
下面我们讨论其他几种常用核函数和它对应的 ϕ(x) 。
同样的:( n=3 )
更一般的,对于 K(x,z)=(xTz+c)d ,其对应的 ϕ(x) 是 (n+dd) 维向量。
我们也可以从另外的角度观察 K(x,z)=ϕ(x)Tϕ(z) 。从内积的几何意义来看,如果 ϕ(x) 和 ϕ(z) 夹角越小,则 K(x,z) 的值越大;反之,如果 ϕ(x) 和 ϕ(z) 的夹角越接近正交,则 K(x,z) 的值越小。因此, K(x,z) 也叫做 ϕ(x) 和 ϕ(z) 的余弦相似度。
讨论另一个核函数:
这个核函数被称为高斯核函数(Gaussian kernel),对应的 ϕ(x) 是个无限维的向量。
注: (a+b)n 是个p为0.5的二项分布,由棣莫佛-拉普拉斯定理(de Moivre–Laplace theorem)可知,当 n→∞ 时,它的极限是正态分布。

核函数的有效性
如果对于给定的核函数K,存在一个特征映射 ϕ ,使得 K(x,z)=ϕ(x)Tϕ(z) ,则称K为有效核函数。
我们首先假设K为有效核函数,来看看它有什么性质。假设有m个样本 {x(1),…,x(m)} ,我们定义 m×m 维的矩阵k: Kij=K(xi,xj) 。这个矩阵被称为核矩阵(Kernel matrix)。
如果我们用 ϕk(x) 表示 ϕ(x) 第k个元素的话,则对于任意向量z:
即K矩阵是半正定矩阵。事实上,K矩阵是对称半正定矩阵,不仅是K函数有效的必要条件,也是它的充分条件。相关的证明是由James Mercer给出的,被称为Mercer定理(Mercer Theorem)。
注:James Mercer,1883-1932,英国数学家,英国皇家学会会员,毕业于剑桥大学。曾服役于英国皇家海军,参加了日德兰海战。
Mercer定理给出了不用找到 ϕ(x) ,而判定 K(x,z) 是否有效的方法。因此寻找 ϕ(x) 的步骤就可以跳过了,直接使用 K(x,z) 替换上面公式中的 ⟨x,z⟩ 即可。例如:
核函数不仅仅用在SVM上,但凡在一个算法中出现了 ⟨x,z⟩ ,我们都可以使用 K(x,z) 去替换,这可以很好地改善我们算法的效率。因此,核函数更多的被看作是一种技巧而非理论(kernel trick)。
规则化和不可分情况处理
我们之前讨论的情况都是建立在样例线性可分的假设上,当样例线性不可分时,我们可以尝试使用核函数来将特征映射到高维,这样很可能就可分了。然而,映射后我们也不能100%保证可分。那怎么办呢,我们需要将模型进行调整,以保证在不可分的情况下,也能够尽可能地找出分隔超平面。
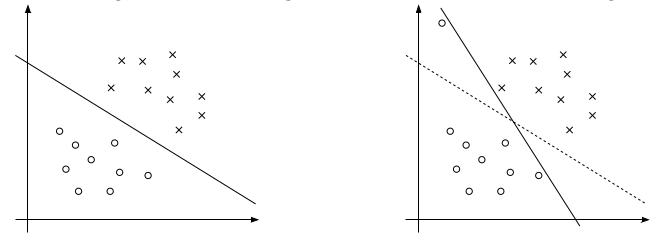
上面的右图中可以看到一个离群点(可能是噪声),它会造成超平面的移动,从而导致边距缩小,可见以前的模型对噪声非常敏感。再有甚者,如果离群点在另外一个类中,那么这时候就是线性不可分的了。















 1793
1793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









