http://antkillerfarm.github.io/
对
Σ
的限制(续)
这实际上也就是方法一中对角线元素的均值,反映到二维高斯分布图上就是椭圆变成圆。
当我们要估计出完整的
Σ
时,我们需要
m≥n+1
才能保证在最大似然估计下得出的
Σ
是非奇异的。然而在上面的任何一种假设限定条件下,只要
m≥2
就可以估计出限定的
Σ
。
这样做的缺点也是显而易见的,我们认为特征间相互独立,这个假设太强。接下来,我们给出一种称为因子分析(factor analysis)的方法,使用更多的参数来分析特征间的关系,并且不需要计算一个完整的
Σ
。
利用多元高斯分布密度函数计算积分的技巧
I(A,b,c)=∫xexp(−12(xTAx+xTb+c))dx
其中A为对称正定矩阵,b为向量。对于上面这样的积分,可以使用“完全配方法”(completion-of-squares)的数学技巧求解。
因为
xTAx+xTb+c=(x−h)TA(x−h)+k
其中
h=−A−1b2,k=c−bTA−1b4
。
所以
I(A,b,c)=∫xexp(−12((x−h)TA(x−h)+k))dx=∫xexp(−12(x−h)TA(x−h)−k/2)dx=exp(−k/2)⋅∫xexp(−12(x−h)TA(x−h))dx
令
μ=h,Σ=A−1
,则:
I(A,b,c)=(2π)n/2∣Σ∣1/2exp(k/2)⋅∫x1(2π)n/2∣Σ∣1/2exp(−12(x−μ)TΣ−1(x−μ))dx
公式右侧的被积分函数,正好是多元高斯分布密度函数,因此该积分值为1。于是:
I(A,b,c)=(2π)n/2∣Σ∣1/2exp(k/2)
注:原始讲义里,Chuong B. Do写的《Gaussian processes》的附录A.1和本节内容类似,但推导过程有问题,疑似笔误,特更换为维基百科中的例子。(矩阵的完全配方那块的变换,我能推导出维基百科的结果,但推导不出Chuong B. Do的结果。)如有错误,望读者指出。
边缘和条件高斯分布
假设x由两个随机向量组成(可以看作是将之前的
x(i)
分成了两部分)。
x=[x1x2]
其中
x1∈Rr,x1∈Rs
,则x实际上是
r+s
维向量。
假设
x∼N(μ,Σ)
,其中:
μ=[μ1μ2],Σ=[Σ11Σ21Σ12Σ22]
因为协方差矩阵是对称矩阵,因此
Σ12=ΣT21
。
Cov(x)=Σ=[Σ11Σ21Σ12Σ22]=E[(x−μ)(x−μ)T]=E[(x1−μ1x2−μ2)(x1−μ1x2−μ2)]=E[(x1−μ1)(x1−μ1)T(x2−μ2)(x1−μ1)T(x1−μ1)(x2−μ2)T(x2−μ2)(x2−μ2)T]
因此,
E[x1]=μ1,Cov(x1)=E[(x1−μ1)(x1−μ1)T]=Σ11
。可见,多元高斯分布的边缘分布仍然是多元高斯分布。
下面讨论一下条件高斯分布。
p(x1|x2)=p(x1,x2)p(x2)=1(2π)n/2∣Σ∣1/2exp(−12(x−μ)TΣ−1(x−μ))∫x1p(x1,x2;μ,Σ)dx1=1Z1exp⎧⎩⎨−12([x1x2]−[μ1μ2])T[V11V21V12V22]([x1x2]−[μ1μ2])⎫⎭⎬
其中的
Z1
是和
x1
无关的部分,可看作常数,下面的
Zi
也是同理。
Σ−1=V=[V11V21V12V22]
因为:
([x1x2]−[μ1μ2])T[V11V21V12V22]([x1x2]−[μ1μ2])=(x1−μ1)TV11(x1−μ1)+(x1−μ1)TV12(x2−μ2)+(x2−μ2)TV21(x1−μ1)+(x2−μ2)TV22(x2−μ2)
保留上式中与
x1
有关的部分,可得:
p(x1|x2)=1Z2exp(−12(xT1V11x1−2xT1V11μ1+2xT1V12(x2−μ2)))
使用上一节中的完全配方技巧,可得:
p(x1|x2)=1Z3exp(−12(x1−μ1|2)TV11(x1−μ1|2))
其中:
μ1|2=μ1−V−111V12(x2−μ2)(1)
即:
x1|x2∼N(μ1−V−111V12(x2−μ2),V−111)
另,根据分块矩阵的求逆法则,可得:
Σ−1=[Σ11Σ21Σ12Σ22]−1=[(Σ11−Σ12Σ−122Σ21)−1−Σ−122Σ21(Σ11−Σ12Σ−122Σ21)−1−(Σ11−Σ12Σ−122Σ21)−1Σ12Σ−122(Σ22−Σ21Σ−111Σ12)−1]
因此:
Σ1|2=V−111=Σ11−Σ12Σ−122Σ21(2)
因子分析的例子
下面通过一个简单例子,来引出因子分析背后的思想。
假设我们有m=5个2维的样本点
xi
,如下:
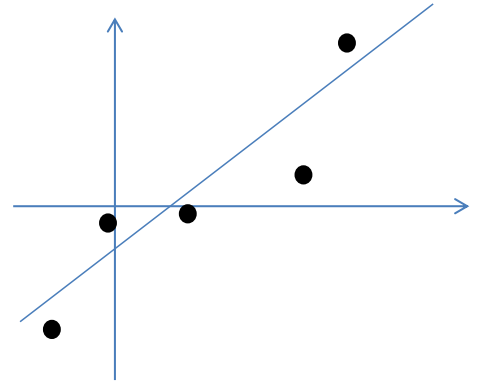
按照因子分析模型,样本点的生成过程如下:
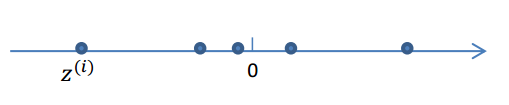
1.我们首先认为在1维空间(这里k=1),存在着按正态分布生成的m个点
z(i)
,即:
z(i)∼N(0,I)
这里的I是单位矩阵。
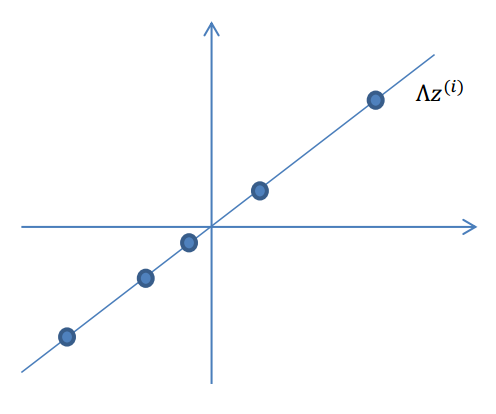
2.使用变换矩阵
Λ∈Rn×k
,将
z(i)
映射到n维空间中,即
Λz(i)
。
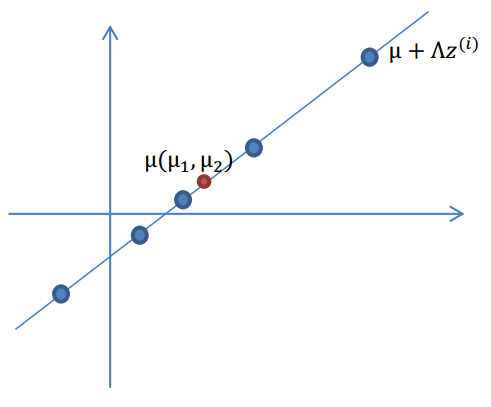
3.使用n维向量
μ
,将
Λz(i)
移动到样本的中心点
μ
,即
μ+Λz(i)
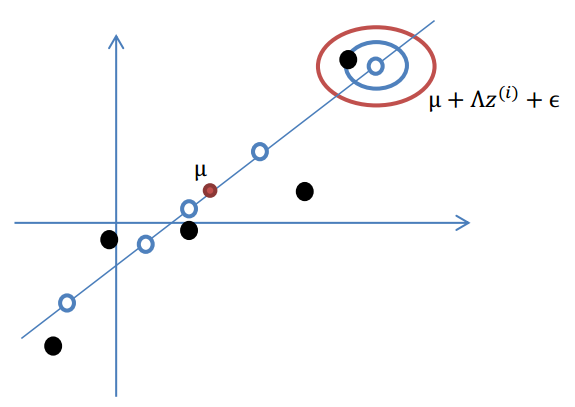
4.样本点不可能这么规则,在模型上会有一定偏差,因此我们需要将上步生成的点做一些扰动(误差)。这里添加一个n维的扰动向量
ϵ∼N(0,Ψ)
。
综上可得:
x(i)=μ+Λz(i)+ϵ
x|z∼N(μ+Λz,Ψ)
由以上的直观分析,我们知道了因子分析其实就是认为:高维样本点实际上是由低维样本点经过高斯分布、线性变换、误差扰动生成的,因此高维数据可以使用低维来表示。
线性回归的概率模型
在进一步讨论因子分析模型之前,我们首先讨论一下,和它类似的线性回归的概率模型。
从概率的角度看,线性回归中的
y(i)
可以看作是预测函数
hθ(x)
加上扰动后的结果。即:
y(i)=θTx(i)+ϵ(i),ϵ(i)∼N(0,σ2)
p(ϵ(i))=12π−−√σexp(−(ϵ(i))22σ2)
p(y(i)|x(i);θ)=12π−−√σexp(−(y(i)−θTx(i))22σ2)
ℓ(θ)=log∏i=1m12π−−√σexp(−(y(i)−θTx(i))22σ2)=∑i=1mlog12π−−√σexp(−(y(i)−θTx(i))22σ2)=mlog12π−−√σ−1σ2⋅12∑i=1m(y(i)−θTx(i))2
从上式可以看出采用极大似然估计和采用代价函数
J(θ)
的效果是一样的。其中:
J(θ)=12∑i=1m(y(i)−θTx(i))2
因子分析模型
假设z和x的联合分布为:
[zx]∼N(μzx,Σ)
我们的任务就是求出
μzx
和
Σ
。
因为:
E[x]=E[μ+Λz+ϵ]=μ+ΛE[z]+E[ϵ]=μ
所以:
μzx=[0⃗ μ]
因为:
Σ=[ΣzzΣxzΣzxΣxx]
所以我们只要分别计算这四个值即可。
因为
z∼N(0,I)
,所以
Σzz=I
。
Σzx=E[(z−E[z])(x−E[x])T]=E[(z−0)(μ+Λz+ϵ−μ)T]=E[z(Λz+ϵ)T]=E[z(Λz)T+zϵT]=E[zzTΛT+zϵT]=E[zzT]ΛT+E[zϵT]
因为z和
ϵ
是相互独立的随机变量,因此
E[zϵT]=E[z]E[ϵT]=0
。
又因为
E[zzT]=Cov(z)=I
,所以
Σzx=ΛT
。
Σxx=E[(x−E[x])(x−E[x])T]=E[(μ+Λz+ϵ−μ)(μ+Λz+ϵ−μ)T]=E[(Λz+ϵ)(ΛzT+ϵT)]=E[Λz(Λz)T+ϵ(Λz)T+ΛzϵT+ϵϵT]=E[ΛzzTΛT+ϵzTΛT+ΛzϵT+ϵϵT]=ΛE[zzT]ΛT+E[ϵzT]ΛT+ΛE[zϵT]+E[ϵϵT]=ΛIΛT+0+0+Ψ=ΛΛT+Ψ
把这些结果合在一起,可得:
[zx]∼N([0⃗ μ],[IΛΛTΛΛT+Ψ])(3)
从这个结论可以看出:
x∼N(μ,ΛΛT+Ψ)
因此它的对数似然函数为:
ℓ(μ,Λ,Ψ)=log∏i=1m1(2π)n/2∣ΛΛT+Ψ∣1/2exp(−12(x(i)−μ)T(ΛΛT+Ψ)−1(x(i)−μ))
但这个函数是很难最大化的,需要使用EM算法解决之。
因子分析的EM估计
E-step比较简单。由公式1、2、3,可得:
μz(i)|x(i)=ΛT(ΛΛT+Ψ)−1(x(i)−μ)
Σz(i)|x(i)=I−ΛT(ΛΛT+Ψ)−1Λ
因此:
Qi(z(i))=1(2π)n/2∣Σz(i)|x(i)∣1/2exp(−12(x(i)−μz(i)|x(i))TΣ−1z(i)|x(i)(x(i)−μz(i)|x(i)))
M-step的最大化的目标是:
∑i=1m∫z(i)Qi(z(i))logp(x(i),z(i);μ,Λ,Ψ)Qi(z(i))dz(i)
下面我们重点求
Λ
的估计公式。
首先将上式简化为:
∑i=1m∫z(i)Qi(z(i))logp(x(i)|z(i);μ,Λ,Ψ)p(z(i))Qi(z(i))dz(i)=∑i=1m∫z(i)Qi(z(i))[logp(x(i)|z(i);μ,Λ,Ψ)+logp(z(i))−logQi(z(i))]dz(i)=∑i=1mEz(i)∼Qi[logp(x(i)|z(i);μ,Λ,Ψ)+logp(z(i))−logQi(z(i))]























 1001
1001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









