






本篇介绍为了保证Hadoop集群平稳地执行。须要深入掌握的知识。以及一些管理监控的手段,日常维护的工作。
HDFS
永久性数据结构
对于管理员来说。深入了解namenode,辅助namecode和datanode等HDFS组件怎样在磁盘上组织永久性数据很重要。
洞悉各文件的使用方法有助于进行故障诊断和故障检出。
namenode的文件夹结构
namenode被格式化后,将在${dfs.namenode.name.dir}/current 文件夹下。产生例如以下的文件夹结构:VERSION、edits、fsimage、fstime。
仅仅有深入学习namenode的工作原理。才干理解这些文件的用途。对于Hadoop集群管理员来说。这是有必要的。
辅助namenode的文件夹结构
在大型集群中,辅助namenode须要执行在一台专用机器上。保持和namenode基本一致的文件夹结构和数据。在主namenode发生问题时。能够从辅助namenode恢复数据。
datanode的文件夹结构
datanode不是格式化时创建的,而是启动时自己主动创建的。datanode的重要文件和文件夹例如以下所看到的:
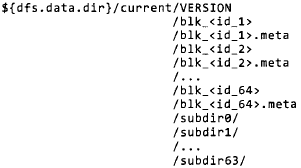
dfs.data.dir 是在hadoop1.X中定义的,在Hadoop2.X中是在hdfs-site.xml中定义的 fs.datanode.data.dir 。
安全模式
namenode启动时,首先将映像文件(fsimage)加载内存。并运行编辑日志(edits)中的各项操作。
一系列操作之后,假设满足“最小复本条件”,namenode会在30秒内退出安全模式。所谓的最新复本调价指的是在整个文件系统中有99.9%的块满足最小复本条件(默认值时1,由dfs.replication.min属性设置)。
在启动一个刚刚格式化的HDFS集群时。由于系统中还没有不论什么块,所以namenode不会进入安全模式。
安全模式的属性设置例如以下:

安全模式操作命令:
hadoop dfsadmin -safemode get
hadoop dfsadmin -safemode wait
hadoop dfsadmin -safemode leave
hadoop dfsadmin -safemode enter
调整日志级别
log4j.logger.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=WARN
调整为INFO或者其它。
工具
dfsadmin工具

fsck工具
Hadoop提供fsck工具来检查HDFS中文件的健康状况。该工具会查找那些全部datanode中均缺失的块以及过少或过多复制的块。
使用命令:
hadoop fsck /
hadoop fsck / -move
hadoop fsck / -delete
datanode块扫描器
各个datanode执行一个快扫描器。定期检測本节点上的全部块。从而在client读到坏块之前及时地检測和修复坏块。能够依靠DataBlockScanner所维护的块列表依次扫描块,查看是否存在校验和错误。
扫描器还使用节流机制,来维持datanode的磁盘带宽(换句话说,块扫描器工作时仅占用一小部分磁盘带宽)。
默认情况下。块扫描器每隔三周(504小时)就会检測块,以应对可能的磁盘故障,这个周期由dfs.datanode.scan.period.hours属性设置。损坏的块被报给namenode,并被即时修复。
訪问网页:http://datanode:50075/blockScannerReport 获取该datanode的块检測报告。
加 ?Listblocks 參数会在报告中列出该datanode上全部的块及其最新验证状态。
均衡器
均衡器(balancer)程序是一个Hadoop守护进程,它将块从忙碌的datanode移到相对空暇的datanode。从而又一次分配块。同一时候坚持块复本放置策略,将复本分散到不同机架。以减少数据损坏率。
操作一直运行,直到均衡,即每一个datanode的使用率(该节点上已使用的空间和空间容量之间的比率)和集群的使用率(集群中已使用的空间与集群的空间容量之间的比率)很接近,差距不超过给定的阀值。
启动均衡器指令:start-blancer.sh ,-threshold參数指定阀值(百分比格式),默认10%。在不论什么时刻,集群中都仅仅执行一个均衡器。
在不同节点之间复制数据的带宽也是受限的。默认是1MB/s。能够通过hdfs-site.xml中的dfs.balance.bandwidthPerSec属性指定(单位是字节)。
监控
监控是系统管理的重要内容。监控的目标在于检測集群在何时未提供所期望的服务。
主守护进程是最须要监控的,包含主namenode、辅助namenode和jobtracker。
datanode和tasktracker常常出现问题;在大型集群中。故障率尤其高。
因此,集群须要保留额外的容量,如此一来,即使有一小部分节点宕机,也不影响整个系统的运作。
管理员也能够定期执行一些測试作业。以检查集群的健康状况。
日志
全部Hadoop守护进程都会产生日志文件。这些文件很有助于查明系统中发生的事件。
默认情况下。Hadoop生成的系统日志文件存放在$HADOOP_INSTALL/logs文件夹之中,也能够通过hadoop-env.sh文件里的HADOOP_LOG_DIR来进行改动。通常能够把日志文件存放在/var/log/hadoop文件夹中。实现的办法就是在hadoop-env.sh中增加一行:export HADOOP_LOG_DIR=/var/log/hadoop ,假设日志文件夹不存在,则会首先创建该文件夹,假设创建失败。请检查hadoop用户是否有权创建该文件夹。
设置日志级别
故障排查过程中,暂时设置日志级别很故意,有两种方法,网页和命令行。比如要对某台机器的JobTracker设置为DEBUG级别,能够例如以下:
a、訪问http://jobtracker-host:50030/logLevel,将org.apache.hadoop.mapred.JobTracker属性设置为DEBUG级别
b、hadoop daemonlog -setlevel jobtracker-host:50030 org.apache.hadoop.mapred.JobTracker DEBUG
获取堆栈轨迹
Hadoop守护进程提供一个网页,对正在守护进程的JVM中执行着的线程执行线程转储(Thread-dump)。
比如:http://jobtracker-host:50030/stacks获取jobtracker的线程转储。
度量
HDFS和MapReduce守护进程收集的事件和度量相关的信息,这些信息统称为度量(metric)。
比如,各个datanode会收集例如以下度量(还有很多其它):写入的字节、块的复本数、client发起的读操作请求数。
度量从属于特定的上下文,眼下,Hadoop使用dfs、mapred、rpc、jvm 这4个上下文。
度量在conf/hadoop-metrics.properties文件里配置。默认情况下,全部上下文都被配置成不公布度量。
经常使用的度量类:FileContext、GangliaContext、NullContextWithUpdateThread、CompositeContext。

java管理扩展(JMX)
JMX是一个标准的JAVA API,可监控和管理应用。
Hadop包含多个托管bean(MBean)。能够将Hadoop度量公布给支持JMX的应用。例如以下:

JDK自带的JConsole工具能够浏览JVM中MBean。很多第三方的监控和报警系统(如Nagios和Hyperic)均可查询MBean,因此通过这些系统使用JMX监控一个Hadoop集群就非常寻常,前提是启用远程訪问JMX功能和合理设置集群的安全级别,包含password认证、SSL连接和SSLclient认证等。
比較普遍的方案是,同一时候使用Ganglia和Nagios这种警告系统来监控Hadoop系统。Ganglia擅长高效地收集大量度量,并以图形化界面呈现;Nagios和类似系统擅长在某项度量的关键阀值被突破之后及时报警。
维护和升级
关于这部分。暂时先不深入学习,在工作过程中如有涉猎,再返回此处进一步记录。















 1602
1602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









