







文章目录
1 环境配置
在 Idea 上创建 Maven Java 项目,并添加依赖:
<dependency>
<groupId>nz.ac.waikato.cms.weka</groupId>
<artifactId>weka-stable</artifactId>
<version>3.8.6</version>
</dependency>
<!-- 下面是 weka 测试代码程序包 -->
<dependency>
<groupId>nz.ac.waikato.cms.weka</groupId>
<artifactId>weka-stable</artifactId>
<version>3.8.6</version>
<classifier>tests</classifier>
</dependency>
2 数据模型
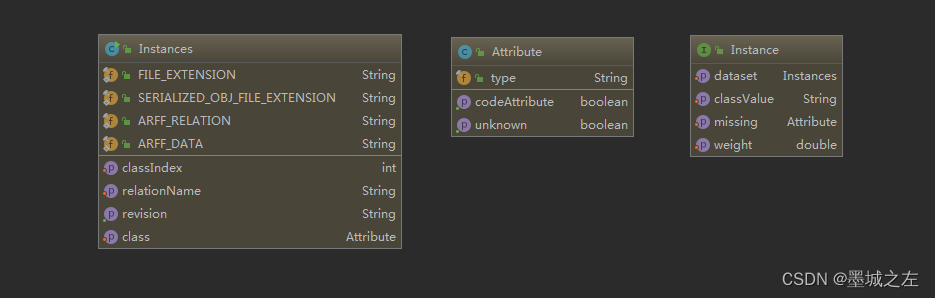
Instances 是数据集类,可类似理解为数据表,Attribute 类描述了数据集中的属性定义,Instance 表示数据集中的一个数据实例,可类比理解为数据表中的一行数据。
2.1 Instances:数据集
Instances 类用来存储一个完整的数据集信息,其内部是基于行的数据结构,可以通过调用 instance(int) 方法来获取一行的数据,可以通过 attribute(int) 方法获取一列数据。
import weka.core.converters.ConverterUtils.DataSource;
// Read all the instances in the file (ARFF, CSV, XRFF, ...)
DataSource source = new DataSource(filename);
Instances instances = source.getDataSet();
// Make the last attribute be the class
instances.setClassIndex(instances.numAttributes() - 1);
// Print header and instances.
System.out.println("\nDataset:\n");
System.out.println(instances);
2.2 Instance:数据实例
该类表示数据集中的一行,基本上是一个原始 double 数组的包装类。该类中不包含列的类型信息,可以通过访问关联的 Instances 数据集对象,来获取想要的信息。
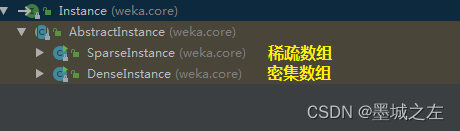
AbstractInstance 类直接派生 weka.core.DenseInstance 类和 weka.core.SparseInstance 类,这两个类提供了实例的基本功能。前者处理实例速度较快,是更为优雅的面向对象方法;后者只存储非零值,因而节省一些存储空间。在后文的示例中,大部分都使用DenseInstance类,很少使用SparseInstance类,但两者的处理非常相似。
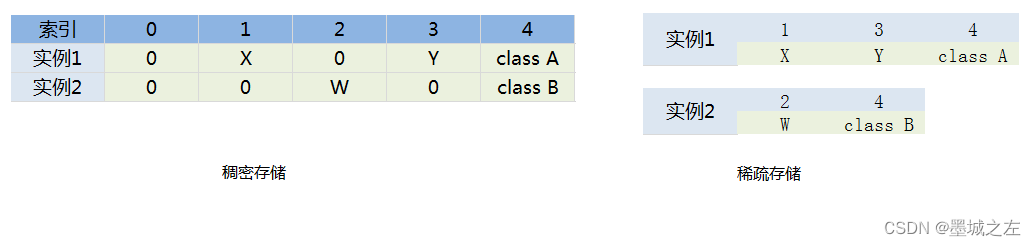
稠密数据在 arff 文件中如下:
@data
0, X, 0, Y, "class A"
0, 0, W, 0, "class B"
用稀疏格式表达的话,如下:
@data
{1 X, 3 Y, 4 "class A"}
{2 W, 4 "class B"}
每个实例用花括号括起来。实例中每一个非0的属性值用<index> <空格> <value>表示。<index>是属性的序号,从0开始计;<value>是属性值。属性值之间仍用逗号隔开。这里每个实例的数值必须按属性的顺序来写,如 {1 X, 3 Y, 4 "class A"} ,不能写成 {3 Y, 1 X, 4 "class A"}。注意在稀疏格式中没有注明的属性值不是缺失值,而是 0 值。若要表示缺失值必须显式的用问号表示出来。
实例中的所有值(数字、日期、标称值、字符串或关系型)都以浮点数的形式在内部存储,如果属性是标称(或字符串或关系),则存储的值是属性定义中相应标称(或字符串或关系)值的索引。这种实现方式在进行数据处理时,更优雅和高效。
// Create empty instance with three attribute values
Instance inst = new DenseInstance(3);
// Set instance's values for the attributes "length", "weight", and "position"
inst.setValue(length, 5.3);
inst.setValue(weight, 300);
inst.setValue(position, "first");
// Set instance's dataset to be the dataset "race"
inst.setDataset(race);
// Print the instance
System.out.println("The instance: " + inst);
当添加字符串属性值时,实际上添加到数据数组中的是字符串属性的索引,具体过程如下列代码所示:
// 添加字符串属性值;
public final void setValue(int attIndex, String value) {
int valIndex;
if (m_Dataset == null) { // m_Dataset 是该数据实例所在数据集的引用
throw new UnassignedDatasetException(
"Instance doesn't have access to a dataset!");
}
// 判断该属性的类型,是否为字符串型
if (!attribute(attIndex).isNominal() && !attribute(attIndex).isString()) {
throw new IllegalArgumentException(
"Attribute neither nominal nor string!");
}
// 判断值为 value 的属性是否已存在?
valIndex = attribute(attIndex).indexOfValue(value);
if (valIndex == -1) {
if (attribute(attIndex).isNominal()) {
throw new IllegalArgumentException(
"Value not defined for given nominal attribute!");
} else {
attribute(attIndex).forceAddValue(value); // 新建属性
valIndex = attribute(attIndex).indexOfValue(value);
}
}
setValue(attIndex, valIndex); // 实际添加的是属性值的索引!
}
2.3 Attribute:属性类
该类保存数据集中的属性的元信息,如属性的类型,以及标称型属性的标签、字符串属性的全部值,以及关系属性的数据集。
支持以下数据类型:
- numeric : 数值型,表示一个浮点数据;
- nominal : 标称型,可以理解为枚举型;
- string:字符串;
- date:日期型,实际保存的是其相应的浮点型时间戳值;
- relational:关系型,保存的是其他实例的引用。
示例:
// Create numeric attributes "length" and "weight"
Attribute length = new Attribute("length");
Attribute weight = new Attribute("weight");
// Create list to hold nominal values "first", "second", "third"
List my_nominal_values = new ArrayList(3);
my_nominal_values.add("first");
my_nominal_values.add("second");
my_nominal_values.add("third");
// Create nominal attribute "position"
Attribute position = new Attribute("position", my_nominal_values);
3 DataSource
Weka 支持多种格式的数据文件,比如 arff,csf,xrff 等,加载文件数据时,weka 会通过文件扩展名来推断文件内容的数据格式,然后选择合适的加载类。
可用的文件数据加载器放在 weka.core.converters 包中:
ConverterUtils 是一个工具类,其中定义了两个重要的内部类:DataSource, DataSink;DataSource 用于从文件中读取数据,DataSink 用于保存数据到文件。
Instances data1 = DataSource.read("/some/where/dataset.arff");
Instances data2 = DataSource.read("/some/where/dataset.csv");
Instances data3 = DataSource.read("/some/where/dataset.xrff");
// 也可以通过指定加载器的方式来加载文件:此时的文件扩展名,不受约束。
CSVLoader loader = new CSVLoader();
loader.setSource(new File("/some/where/some.data"));
Instances data = loader.getDataSet();
DataSource 是用于从文件和URL加载数据的帮助类。通过 ConverterUtils 类,它决定使用哪个转换器将数据加载到内存中。如果选择的转换器是增量转换器,则数据将以增量方式加载,否则将以批处理方式加载。在这两种情况下,将使用相同的接口(hasMoreElements,nextElement)。在再次读取数据之前,必须调用重置方法。
4 DataSink
所有的保存器(saver)都位于 weka.core.converters 包中,保存数据既可以让 Weka 选择合适的转换器,也可以指定显示转换器。
// 要保存的数据结构
Instances data = DataSource.read("/some/where/dataset.arff");
// 保存为ARFF
DataSink.write("/some/where/data.arff", data);
// 保存为CSV
DataSink.write("/some/where/data.csv", data);
// 保存为CSV
CSVSaver saver = new CSVSaver();
saver.setInstances(data);
saver.setFile(new File("/some/where/data.csv"));
saver.writeBatch();
5 数据集处理
5.1 创建数据集
创建数据集是指在内存中生成 Instances 对象,这个一个两阶段的过程:1, 通过设置属性定义数据格式;2,添加数据记录。其中数据定义可以理解为数据库操作中的 create table 操作,添加数据记录,可以理解为 insert 操作。
Weka目前有以下五种不同的属性类型。
- numeric(数值型):连续变量。
- date(日期型):日期变量。
- nominal(标称型):预定义的标签。
- string(字符串型):文本数据。
- relational(关系型):包含其他关系。例如,多个实例数据组成的包(bags)。
// 1. 数值型
Attribute numeric = new Attribute("numeric_test");
// 2. 日期型
Attribute date = new Attribute("date_test ", "yyyy-MM-dd");
// 3. 标称型
ArrayList<String> labels = new ArrayList<String>();
labels.add ("label_a");
labels.add ("label_b");
labels.add ("label_c");
labels.add ("label_d");
Attribute nominal = new Attribute("nominal_test", labels);
/**
* 4. 字符串型
*
* 与标称属性不同,字符串类型不需要存放预定义的标签列表。通常用于存储文本数据,即文本分类的文档内容。
* 字符串型使用与标称属性相同的构造函数,但需要提供一个null值,而非java.util.ArrayList<String>的实例。
*/
Attribute string = new Attribute("attribute_name", (ArrayList<String>)null);
5.2 添加数据
用户可以使用 DenseInstance 类的两种构造函数来实例化一个数据行,两种构造函数的功能如下。
- DenseInstance(double weight, double[] attValues):
该构造函数生成一个指定权重及给定 double 数组的 DenseInstance 对象。在 Weka 内部,全部五种属性类型都使用 double 格式。double格式表示数值型和日期型肯定没有问题,在Java内部,日期型也是用数值来表示的。对于标称型、字符串型和关系型属性,仅仅需要存放存储值的索引。
- DenseInstance(int numAttributes):
该构造函数生成一个新的、权重为1.0,全部值都缺失的DenseInstance对象。
double[] values = new double[data.numAttributes()]; // 创建示例数据
// 添加属性值;
values[0] = 1.23;
values[1] = data.attribute(1).parseDate("2013-05-11");
values[2] = data.attribute(2).indexOf("label_b");
values[3] = data.attribute(3).addStringValue("A string");
Instances dataRel = new Instances(data.attribute(4).relation(), 0); // 创建数据集
valuesRel = new double[dataRel.numAttributes()];
valuesRel[0] = 2.34;
valuesRel[1] = dataRel.attribute(1).indexOf("val_C");
dataRel.add(new DenseInstance(1.0, valuesRel));
values[4] = data.attribute(4).addRelation(dataRel);
Instance inst = new DenseInstance(1.0, values); // 创建数据实例
data.add(inst); // 将实例添加到数据集
创建 Instances 的完整示例:
private Instances relationInstances() {
ArrayList<Attribute> attrRelation = new ArrayList<>();
// -- 关系属性 1:数值型
attrRelation.add(new Attribute("att5.1"));
// -- 关系属性 2:标称型
ArrayList<String> attValsRel = new ArrayList<>();
for (int i = 0; i < 5; i++){
attValsRel.add("val5." + (i + 1));
}
attrRelation.add(new Attribute("att5.2", attValsRel));
return new Instances("att5", attrRelation, 0);
}
@Test
public void printInstancesTest() throws Throwable {
// 属性定义
ArrayList<Attribute> attributes = new ArrayList<>();
// - 属性1:数值型
attributes.add(new Attribute("att1"));
// - 属性2:标称型
ArrayList<String> attrTags = new ArrayList<>(); // 为标称值创建标签
for (int i = 0; i < 5; i++){
attrTags.add("val" + (i + 1));
}
attributes.add(new Attribute("att2", attrTags));
// - 属性3:字符串型
attributes.add(new Attribute("att3", (ArrayList<String>) null));
// - 属性4:日期型
attributes.add(new Attribute("att4", "yyyy-MM-dd"));
// - 属性5:关系型
attributes.add(new Attribute("att5", relationInstances(), 0));
Instances data = new Instances("MyRelation", attributes, 0);
// 3. 添加数据
// 第一个实例
Instances dataRel = new Instances(data.attribute(4).relation(), 0);
// -- 第一个实例
dataRel.add(new DenseInstance(1.0, new double[]{
Math.PI + 1,
dataRel.attribute(1).indexOfValue("val5.3")
}));
// -- 第二个实例
dataRel.add(new DenseInstance(1.0, new double[]{
Math.PI + 2,
dataRel.attribute(1).indexOfValue("val5.2")
}));
// 添加实例1
// 2. 创建Instances对象
data.add(new DenseInstance(1.0, new double[]{
Math.PI, // - 数值型
attrTags.indexOf("val3"), // - 标称型
data.attribute(2).addStringValue("A string."), // - 字符串型
data.attribute(3).parseDate("2013-04-05"), // - 日期型
data.attribute(4).addRelation(dataRel) // 关系型
}));
// 4. 输出数据
System.out.println(data);
}
输出的数据集:
@relation MyRelation
@attribute att1 numeric
@attribute att2 {val1,val2,val3,val4,val5}
@attribute att3 string
@attribute att4 date yyyy-MM-dd
@attribute att5 relational
@attribute att5.1 numeric
@attribute att5.2 {val5.1,val5.2,val5.3,val5.4,val5.5}
@end att5
@data
3.141593,val3,'A string.',2013-04-05,'4.141593,val5.3\n5.141593,val5.2'
6 过滤
在 Weka 中,使用过滤器进行数据预处理。
在 weka.filters 包下可以找到这些过滤器,过滤器分为有监督过滤器和无监督过滤器两类。前者需要设置一个类别属性,后者不需要;过滤器还可以分为基于属性和基于实例两个子类,前者针对列的处理,例如,添加或删除列;后者针对行的处理,例如,添加或删除行。
除此之外,过滤器还可以分为流式过滤器或批处理过滤器。
String[] options = new String[2];
options[0] = "-R"; // 范围
options[1] = "1"; // 第一个属性
Remove remove = new Remove(); // 构建过滤器实例
remove.setOptions(options); // 设置选项
remove.setInputFormat(data); // 设置输入格式,一定要在 setOptions 后面;
Instances newData = Filter.useFilter(data, remove); // 应用过滤器
批量过滤器可以同时处理多个数据集。
7 分类
在 Weka 中,分类和回归算法都称为“分类器”,位于 weka.classifier 包下。
所有的 Weka 分类器都设计为可批量训练的,即分类器对整个数据集一次就能训练好;还有一些算法可以随时随机地更新自己的内部模型,称为增量分类器。
批量分类器的构建非常简单:
- 设置选项;
- 进行训练;
import weka.classifiers.trees.J48;
import weka.core.Instances;
import weka.core.converters.ArffLoader;
import java.io.File;
/**
* 批量方式构建J48分类器,并输出决策树模型
*/
public class BatchClassifier {
public static void main(String[] args) throws Exception {
// 加载数据
ArffLoader loader = new ArffLoader();
loader.setFile(new File("C:/Weka-3-7/data/weather.nominal.arff"));
Instances data = loader.getDataSet();
data.setClassIndex(data.numAttributes() - 1);
// 训练J48分类器
String[] options = new String[1];
options[0] = "-U"; // 未裁剪树选项
J48 tree = new J48(); // J48分类器对象
tree.setOptions(options); // 设置选项
tree.buildClassifier(data); // 构建分类器
// 输出生成模型
System.out.println(tree);
}
}
Evaluation 分类评估器,用于评估分类的性能,Weka 支持两种类型的评估,1,交叉验证,2,专用测试集验证。
Evaluation 中的常见方法:
| 方法名 | 说明 |
|---|---|
| toSummaryString() | 以摘要的形式输出性能统计数据,第一个参数为摘要标题,第二个参数为是否打印复杂的性能统计数据; |
| toMatrixString() | 输出混淆矩阵; |
| toClassDetailsString() | 输出TP / FP率、查准率、查全率、F-度量、AUC(每个类别); |
| toCumulativeMarginDistributionString() | 输出累计边距分布; |
| correct() | 正确分类的实例数量,不正确分类的实例数量可调用 incorrect() 方法得到; |
| pctCorrect() | 正确分类的实例的百分比(查准率)。pctIncorrect() 返回错误分类的实例的百分比; |
| areaUnderROC(int) | 指定的类别标签索引(基于0的索引)的AUC; |
| correlationCoefficient() | 相关系数 |
| meanAbsoluteError() | 平均绝对误差 |
| rootMeanSquaredError() | 均方根误差 |
| numInstances() | 类别值的实例数量 |
| unclassified() | 未分类的实例数量 |
| pctUnclassified() | 未分类的实例的百分比 |
8 聚类
聚类是一种在数据中发现模式的无监督机器学习技术,也就是说,这些算法没有类别属性,这与分类不同,分类算法需要有一个类别属性,是有监督的机器学习算法。
执行聚类算法的步骤:
- 构建聚类器;
- 评估:对构建的聚类器进行评估;
- 执行聚类:对未知的实例进行聚类;
Instances train = DataSource.read("C:/Weka-3-7/data/segment-challenge.arff");
Instances test = DataSource.read("C:/Weka-3-7/data/segment-test.arff");
String[] options = new String[2];
options[0] = "-I"; // 最大迭代次数
options[1] = "100";
EM clusterer = new EM(); // 聚类器的新实例
clusterer.setOptions(options); // 设置选项
clusterer.buildClusterer(train); // 构建聚类器
// 评估
ClusterEvaluation eval = new ClusterEvaluation();
eval.setClusterer(cl);
eval.evaluateClusterer(new Instances(train));
System.out.println(eval.clusterResultsToString());
// 执行聚类
for (int i = 0; i < test.numInstances(); i++) {
int cluster = clusterer.clusterInstance(test.instance(i));
double[] dist = clusterer.distributionForInstance(test.instance(i));
System.out.print((i + 1));
System.out.print(" - ");
System.out.print(cluster);
System.out.print(" - ");
System.out.print(Utils.arrayToString(dist));
System.out.println();
}
聚类器评估不像分类器评估那样容易做得很全面,由于聚类是无监督的,因此很难确定一个模型的性能到底有多好。 Weka 用于评估聚类算法的是 weka.clusters 包的 ClusterEvaluation 类。

















 744
744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









