






Word Embedding是什么?
人类一直擅长理解语言。 人类很容易理解单词之间的关系,但对于计算机来说,这项任务可能不简单。 例如,我们人类理解国王和王后,男人和女人,老虎和老虎之间有某种类型的关系,但计算机怎么能弄清楚这一点呢?
word embedding基本上是一种词表示形式,它将人类对语言的理解与机器的理解联系起来。 他们已经学习了文本在n维空间中的表示,其中具有相同含义的单词具有相似的表示。 这意味着两个相似的词由几乎相似的向量表示,它们非常紧密地放置在向量空间中。 这些对于解决大多数自然语言处理问题是必不可少的。
因此,当使用word embeddings时,在预定义的向量空间中,所有单个单词都表示为实值向量。 每个单词被映射到一个向量,向量值的学习方式类似于神经网络。
Word2Vec是利用浅层神经网络学习word embeddings的最流行技术之一。 它是TomasMikolov2013年在谷歌开发的。
为什么使用Word Embedding?
正如我们所知,机器学习模型不能处理文本,因此我们需要找到一种将这些文本数据转换为数字数据的方法。 以前的技术,如Bag of Words和TF-IDF已经讨论过,可以帮助实现使用这个任务。 除此之外,我们还可以使用两种技术,如one-hot encoding,或者我们可以使用unique numbers来表示词汇中的单词。 后一种方法比one-hot encoding更有效,因为我们现在有了一个密集的向量,而不是稀疏向量。 因此,这种方法甚至在我们的词汇量很大的时候也能起作用。
在下面的例子中,我们假设我们有一个小词汇,只包含四个单词,使用两种技巧来表示句子“Come sit down’。
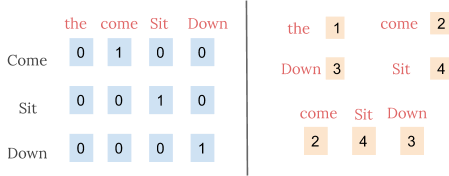
然而,integer encoding是随意的,因为它不捕获单词之间的任何关系。 对于一个模型来说,解释它是很有挑战性的,例如,线性分类器需要为每个特征学习单个权重。 由于任何两个词的相似性与其编码的相似性之间没有关系,所以这种特征权重组合是没有意义的。
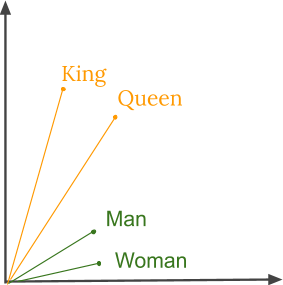
因此,通过使用word embedding,意义上接近的单词在向量空间中彼此靠近。 例如,当代表一个词,如frog,frog的最近邻居将是frogs,toads, Litoria。 这意味着分类器在训练过程中没有看到Litoria这个词,只有青蛙这个词是可以的,当它在测试过程中看到Litoria时,分类器不会被抛弃,因为两个单词向量是相似的。 此外,word embedding也会学习关系。 一对单词之间的向量差异可以添加到另一个单词向量中,以找到类似的单词。 例如,"man"-"woman"+"queen"≈"king"。
word2vec是什么?
word2vec是一种利用两层神经网络高效创建word embedding的方法。 它是由Google的TomasMikolov等人于2013年提出的。这使得基于神经网络的嵌入训练更有效,并自那时以来,word2vec已经成为了研究预训练的word embedding的事实标准。
word2vec的输入是一个文本语料库,它的输出是一组向量,称为特征向量,表示该语料库中的单词。 虽然word2vec不是深度神经网络,但它将文本转化为深度神经网络可以理解的数值形式。
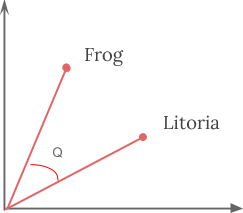
word2Vec目标函数导致具有相似上下文的单词具有相似的embeddings。 因此,在这个向量空间中,这些单词非常接近。 从数学上讲,这些向量之间的角度(Q)的余弦应该接近1,即角度接近0。
word2vec不是一个单一的算法,而是两种技术的结合------CBOW(Continuous bag of words)和Skip-gram模型。 这两个都是浅层神经网络,它将单词映射到目标变量,也是一个单词。 这两种技术都学习作为词向量表示的权重。
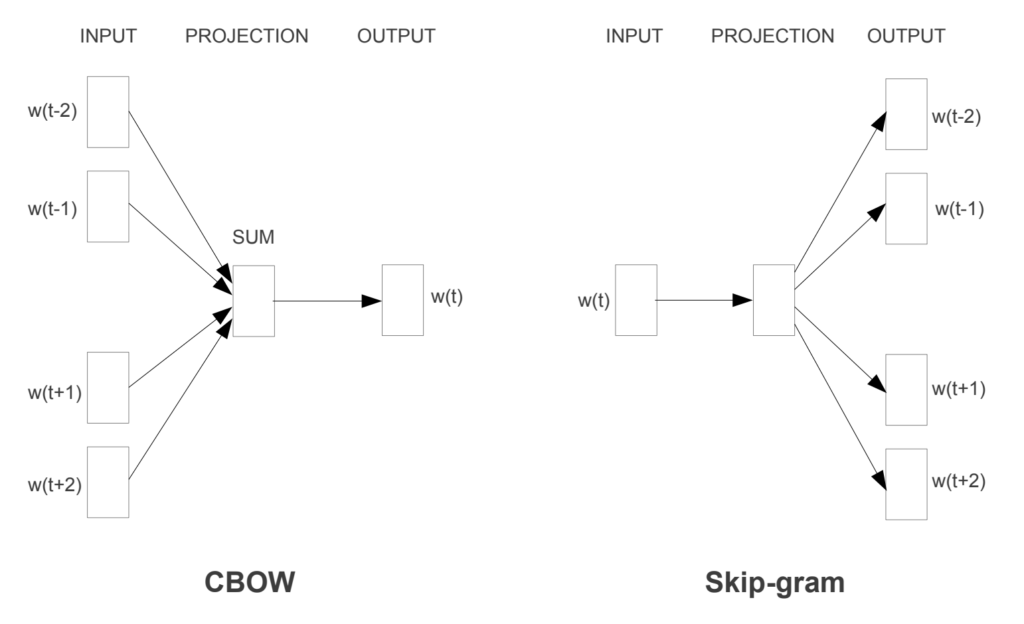
Continuous Bag-of-Words model (CBOW)
CBOW预测了一个单词发生的概率,给出了它周围的单词。 我们可以考虑一个单词或一组单词。 但为了简单起见,我们将使用单个上下文词并尝试预测单个目标词。
英语包含了近120万个单词,使得在我们的例子中不可能包含这么多单词。 因此,我将考虑一个小例子,其中我们只有四个单词,即 live, home, they和at。 为了简单起见,我们将考虑语料库只包含一个句子,即存在'They live at home'。
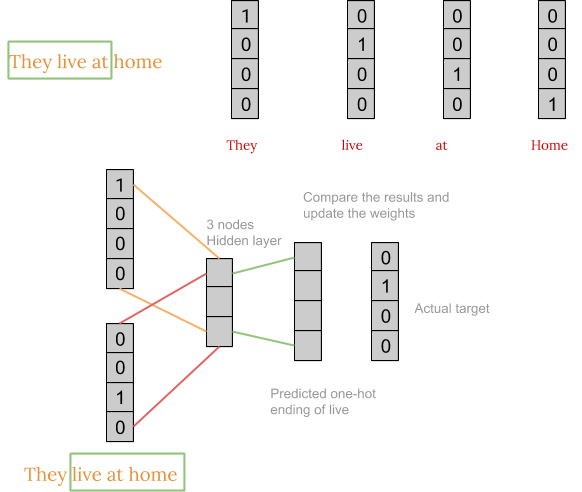
首先,我们将每个单词转换成one-hot encoding形式。 此外,我们不会考虑句子中的所有单词,而只会考虑窗口中的某些单词。 例如,对于等于3的窗口大小,我们只考虑句子中的三个单词。 中间的单词是要预测的,周围的两个单词作为上下文输入神经网络。 然后窗口被滑动,过程再次重复。
最后,通过滑动上面所示的窗口,反复训练网络后,我们得到了我们用来得到embedding的权重,如下所示:
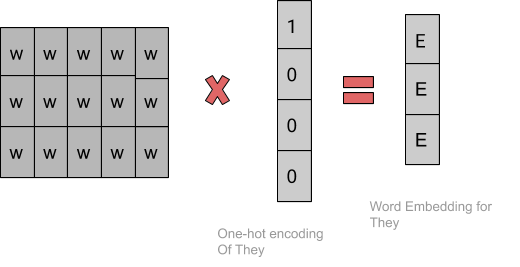
通常,我们的窗口大小约为8-10个单词,向量大小为300。
Skip-gram model
Skip-gram模型体系结构通常试图实现CBOW模型所做的反向操作。 它试图预测给定目标单词(中心单词)的源上下文单词(周围单词)。
Skip-gram model的工作与CBOW相当相似,但其神经网络的结构和权重矩阵的生成方式略有不同,如下图所示:
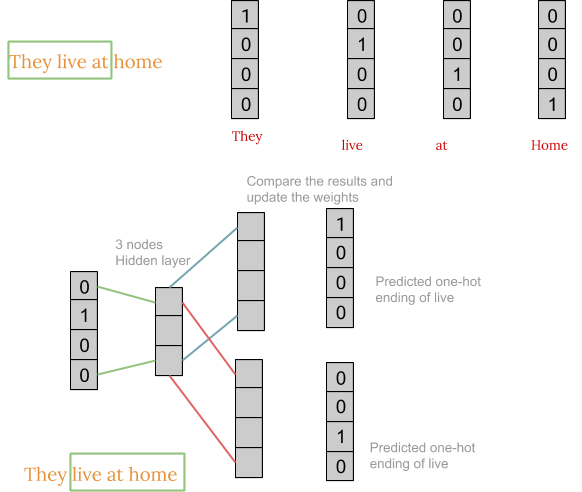
得到权重矩阵后,得到word embedding的步骤与CBOW相同。
那么现在我们应该使用哪一种算法来实现Word2vec? 结果表明,对于大维度的大型语料库,最好使用skip-gram,但训练速度较慢。 而CBOW对小型语料库更好,训练速度也更快。
GloVe
GloVe(用于单词表示的全局向量)是创建word embedding的替代方法。 它是基于词-上下文矩阵的矩阵分解技术。 构造了一个大的共生信息矩阵,我们可以计算每个“单词”(行),以及我们在大型语料库中的某些“上下文”(列)中看到这个单词的频率。 通常,我们以向下方式扫描我们的语料库:对于每一项,我们在该项之前的窗口大小和该项之后的窗口大小定义的某些区域内寻找上下文项。 此外,我们对更远的单词给予较少的权重。
当然,“上下文”的数量很大,因为它本质上是组合的大小。 因此,我们对这个矩阵进行因式分解,得到一个低维矩阵,其中每一行现在为每个单词产生一个向量表示。 一般来说,这是通过最小化“重建损失”来实现的。 这种损失试图找到可以解释高维数据中大部分方差的低维表示。
在实践中,我们使用GloVe和Word2Vec将我们的文本转换为embeddings,两者都表现出类似的性能。 虽然在实际应用中,我们通过窗口大小在5-10左右的Wikipedia文本来训练我们的模型。 语料库中的字数在1300万左右,因此生成这些embeddings需要大量的时间和资源。 为了避免这种情况,我们可以使用预训练过的单词向量,这些向量已经训练过,我们可以很容易地使用它们。 以下是下载预先训练的Word2Vec或GloVe的链接。















 212
212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









