







1. 前言
bigworld 的 load balance 算法的大致思路是知道的,即 动态区域分割 + 动态边界调整。但具体是怎么实现的,不清楚,网上也不找到相关的文章介绍,所以只能自己看代码进行分析。
本文大致记录我所分析到的算法实现,基于 bigworld 的这个开源版本:2014 BigWorld Open-Source Edition Code,更具体的信息可在我另一篇文章找到 《游戏服务器研究一:bigworld 开源代码的编译与运行》 。
本文应该会持续更新,因为算法有很多细节,看得越多,了解越多。而这些细节对于这类算法是很重要的,属于生产实践上的微调,离开这些微调,load balance 可能工作得不如预期,甚至在一些边角的情况下,可能会表现得特别差。
如有错误,欢迎指出。
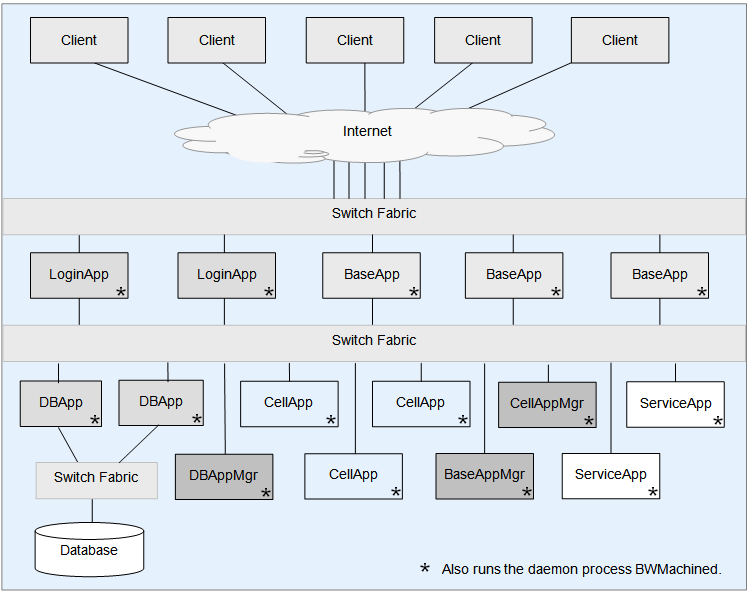
2. bigworld 服务器架构
与 load balance 相关的服务器是 cellapp 和 cellappmgr,其中 cellapp 可以有很多个,而 cellappmgr 全局只有一个。
3. load balance 基本算法
一张地图,bigworld 用一个 Space 类来表示,根据负载情况,动态分割成 n 个 区域(cell),这些 cell 的面积不是固定的,会根据地图上的实体(entity)的 cpu 使用率(cpu load)的分布情况来动态调整。
Space 以及 cell 相关的分割信息,由全局唯一的 cellappmgr 服务器管理。具体的 cell 运行在 cellapp 服务器上,整个集群会有多个 cellapp。
一个 space 可能会分割成多个 cell,但是在同一个 cellapp 上,只能运行这个 space 的一个 cell(否则负载均衡就没有意义了)。所以,一个 space 分割成 n 个 cell,就需要有 n 个 cellapp 来运行这些 cell。
bigworld 的 load balance 基本算法是 动态区域分割 + 动态边界调整。
动态区域分割:space 所使用的一组 cellapp 的平均 cpu load 已经超过阈值,无法通过改变 cell 的边界来减轻负载,只能通过增加 cell 的个数解决。
动态边界调整:当前 cell 个数不变,通过改变各个 cell 的管辖范围,即移动 cell 之间的边界,来使得 cell 之间的 cpu load 处于阈值之内,且相对平衡。
3.1 算法过程
下面大致描述一种可能的分割情况。
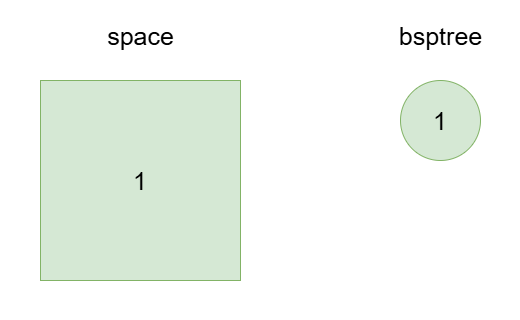
1、一开始的时候,一个 Space 只包含一个 cell,这个 cell 占据了整个 space 的面积。
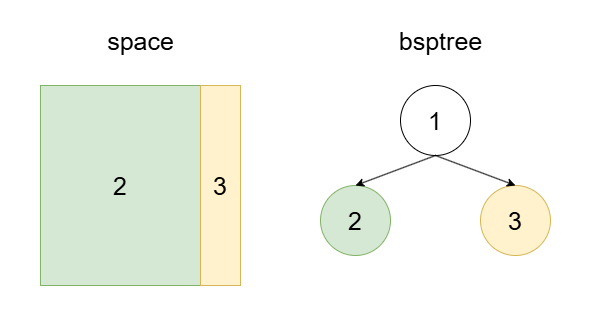
2、当一个 space 所使用的一组 cellapp 的平均负载超过阈值时,cellappmgr 会决定增加一个 cell,并把这个 cell 放到组外的 cellapp 上运行,以此分担压力。
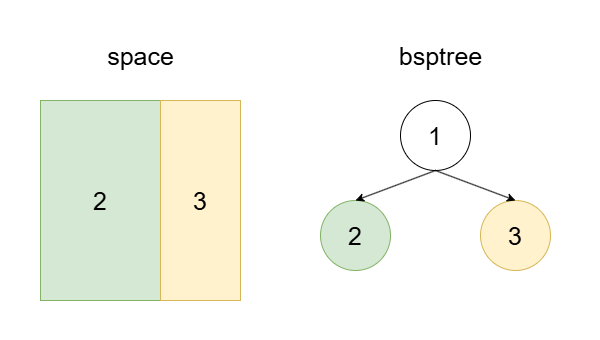
3、如果可以通过调整边界来使得各个 cell 的负载在阈值之内,并且负载相差最小,则直接调整边界。
值得指出的是,上面第 2 步中,新增的 cell3,一开始它的面积是 0,在动态的调整中,会慢慢增加它的占用面积,直到它上面运行的 entity 的负载之和与 cell2 相当。这个过程不是一步到位的,这样做的好处是整个过程变得很平滑,不会一下子需要从 cell2 迁移大量的 entity 到 cell3 上面。
4、如果调整边界仍然无法解决负载过高的问题,则继续增加 cell,但 cell 是采取 geometric tessellation(几何镶嵌)的方式分割的,横向(Horizontal)与纵向(Vertical)交织着分割。
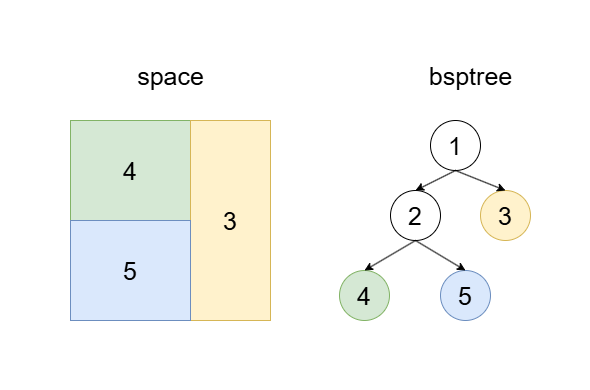
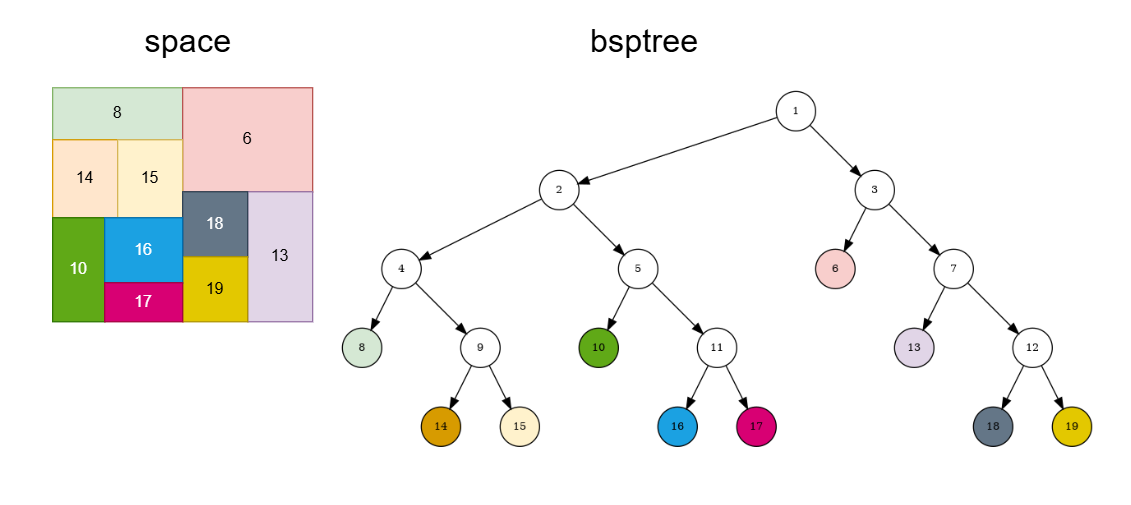
5、依上述方法,经过多次分割后,可能演变成如下。
4. load balance 代码分析
bigworld 的代码质量很高,模块划分比较清晰。但是如果不了解一些核心概念,那么看 load balance 相关的代码就会很吃力。我也是硬看了一段时间,才理清大致的脉络。
下面的分析不会按照小白的方式,进行有条有理的叙述,只会写一些对于理解整个算法最关键的要点,具体逻辑要自己看代码。
4.1 cell
cell 是平面的,尽管地图是 3d 的,但 cell 只取平面的信息。
4.2 bsptree 的概念
bsptree 即 Binary Space Partioning Tree,实际上这里并不需要深入理解这种 tree,把它当成一棵二叉树即可,不会影响对整个算法的理解。
4.3 bsptree 相关的数据结构
在 cellappmgr 目录下:
| 类名 | 说明 | 文件 |
|---|---|---|
| BSPNode | bsp节点基类 | bsp_node.cpp |
| CellData | bsp叶子节点类,继承自BSPNode | cell_data.cpp |
| InternalNode | bsp中间节点类,继承自BSPNode | internal_node.cpp |
4.4 bsptree 的构造过程
以下讨论的都是 cellappmgr 目录下的类。
1、数据结构
bsptree 的根结点保存在 Space 类中,即 CM::BSPNode * pRoot_。
2、根结点的初始化
根结点的初始化很容易找到,它的调用链路是:
CellAppMgr::createEntityInNewSpace
-> Space::addCell()
-> Space::addCell( CellApp & cellApp, CellData * pCellToSplit )
强调一下,此时创建出来的 pRoot_ 是 CellData 类型的(即 bsptree 的叶子节点类型)。它需要等到第一次分裂之后,才会变成 InternalNode 类型(即 bsptree 的中间节点类型)。
3、根节点的第一次分裂
这是隐藏得很深的,我找了挺久才捋清楚。
它的调用链路是:
CellAppMgr::metaLoadBalance()
-> CellAppGroups::checkForOverloaded( float addCellThreshold )
-> overloadedGroups.addCells();
-> CellAppGroup::addCell()
-> Space::addCell()
-> Space::addCell( CellApp & cellApp, CellData * pCellToSplit )
到此为止,看看 Space::addCell( CellApp & cellApp, CellData * pCellToSplit ) 的内部,此时传递的参数 pCellToSplit 是 null 的。
里面执行到这句的时候 pRoot_ = (pRoot_ ? pRoot_->addCell( pCellData ) : pCellData); ,由于 pRoot_ 此前已经初始化过,所以非空,那么就会执行 pRoot_->addCell( pCellData ),也就是调用 CellData::addCell( CellData * pCell, bool isHorizontal ),这里面就产生了分裂。
经过这次分裂,pRoot_ 正式变为 InternalNode 类型。
4.5 cpu 负载(cpu load)的计算
负载不是简单的使用 entity 的数量来衡量的,而是精细到每个 entity 的 cpu load。每个 entity 上面都有一个 profiler,在涉及到具体的 entity 处理的地方,基本上都调用这个 profiler 进入 profiling。
以下讨论的是 cellapp 目录下的类。
几个关键点
1、Entity 上挂着的 profiler 是 EntityProfiler profiler_;。
2、与 EntityProfiler 关系密切的是这个 AutoScopedHelper 类,它是个简单的类,利用 RAII 机制来调用 profiler;会在构造函数里调用 pEntity->profiler().start();,在析构函数里调用 pEntity_->profiler().stop();。
3、AUTO_SCOPED_ENTITY_PROFILE 和 AUTO_SCOPED_THIS_ENTITY_PROFILE 这两个宏是对 AutoScopedHelper 的封装,使用这两个宏的地方都是对 entity 进行 profiling 的地方,在代码中搜索一下,可以发现一大堆。
4、每个 gametick,都会调用 EntityProfiler::tick 以重新计算每个 entity 的 cpu load,调用链路是:
CellApp::handleGameTickTimeSlice()
-> CellApp::updateLoad()
-> CellApp::tickProfilers( uint64 lastTickInStamps )
-> Cells::tickProfilers( uint64 tickDtInStamps, float smoothingFactor )
-> Cell::tickProfilers( uint64 tickDtInStamps, float smoothingFactor )
4.6 动态边界调整
动态边界调整的目标是使得 bsptree 的左右子树的 cpu load 处于相对平衡的状态,让两棵子树的 cpu load 之差尽可能达到最小。它是自上而下调整的,一级级都做调整。
以下讨论的都是 cellappmgr 目录下的类。
调用链是:
CellAppMgr::handleTimeout( TimerHandle /*handle*/, void * arg )
-> CellAppMgr::loadBalance()
-> Space::loadBalance()
进入 Space::loadBalance() 之后,就要看 pRoot_ 的状态了。
如果当前 pRoot_ 是 CellData 类型的,则调用的是 CellData::balance,没什么特别的事情好做的。
如果当前 pRoot_ 是 InternalNode 类,则调用的是 InternalNode::balance,这里面就比较复杂了,会自顶向下的尝试对各个层级的边界进行调整。
4.7 动态区域分割
动态区域分割的原因是,space 所使用的一组 cellapp 的平均 cpu load 已经超过阈值,无法通过改变 cell 的边界来减轻负载,只能通过增加 cell 的个数解决。
以下讨论的都是 cellappmgr 目录下的类。
调用链是:
CellAppMgr::handleTimeout( TimerHandle /*handle*/, void * arg )
-> CellAppMgr::metaLoadBalance()
-> CellAppGroups::checkForOverloaded( float addCellThreshold )
CellAppGroups 以及 checkForOverloaded 的逻辑都比较直,容易分析,这里就不细说了。
4.8 EntityBoundLevels 的作用是什么?
这一小段会有点长,要解释清楚这个概念并不容易。
概念解释
在 BSPNode 里面有个成员变量 EntityBoundLevels entityBoundLevels_;。
最开始看这个的时候很费解,搞不懂它的作用,但它在 loadbalance 的时候会被使用,是个很重要的变量。后面仔细研究,终于搞懂了。
它实际上就是对于一个 cell 上的 entity 的 cpu load 分布情况的一个刻画,而且是从横向(左->右,右->左),纵向(上->下,下->上)总 4 个方向都进行了刻画。因为相邻 cell 的边界调整可以是向左或向右,向上或向下的,需要准备好这 4 个方向的数据,提供算法决策的依据。
举个例子,两个挨在一起的 cell:cell1 和 cell2,在执行 loadbalance 的时候,它们的 cpu load 分别是 load1 和 load2,load1 小于 load2。
那么这时候要怎么移动边界,让 cell1 和 cell2 的 cpu load 接近相等呢?答案是向右移动。
但要移动多少呢?这时候就需要 cell2 从左到右的 cpu load 的分布情况,而这就刚好是 cell2 的 entityBoundLevels_ 变量保存的信息。它并不是一个完整的信息,而是一个压缩后的信息,只记录了 5 个 level 的 cpu load 分布,注意,level 越大 cpu load 值越小。
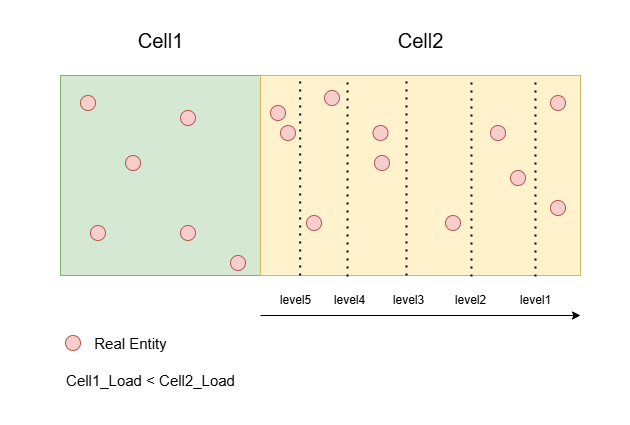
举个例子,如果 diff = (load2-load1)/2,而 diff >= entityBoundLevels_[左到右][level5] 且 diff < entityBoundLevels_[左到右][level4],那么把边界移动到 level5 对应的线就行了,这里只是尽量做到负载平衡,而不是百分百平衡。
代码说明
1、cellapp 端
向 cellappmgr 发送 EntityBoundLevels 等数据,调用链是:
CellApp::handleGameTickTimeSlice()
-> CellApp::updateBoundary()
-> CellAppMgrGateway::updateBounds( const Cells & cells )
-> Cells::writeBounds( BinaryOStream & stream )
-> Cell::writeBounds( BinaryOStream & stream )
-> Space::writeBounds( BinaryOStream & stream )
-> Space::writeEntityBounds( BinaryOStream & stream )
最后就是在 Space::writeEntityBounds 里面,把 cell 4 个方向的 entity cpu load 信息都写入了。
void Space::writeEntityBounds( BinaryOStream & stream ) const
{
// This needs to match CellAppMgr's CellData::updateEntityBounds
// Args are isMax and isY
this->writeEntityBoundsForEdge( stream, false, false ); // Left
this->writeEntityBoundsForEdge( stream, false, true ); // Bottom
this->writeEntityBoundsForEdge( stream, true, false ); // Right
this->writeEntityBoundsForEdge( stream, true, true ); // Top
}
2、cellappmgr 端
接收 cellapp 发上来的 update 数据,接收逻辑是:
CellApp::updateBounds( BinaryIStream & data )
这个其实被定义在 cellappmgr_interface.hpp 里面的。
BW_STREAM_MSG( CellApp, updateBounds );
3、细究 writeEntityBoundsForEdge
为何这个函数能方便的从4个方向统计 entity 的 cpu load 分布呢?因为 bigworld 使用了十字链表法来实现 aoi。
这样一来,只要从左到右或从右到左扫描 x 轴,就可以得到横向的分布信息;从上到下或从下往上扫描 y 轴,就可以得到纵向的分布信息。
4.9 chunkBounds_ 的作用是什么?
在 BSPNode 里面有个成员变量 BW::Rect chunkBounds_;。
它表示自己所在的 cellapp 上,自己对应的 space 已经加载的地图的边界范围,通过把自己的 range_ 与 chunkBounds_ 取交集,就可以判断自己所在的区域是否已经完成地图数据的加载的,这也就是 CellData::calculateAreaNotLoaded() 所做的事情。
4.10 smooth 的意义
有很多变量前都加了 smooth 作为前缀,比如 smoothedLoad_,它的意义就是数学上说的“平滑”。
比如下面这个函数里面计算 smoothedLoad_,就是使用了指数平滑法,其中 bias 就是指数平滑法用的参数。平滑的作用就是让变量不会抖动的太厉害,相对平缓一些。
void CellApp::informOfLoad( const CellAppMgrInterface::informOfLoadArgs & args )
{
lastReceivedLoad_ = args.load;
float addedArtificialLoad = 0.f;
for (Cells::const_iterator it = cells_.begin();
it != cells_.end();
++it)
{
addedArtificialLoad +=
(*it)->space().artificialMinLoadCellShare( lastReceivedLoad_ );
}
currLoad_ = lastReceivedLoad_ + addedArtificialLoad;
float bias = CellAppMgrConfig::loadSmoothingBias();
smoothedLoad_ = ((1.f - bias) * smoothedLoad_) + (bias * currLoad_);
estimatedLoad_ = smoothedLoad_;
numEntities_ = args.numEntities;
}
指数平滑法的计算公式为:
S t = a Y t + ( 1 − a ) S t − 1 S_{t} = aY_{t}+(1−a)S_{t−1} St=aYt+(1−a)St−1
S
t
S_t
St 是时间 t 的平滑值
Y
t
Y_t
Yt 是时间 t 的实际值
S
t
−
1
S_{t−1}
St−1 是时间 t-1 的平滑值
a 是平滑常数,取值范围 [0,1]
5. 一些问题
5.1 cellapp 是怎么找到 cellappmgr 的
通过本机的 bwmachined2 这个进程查询得到 cellappmgr 的地址,然后向 cellappmgr 注册。
5.2 cellapp 上面 entity 的消息是怎么处理的
1、消息是收到立即处理的,但如果下一帧即将到来( app.nextTickPending() ),则不能因为处理这个消息导致下一帧被延迟执行,所以需要先把消息先放到 cellapp 的 buffered 队列中: bufferedEntityMessages,bufferedInputMessages。
2、这些 buffered 队列里的消息,会在下一帧开头的函数 CellApp::handleGameTickTimeSlice() 中被处理,即
this->bufferedEntityMessages().playBufferedMessages( *this );
this->bufferedInputMessages().playBufferedMessages( *this );
6. 总结
bigworld 的整个 load balance 算法实现是比较精细的,但在分布式环境下,如何保证这套算法的稳健运行,还需要再深入研究,亲自动手实验一下。
7. 参考
[1] bigworld. BigWorld Technology Server Whitepaper. https://sourceforge.net/p/bigworld/code/HEAD/tree/trunk/docs/pdf/BigWorld%20Technology%20Server%20Whitepaper.pdf.
系列文章:















 936
936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









