









主成分分析(Principle Component Analysis),是一种数据降维算法,其原理就是通过在原始的坐标系中找一组互相垂直的基底形成新的坐标系,将原始数据从 n n n个维度降低到 k k k个维度。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第 1 , 2 1,2 1,2个轴正交的平面中方差最大的。依次类推,可以得到 k k k个这样的坐标轴。方差最大是为了保证能够尽可能多的保留原始数据信息。
1 前置知识
1.1 谱定理
若 A A A为对称矩阵,同时 λ i \lambda_i λi为该矩阵的特征值,那么有:
A = U Λ U T = Σ i = 1 n λ i u i u i T . Λ = d i a g ( λ 1 , . . . , λ n ) A = U\Lambda U^T = \Sigma^n_{i = 1}\lambda_iu_iu_i^T.\Lambda=diag(\lambda_1,...,\lambda_n) A=UΛUT=Σi=1nλiuiuiT.Λ=diag(λ1,...,λn)
其中, U U U为正交矩阵,即 U U T = U T U = I n UU^T = U^TU = I_n UUT=UTU=In
1.2 瑞利商定理
对于给定的对称矩阵 A ∈ S n A \in S^n A∈Sn,有
λ m i n ( A ) ≤ x T A x x T x ≤ λ m a x ( A ) , ∀ x ≠ 0 \lambda_{min}(A) \leq \frac{x^TAx}{x^Tx} \leq \lambda_{max}(A), \forall x\neq0 λmin(A)≤xTxxTAx≤λmax(A),∀x=0
1.3 奇异值分解(SVD)
奇异值分解不需要矩阵 A A A为方阵,假设这是一个 m ∗ n m * n m∗n的矩阵,那么就会有:
A = U Σ V T = ∑ i = 1 σ i u i v i T A = U\Sigma V^T = \sum_{i = 1}\sigma_iu_iv_i^T A=UΣVT=∑i=1σiuiviT
其中 U U U是一个 m ∗ m m*m m∗m的矩阵, Σ \Sigma Σ是一个 m ∗ n m*n m∗n的矩阵,主对角线上以外的元素全为 0 0 0,主对角线上的每个元素都称为奇异值, V V V是一个 n ∗ n n*n n∗n的矩阵。 U U U和 V V V都是酉矩阵,也就是满足 U T U = I , V T V = I U^TU=I,V^TV=I UTU=I,VTV=I。
2 PCA
2.1 输入输出
P C A PCA PCA的输入为多个向量,每个向量代表一个点。即输入为 x i ∈ R n , i = 1 , 2 , . . . , m x_i \in R^n, i = 1, 2, ..., m xi∈Rn,i=1,2,...,m
输出则为 k k k个主要方向向量,也就是 z 1 , z 2 , . . . , z k ∈ R n , k ≤ n z_1, z_2, ..., z_k \in R^n, k\leq n z1,z2,...,zk∈Rn,k≤n
2.2 计算原理
- 首先将数据标准化,也就是将坐标原点移动到数据中心处。计算方法为 X ~ = [ x ~ 1 , . . . , x ~ m ] , x ~ i = x i − x ˉ . i = 1 , . . . , m \tilde X = [\tilde x_1, ..., \tilde x_m], \tilde x_i = x_i - \bar x. i = 1, ..., m X~=[x~1,...,x~m],x~i=xi−xˉ.i=1,...,m
- 之后,将每个点投影到方向 z z z上,其中 z ∈ R n , ∣ ∣ z ∣ ∣ 2 = 1 z \in R^n, ||z||_2 = 1 z∈Rn,∣∣z∣∣2=1。有 α i = x ~ i T z , i = 1 , . . . , m \alpha_i = \tilde x^T_iz, i=1, ..., m αi=x~iTz,i=1,...,m
- 我们知道,能够尽可能保留更多原始信息的方向应该满足在这个方向上的投影方差最大。因此我们对投影方向上的方差进行计算。计算公式为: 1 m Σ i = 1 m α i 2 = 1 m Σ i = 1 m z T x ~ i x ~ i T z = 1 m z T X ~ X ~ T z \frac{1}{m}\Sigma^{m}_{i = 1}\alpha_i^2 = \frac{1}{m}\Sigma^{m}_{i = 1}z^T\tilde x_i \tilde x_i^Tz = \frac{1}{m}z^T\tilde X \tilde X^Tz m1Σi=1mαi2=m1Σi=1mzTx~ix~iTz=m1zTX~X~Tz
- 将其最大化,实际上就是一个优化问题,也就是寻求 m a x z ∈ R n z T ( X ~ X ~ T ) z , s . t . : ∣ ∣ z ∣ ∣ 2 = 1 max_{z\in R^n}z^T(\tilde X \tilde X^T)z,s.t.:||z||_2 = 1 maxz∈RnzT(X~X~T)z,s.t.:∣∣z∣∣2=1
- 对 X ~ \tilde X X~下手,对其应用 S V D SVD SVD,就可以得到 X ~ = U r Σ V r T \tilde X = U_r\Sigma V_r^T X~=UrΣVrT
- 那么 X ~ X ~ T = U r Σ V r T ( U r Σ V r T ) T = U r Σ V r T V Σ T U r T = U r Σ 2 U r T \tilde X \tilde X^T = U_r\Sigma V_r^T(U_r\Sigma V_r^T)^T = U_r\Sigma V_r^TV\Sigma^T U_r^T = U_r\Sigma ^ 2U_r^T X~X~T=UrΣVrT(UrΣVrT)T=UrΣVrTVΣTUrT=UrΣ2UrT
- 接下来就是要求一下第二个主要坐标轴。首先需要吧主成分 1 1 1中的内容删除掉。也就是 x ~ i ( 1 ) = x ~ i − u 1 ( u 1 T x ~ i ) , i = 1 , . . . , m \tilde x_i^{(1)} = \tilde x_i - u_1(u_1^T\tilde x_i),i=1,...,m x~i(1)=x~i−u1(u1Tx~i),i=1,...,m
- 那么就有 X ~ ( 1 ) = [ x ~ 1 ( 1 ) , . . . , x ~ m ( 1 ) ] = ( I n − u 1 u 1 T ) X ~ \tilde X^{(1)} = [\tilde x_1^{(1)},...,\tilde x_m^{(1)}] = (I_n - u_1u_1^T)\tilde X X~(1)=[x~1(1),...,x~m(1)]=(In−u1u1T)X~
- 应用一下 S V D SVD SVD,就可以有 X ~ ( 1 ) = ∑ i = 1 r σ i u i v i T − ( u 1 u 1 T ) ∑ i = 1 r σ i u i v i T \tilde X^{(1)} = \sum_{i = 1}^r\sigma_iu_iv_i^T - (u_1u_1^T)\sum_{i = 1}^r\sigma_iu_iv_i^T X~(1)=∑i=1rσiuiviT−(u1u1T)∑i=1rσiuiviT
- 后面部分可以转化为 ∑ i = 1 r σ i u 1 u 1 T u i v i T \sum_{i = 1}^r\sigma_iu_1u_1^Tu_iv_i^T ∑i=1rσiu1u1TuiviT,而 u 1 T u i = 1 u_1^Tu_i = 1 u1Tui=1,所以有最终 X ~ ( 1 ) = ∑ i = 1 r σ i u i v i T − σ 1 u 1 v 1 T = ∑ i = 2 r σ i u i v i T \tilde X^{(1)} = \sum_{i = 1}^r\sigma_iu_iv_i^T - \sigma_1u_1v_1^T = \sum_{i = 2}^r\sigma_iu_iv_i^T X~(1)=∑i=1rσiuiviT−σ1u1v1T=∑i=2rσiuiviT
- 之后要求 z 2 z_2 z2,即优化问题 m a x z ∈ R n z T ( X ~ ( 1 ) X ~ ( 1 ) T ) z , s . t . : ∣ ∣ z ∣ ∣ 2 = 1 X ~ ( 1 ) = ∑ i = 2 r σ i u i v i T max_{z\in R^n}z^T(\tilde X^{(1)}\tilde X^{(1)T})z,s.t.:||z||_2=1\ \ \tilde X^{(1)} = \sum_{i = 2}^r\sigma_iu_iv_i^T maxz∈RnzT(X~(1)X~(1)T)z,s.t.:∣∣z∣∣2=1 X~(1)=∑i=2rσiuiviT
- 最终结果即为 z 2 = u 2 z_2 = u_2 z2=u2, u 2 u_2 u2就是 U r U_r Ur矩阵的第二行
- 之后的结果也类似……
综上所述,求取坐标轴的方法分为三步:
- 数据标准化。 也就是 X ~ = [ x ~ 1 , . . . , x ~ m ] , x ~ i = x i − x ˉ . i = 1 , . . . , m \tilde X = [\tilde x_1, ..., \tilde x_m], \tilde x_i = x_i - \bar x. i = 1, ..., m X~=[x~1,...,x~m],x~i=xi−xˉ.i=1,...,m;
- 计算 H = X ~ X ~ T H = \tilde X \tilde X^T H=X~X~T的 S V D 。 SVD。 SVD。
- 最终结果就是 S V D SVD SVD求得的 U r U_r Ur。
2.3 代码实现
def PCA(data):
mean = np.mean(data, axis=0)
X_mean = data - mean
# 协方差矩阵
# 要转置是因为numpy中的协方差矩阵是以行为一个向量的
H = np.cov(X_mean.T)
# 之后计算其SVD,求出特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(H)
# 然后对特征值进行排序,根据特征值排序特征向量
sorted = eigenvalues.argsort()[::-1] # 从大到小的索引值
eigenvalues = eigenvalues[sorted]
eigenvectors = eigenvectors[:, sorted]
return eigenvalues, eigenvectors
3 Kernel PCA
第二节我们所介绍的内容被称为线性 P C A PCA PCA,那么有些情况下会导致无法使用线性变换的方法得到合适的坐标轴来完成目的。比如说下图数据。

这样的数据,我们就很难通过线性变换的方法去找到合适的坐标系去将红色的点和绿色的点分开。那应该怎么办呢?简单来说,就是应该先升维处理,然后再进行和线性 P C A PCA PCA一致的操作。 上面的图当例子来说,升维之后,说不定就能分开了呢?你别说,还真可以,升维后的结果可以如下图:
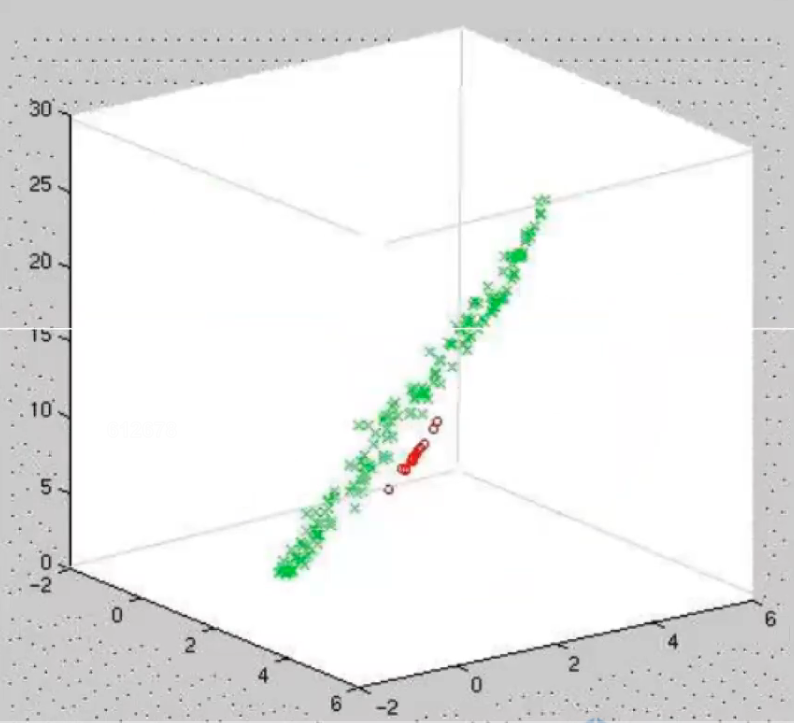
这个时候就可以通过线性变换找到坐标系来处理了!
3.1 基本思路
首先,我们要将数据进行升维,那肯定是要有一个升维函数的对吧!比如说上面那个例子,里面的每个数据点包含的信息为二维信息,即 x i = [ x i 1 , x i 2 ] ∈ R 2 x_i = [x_{i1}, x_{i2}]\in R^2 xi=[xi1,xi2]∈R2,那么我们的升维函数就是 ϕ ( x i ) = [ x i 1 , x i 2 , x i 1 2 + x i 2 2 ] ∈ R 3 \phi(x_i) = [x_{i1}, x_{i2}, x_{i1}^2 + x_{i2}^2]\in R^3 ϕ(xi)=[xi1,xi2,xi12+xi22]∈R3
还是跟线性 P C A PCA PCA一样分三步!
- 首先将升维之后的数据标准化,也就是令 1 N ∑ i = 1 N ϕ ( x i ) = 0 \frac{1}{N}\sum_{i = 1}^N\phi(x_i)=0 N1∑i=1Nϕ(xi)=0
- 之后还是要计算协方差矩阵 H ~ = 1 N ∑ i = 1 N ϕ ( x i ) ϕ T ( x i ) \tilde H = \frac{1}{N}\sum_{i = 1}^N\phi(x_i)\phi^T(x_i) H~=N1∑i=1Nϕ(xi)ϕT(xi)。为什么这里矩阵和转置的位置调换过来了呢?这是因为在进行核 P C A PCA PCA操作的时候,每个点的信息已经都存储为列向量了,而再线性 P C A PCA PCA中是以行向量的方式存储的,有所差别,因此在这里两者换了一下方向。
- 最终就是要求协方差矩阵的特征值,也就是 H ~ z ~ = λ ~ z ~ \tilde H \tilde z = \tilde \lambda \tilde z H~z~=λ~z~
但是并不是只是这样就可以了,还存在有两个问题。升维函数 ϕ \phi ϕ应该如何定义?以及能不能不要在这么高维度的情况下计算?要不然计算量也太大了。答案是:当然可以!
我们实际上要求的就是特征值 z ~ \tilde z z~对吧,包括在线性 P C A PCA PCA中我们也是通过 S V D SVD SVD来求特征值矩阵的。那么我们大胆猜测,对于升维后的 ϕ ( x j ) \phi(x_j) ϕ(xj),每一个都乘以一个系数,最后一定能凑出来 z ~ \tilde z z~的,也就是说
z ~ = ∑ j = 1 N α j ϕ ( x j ) \tilde z = \sum_{j = 1}^N\alpha_j\phi(x_j) z~=∑j=1Nαjϕ(xj)
这个是可以证明的,但是在这里就不提及了。这个公式所代表的意义就是说,我们要求 z ~ \tilde z z~,实际上只要求出 α j \alpha_j αj就可以了。
好好好,接下来我们把之前我们搞的这个 H ~ = 1 N ∑ i = 1 N ϕ ( x i ) ϕ T ( x i ) \tilde H = \frac{1}{N}\sum_{i = 1}^N\phi(x_i)\phi^T(x_i) H~=N1∑i=1Nϕ(xi)ϕT(xi)和 z ~ = ∑ j = 1 N α j ϕ ( x j ) \tilde z = \sum_{j = 1}^N\alpha_j\phi(x_j) z~=∑j=1Nαjϕ(xj)导入到我们的特征值方程 H ~ z ~ = λ ~ z ~ \tilde H \tilde z = \tilde \lambda \tilde z H~z~=λ~z~中,就得到了:
1 N ∑ i = 1 N ϕ ( x i ) ϕ T ( x i ) ( ∑ j = 1 N α j ϕ ( x j ) ) = λ ~ ∑ j = 1 N α j ϕ ( x j ) \frac{1}{N}\sum_{i = 1}^N\phi(x_i)\phi^T(x_i)(\sum_{j = 1}^N\alpha_j\phi(x_j)) = \tilde \lambda \sum_{j = 1}^N\alpha_j\phi(x_j) N1∑i=1Nϕ(xi)ϕT(xi)(∑j=1Nαjϕ(xj))=λ~∑j=1Nαjϕ(xj)
简单应用一下结合律:
1 N ∑ i = 1 N ϕ ( x i ) ( ∑ j = 1 N α j ϕ T ( x i ) ϕ ( x j ) ) = λ ~ ∑ j = 1 N α j ϕ ( x j ) \frac{1}{N}\sum_{i = 1}^N\phi(x_i)(\sum_{j = 1}^N\alpha_j\phi^T(x_i)\phi(x_j)) = \tilde \lambda \sum_{j = 1}^N\alpha_j\phi(x_j) N1∑i=1Nϕ(xi)(∑j=1NαjϕT(xi)ϕ(xj))=λ~∑j=1Nαjϕ(xj)
接下来是重点!我们定义核函数 k ( x i , x j ) = ϕ T ( x i ) ϕ ( x j ) k(x_i, x_j) = \phi^T(x_i)\phi(x_j) k(xi,xj)=ϕT(xi)ϕ(xj),那么上面的公式就可以转化为:
1 N ∑ i = 1 N ϕ ( x i ) ( ∑ j = 1 N α j k ( x i , x j ) ) = λ ~ ∑ j = 1 N α j ϕ ( x j ) \frac{1}{N}\sum_{i = 1}^N\phi(x_i)(\sum_{j = 1}^N\alpha_jk(x_i, x_j)) = \tilde \lambda \sum_{j = 1}^N\alpha_j\phi(x_j) N1∑i=1Nϕ(xi)(∑j=1Nαjk(xi,xj))=λ~∑j=1Nαjϕ(xj)
还能输出!两边都左乘 ϕ ( x k ) , k = 1 , . . . , N \phi(x_k), k = 1, ..., N ϕ(xk),k=1,...,N,实际上就是乘进了 i i i的循环对吧,那么就变成了(注意 1 N \frac{1}{N} N1乘过去了):
∑ i = 1 N ∑ j = 1 N α j k ( x k , x i ) k ( x i , x j ) = N λ ~ ∑ j = 1 N α j k ( x k , x j ) , k = 1 , . . . , N \sum_{i = 1}^N \sum_{j = 1}^N \alpha_jk(x_k, x_i)k(x_i, x_j) = N \tilde \lambda \sum_{j = 1} ^ N \alpha_jk(x_k, x_j), k = 1, ..., N ∑i=1N∑j=1Nαjk(xk,xi)k(xi,xj)=Nλ~∑j=1Nαjk(xk,xj),k=1,...,N
然后我们定义一个格拉姆矩阵(多个向量之间任意两两相乘) K ∈ R N ∗ N , K ( i , j ) = k ( x i , x j ) K \in R^{N*N}, K(i, j) = k(x_i, x_j) K∈RN∗N,K(i,j)=k(xi,xj),他还是对称矩阵,这个还是很好想的,毕竟 k ( x i , x j ) = k ( x j , x i ) k(x_i, x_j) = k(x_j, x_i) k(xi,xj)=k(xj,xi)
那么上面的公式就可以改写为
K 2 α = N λ ~ K α K^2\alpha = N\tilde \lambda K \alpha K2α=Nλ~Kα
两边消掉一个 K K K,变成 K α = N λ ~ α K\alpha = N\tilde \lambda \alpha Kα=Nλ~α
那反正 N N N和 λ ~ \tilde \lambda λ~都是数字, N N N还是个常数,那不如直接把他俩整合为 λ \lambda λ,也就会变为: K α = λ α K\alpha = \lambda \alpha Kα=λα
好,这个时候我们想一想, z ~ = ∑ j = 1 N α j ϕ ( x j ) \tilde z = \sum_{j = 1}^N \alpha_j\phi(x_j) z~=∑j=1Nαjϕ(xj),由于他应该是方向向量,也就是 ∣ ∣ z ~ ∣ ∣ 2 = 1 ||\tilde z||_2 = 1 ∣∣z~∣∣2=1,所以有 1 = z ~ T z ~ 1 = \tilde z^T\tilde z 1=z~Tz~
把 z ~ \tilde z z~的表达式代入,就可以得到 1 = ∑ i = 1 N ∑ j = 1 N α r i α r j ϕ T ( x i ) ϕ ( x j ) 1 = \sum_{i = 1}^N \sum_{j = 1}^N \alpha_{ri} \alpha_{rj}\phi^T(x_i)\phi(x_j) 1=∑i=1N∑j=1NαriαrjϕT(xi)ϕ(xj)
应用一下核函数,他就变成了 1 = α r T K α r 1 = \alpha_r^TK\alpha_r 1=αrTKαr
那么我们刚刚已经看到了有公式 K α = λ α K\alpha = \lambda \alpha Kα=λα,也就是说上面的式子就可以转化为 α r T λ r α r = 1 \alpha_r^T\lambda_r\alpha_r = 1 αrTλrαr=1
也就是说, α r \alpha_r αr的长度应该为 1 / λ r 1/\lambda_r 1/λr
之后我们把升维之后的向量投影到 z ~ r \tilde z_r z~r上,也就能够得到 ϕ T ( x ) z ~ r = ∑ j = 1 N α r j ϕ T ( x ) ϕ ( x j ) = ∑ j = 1 N α r j k ( x , x j ) \phi^T(x)\tilde z_r = \sum_{j = 1}^N \alpha_{rj}\phi^T(x)\phi(x_j) = \sum_{j = 1}^N\alpha_{rj}k(x, x_j) ϕT(x)z~r=∑j=1NαrjϕT(x)ϕ(xj)=∑j=1Nαrjk(x,xj)
还有一件事,就是要把 ϕ ( x i ) \phi(x_i) ϕ(xi)标准化,也就是让平均值为 0 0 0,也就是 ϕ ~ ( x i ) = ϕ ( x i ) − 1 N ∑ j = 1 N ϕ ( x j ) \tilde \phi(x_i) = \phi(x_i) - \frac{1}{N}\sum_{j=1}^N\phi(x_j) ϕ~(xi)=ϕ(xi)−N1∑j=1Nϕ(xj)
随之而来的还有对核函数进行标准化,也就是 k ~ ( x i , x j ) = ϕ ~ T ( x i ) ϕ ~ ( x j ) \tilde k(x_i, x_j) = \tilde \phi^T(x_i)\tilde \phi(x_j) k~(xi,xj)=ϕ~T(xi)ϕ~(xj)
= ( ϕ ( x i ) − 1 N ∑ k = 1 N ϕ ( x k ) ) T ( ϕ ( x j ) − 1 N ∑ i = 1 N ϕ ( x l ) ) = (\phi(x_i) - \frac{1}{N}\sum_{k = 1}^N\phi(x_k))^T(\phi(x_j) - \frac{1}{N}\sum_{i = 1}^N\phi(x_l)) =(ϕ(xi)−N1∑k=1Nϕ(xk))T(ϕ(xj)−N1∑i=1Nϕ(xl))
= k ( x i , x j ) − 1 N ∑ k = 1 N k ( x i , x k ) − 1 N ∑ k = 1 N k ( x j , x k ) + 1 N 2 ∑ k = 1 N ∑ l = 1 N k ( x k , x l ) = k(x_i, x_j) - \frac{1}{N}\sum_{k = 1}^Nk(x_i, x_k) - \frac{1}{N}\sum_{k = 1}^Nk(x_j, x_k) + \frac{1}{N^2}\sum_{k = 1}^N\sum_{l = 1}^Nk(x_k, x_l) =k(xi,xj)−N1∑k=1Nk(xi,xk)−N1∑k=1Nk(xj,xk)+N21∑k=1N∑l=1Nk(xk,xl)
将这个极其复杂的公式再用 K K K来转化,就可以转化为 K ~ = K − 2 ∗ I 1 N K + I 1 N K I 1 N \tilde K = K - 2 * I_{\frac{1}{N}}K + I_{\frac{1}{N}}K I_{\frac{1}{N}} K~=K−2∗IN1K+IN1KIN1,其中 I 1 N = 1 N I_{\frac{1}{N}} = \frac{1}{N} IN1=N1
3.2 常用的核函数
常用的核函数主要包括:
- 线性函数 k ( x i , x j ) = x i T x j k(x_i, x_j) = x_i^Tx_j k(xi,xj)=xiTxj
- 多项式函数 k ( x i , x j ) = ( 1 + x i T x j ) p k(x_i, x_j) = (1 + x_i^Tx_j)^p k(xi,xj)=(1+xiTxj)p
- 高斯函数 k ( x i , x j ) = e − β ∣ ∣ x i − x j ∣ ∣ 2 k(x_i, x_j) = e^{-\beta||x_i - x_j||_2} k(xi,xj)=e−β∣∣xi−xj∣∣2
- 拉普拉斯函数 k ( x i , x j ) = e − β ∣ ∣ x i − x j ∣ ∣ 1 k(x_i, x_j) = e^{-\beta||x_i - x_j||_1} k(xi,xj)=e−β∣∣xi−xj∣∣1
3.3 总结思路
- 选择而一个核函数 k ( x i , x j ) k(x_i, x_j) k(xi,xj),并计算与之对应的格拉姆矩阵 K ( i , j ) = k ( x i , x j ) K(i, j) = k(x_i, x_j) K(i,j)=k(xi,xj)
- 将 K K K标准化,也就是令 K ~ = K − 2 ∗ I 1 N K + I 1 N K I 1 N \tilde K = K - 2 * I_{\frac{1}{N}}K + I_{\frac{1}{N}}K I_{\frac{1}{N}} K~=K−2∗IN1K+IN1KIN1
- 求解 K ~ \tilde K K~的特征向量/特征值,即 K ~ α r = λ r α r \tilde K \alpha_r = \lambda_r\alpha_r K~αr=λrαr
- 然后将 α r \alpha_r αr标准化,也就是令 α r T α r = 1 λ r \alpha_r^T\alpha_r = \frac{1}{\lambda_r} αrTαr=λr1
- 对于任意数据点 x ∈ R n x \in R^n x∈Rn,计算其在第 r r r个主成分 y r ∈ R y_r \in R yr∈R上的投影,也就是 y r = ϕ T ( x ) z ~ r = ∑ j = 1 N α r j k ( x , x j ) y_r = \phi^T(x)\tilde z_r = \sum_{j = 1}^N\alpha_{rj}k(x, x_j) yr=ϕT(x)z~r=∑j=1Nαrjk(x,xj)















 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









