









目录
1 K-means
K-means是最简单且十分好用的聚类方法,其所实现的功能就是将 N N N个点分为 K K K类。它的基本步骤可以分为四步:
- 随机选取 K K K个中心点
- 将所有的 N N N个点都分配到这 K K K个中心点中去
- 将每一个组的中心点重新作为 K K K个中心点
- 重复步骤 2 2 2和步骤 3 3 3
1.1 相关定义
要介绍这样一个算法,我们首先要明白一下定义:
- 我们的数据集为 { x 1 , x 2 , . . . , x N } , x n ∈ R D \{x_1, x_2, ..., x_N\}, x_n \in R^D {x1,x2,...,xN},xn∈RD
- 聚类中心(就是我们要找的 K K K个中心点) μ k , k = 1 , 2 , . . . , K \mu_k, k=1, 2, ..., K μk,k=1,2,...,K
- 布尔类型的变量 r n k ∈ { 0 , 1 } r_{nk}\in\{0, 1\} rnk∈{0,1}, 表示对于第 n n n个点,如果它输入第 k k k类,那么 r n k = 1 r_{nk} = 1 rnk=1, 否则 r n k = 0 r_{nk} = 0 rnk=0
- 做K-means的最终目标就是最小化 J = ∑ n = 1 N ∑ n = 1 K r n k ∣ ∣ x n − μ k ∣ ∣ 2 J = \sum_{n = 1}^N \sum_{n = 1} ^ K r_{nk}||x_n - \mu_k||^2 J=∑n=1N∑n=1Krnk∣∣xn−μk∣∣2
1.2 迭代方法
要实现这样的最终目标,我们需要简单的借助 E M EM EM的思想,具体的 E M EM EM介绍我会放在后面。简单来说就是需要迭代 r n k r_{nk} rnk和 μ k \mu_k μk的值。
- **E(expectation)步骤:**固定 μ k \mu_k μk,在最小化 J J J的情况下求解 r n k r_{nk} rnk。这一步很简单,只需要对每一个点进行操作,找出每一个点最近的 μ k \mu_k μk,然后使得这个点的 r n k = 1 r_{nk} = 1 rnk=1。
- **M(maximization)步骤:**固定 r n k r_{nk} rnk,在最小化 J J J的情况下求解 μ k \mu_k μk。这一步也不麻烦,实际上就是对 J J J求导,使得导数为 0 0 0,即令 2 ∑ n = 1 N r n k ( x n − μ k ) = 0 2\sum_{n = 1}^Nr_{nk}(x_n - \mu_k) = 0 2∑n=1Nrnk(xn−μk)=0,解得 μ k = ∑ n r n k x n ∑ n r n k \mu_k = \frac{\sum_nr_{nk}x_n}{\sum_nr_{nk}} μk=∑nrnk∑nrnkxn
1.3 实现技巧
在实现K-means的时候,也存在一些小技巧,比如说:
- 在初始化 μ k \mu_k μk的时候,并不随机选择范围内的点,而是在已有的点中随机选择。
- 用不同的初始化结果多跑几次,选择其中效果最好的。
- 在E步骤中,需要计算 x n x_n xn和 μ k \mu_k μk之间的距离,那么这个时候可以使用KD-Tree等算法进行提速。(我没理解,总感觉直接计算时间复杂度更低, O ( k n ) O(kn) O(kn)嘛)
- 还可以使用Mini-batch K-Means。在每个E和M的迭代中,选择数据点中的一部分进行迭代。这样做是会更快,但是可能结果误差会更大。下面简单介绍一下:
当我们的Mini-batch选择为1的时候,就叫做Sequential Update,实际上就是对每一个数据点 x n x_n xn进行操作,选择离它最近的中心点 μ k o l d \mu_k^{old} μkold,对这个点进行更新: μ k n e w = μ k o l d + η n ( x n − μ k o l d ) \mu_k^{new} = \mu_k^{old} + \eta_n(x_n - \mu_k^{old}) μknew=μkold+ηn(xn−μkold)。这种方法就比较适合数据点不是一下子全部得到的结果。Mini-batch更大的时候也是同样的道理。效果都是差不多的。
1.4 K-Mediods
有一种情况我们需要考虑,那就是如果这些数据点中存在噪声怎么办?就比如说下面图所示的数据点中最右边的那个点,很明显就是噪声,那么我们使用K-Means得到的中心点很明显不是我们想要的(如下图左边所示),这个时候就需要我们使用K-Mediods算法。
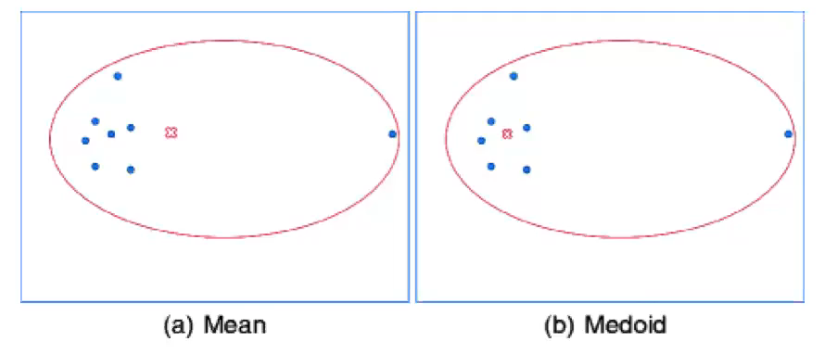
这个方法的E步骤和K-Means是一样的,但是M步骤有所不同,它所要最小化的函数并不是 J = ∑ n = 1 N ∑ n = 1 K r n k ∣ ∣ x n − μ k ∣ ∣ 2 J = \sum_{n = 1}^N \sum_{n = 1} ^ K r_{nk}||x_n - \mu_k||^2 J=∑n=1N∑n=1Krnk∣∣xn−μk∣∣2了,而是 J ~ = ∑ n = 1 N ∑ n = 1 K r n k v ( x n − μ k ) \tilde J = \sum_{n = 1}^N \sum_{n = 1} ^ K r_{nk}v(x_n - \mu_k) J~=∑n=1N∑n=1Krnkv(xn−μk)
其中的 v v v函数是指一些并不能用数学方法具体表达的方法,在这里的 v v v函数就是在这些数据点中选择一个点作为 μ k \mu_k μk,然后其他点到这个点的距离之和。
也就是,这个算法的M步骤就是**选择这些数据点中的某个点作为中心点,要求其他店到这个中心点的距离和最小。**那么这个时候M步骤就不能用求导方法 O ( 1 ) O(1) O(1)得到了,就只能逐个遍历了,最好情况下时间复杂度就变成了 O ( k ( n / k ) 2 ) O(k(n/k)^2) O(k(n/k)2)
1.5 奇怪的应用:图片压缩
其实就是对图片的色彩进行压缩。每一个图片所占用的内存实际上是 H ∗ W ∗ R G B H*W*RGB H∗W∗RGB,其中RGB是说照片的三原色,每一种颜色实际上都是要用8bit来进行表示,那么实际上占用的内存就是 H ∗ W ∗ 24 H*W*24 H∗W∗24。但实际上,是不需要那么多颜色的,一般来说几种颜色就可以较好地表达完一张照片,比如说:

每一种颜色为一个类,那么存储空间就从 H ∗ W ∗ 24 H*W*24 H∗W∗24变成了 H ∗ W ∗ K H*W*K H∗W∗K,但由于每一个bit都可以用 2 M 2^M 2M,因此可以变成 H ∗ W ∗ l o g 2 K H*W*log_2K H∗W∗log2K
1.6 局限性
K-Means主要存在两个方面的局限性:
- K K K的数值需要自己去定
- 每一个点不是这个类就是那个类,不能计算置信度
1.7 代码
from sklearn import datasets
import numpy as np
import open3d as o3d
n_sample = 500
noisy_moon = datasets.make_moons(n_samples=n_sample, noise=.05)
# print(noisy_moon[0])
def dis(a, b) :
return (a[0] - b[0]) * (a[0] - b[0]) + (a[1] - b[1]) * (a[1] - b[1])
def kmeans(data, k, tolerance, maxIter) :
idx = np.random.choice(len(data), k, replace=False)
centroids = data[idx]
cluster = np.zeros(len(data))
dist = np.zeros(len(data))
for i in range(maxIter) :
for j in range(len(data)) :
cluster[j] = -1
dist[j] = 1e10
for j in range(len(data)) :
for k in range(len(centroids)) :
tmp = dis(data[j], centroids[k])
if tmp < dist[j] :
dist[j] = tmp
cluster[j] = k
old_centroids = np.copy(centroids)
for j in range(len(centroids)) :
dataTmp = data[cluster == j]
if len(dataTmp) > 0 :
centroids[j][0] = np.mean(dataTmp[:, 0])
centroids[j][1] = np.mean(dataTmp[:, 1])
else :
centroids[j] = data[np.random.choice(len(data), 1, replace=False)]
distortion = np.linalg.norm(centroids - old_centroids)
if distortion < tolerance :
break
return cluster, centroids
# cluster, centroids = kmeans(noisy_moon[0], 2, 0.0001, 1000)
# print(cluster)
datas = np.zeros([len(noisy_moon[0]), 3])
for i in range(len(noisy_moon[0])) :
datas[i][0] = noisy_moon[0][i][0]
datas[i][1] = noisy_moon[0][i][1]
datas[i][2] = 0
pcd = o3d.geometry.PointCloud()
pcd.points = o3d.utility.Vector3dVector(datas)
cluster, centroids = kmeans(datas, 2, 0.0001, 1000)
color = np.zeros([len(noisy_moon[0]), 3])
for i in range(len(noisy_moon[0])) :
if cluster[i] == 0 :
color[i][0] = 1
else :
color[i][1] = 1
pcd.colors = o3d.utility.Vector3dVector(color)
o3d.visualization.draw_geometries([pcd])
2 GMM
GMM实际上就是使用高斯模型去表示每一个类,使用这种方式就可以去计算每一个点属于各个类的置信度。
2.1 高斯模型
一维高斯模型为:
N ( x ∣ μ , σ 2 ) = 1 ( 2 π σ 2 ) e x p { − 1 2 σ 2 ( x − μ ) 2 } N(x|\mu, \sigma^2) = \frac{1}{(2\pi \sigma^2)}exp\{-\frac{1}{2\sigma^2}(x - \mu)^2\} N(x∣μ,σ2)=(2πσ2)1exp{−2σ21(x−μ)2}
而高维的高斯模型即为:
N ( x ∣ μ , Σ ) = 1 ( 2 π ) D / 2 1 ∣ Σ ∣ 1 / 2 e x p { − 1 2 ( x − μ ) T Σ ( − 1 ) ( x − μ ) } N(\mathbf{x}|\mathbf{\mu}, \mathbf{\Sigma}) = \frac{1}{(2\pi)^{D/2}}\frac{1}{|\Sigma|^{1/2}}exp\{-\frac{1}{2}(\mathbf{x} - \mathbf{\mu})^T\mathbf{\Sigma}^{(-1)}(\mathbf{x} - \mathbf{\mu})\} N(x∣μ,Σ)=(2π)D/21∣Σ∣1/21exp{−21(x−μ)TΣ(−1)(x−μ)}
2.2 GMM模型
实际上就是好多个高斯模型的线性组合。那么我们可以算出 x x x点存在点的可能性为:
p ( x ) = ∑ k = 1 K π k N ( x ∣ μ k , Σ k ) p(x) = \sum_{k = 1} ^K \pi_kN(x|\mu_k, \Sigma_k) p(x)=∑k=1KπkN(x∣μk,Σk)
其中, π k \pi_k πk为第 k k k个高斯模型所占的比重。因此,要描述一个GMM模型,所需要的参数就是 { μ k , Σ k , π k } , k = 1 , 2 , . . . , k \{\mu_k, \Sigma_k, \pi_k\}, k = 1, 2, ..., k {μk,Σk,πk},k=1,2,...,k
但是我们知道 p ( x ) p(x) p(x)是没有用的,我们并不是要生成点,而是已经有了很多点我们需要去进行聚类。
2.3 数学基础
首先,我们定义一个布尔类型的变量 z k ∈ { 0 , 1 } , ∑ k z k = 1 z_k \in \{0, 1\}, \sum_kz_k = 1 zk∈{0,1},∑kzk=1,这个指的是一种事件,就是表示“这个点属于第 k k k类”这个事件。
那么, p ( z k = 1 ) = π k p(z_k = 1) = \pi_k p(zk=1)=πk就是一种先验分布,等同于K-Means中的 r n k r_{nk} rnk,不同的是他并不是说非 0 0 0即 1 1 1,而是说是存在概率的。那么,什么叫先验分布呢?就是说这个空间内任意存在一个点,咱也不知道这个点具体会在哪里,就是它属于哪一个高斯分布的概率。那我都完全不知道点在哪里,那只能通过权重来进行判断了不是嘛?它所占的比重越大, π k \pi_k πk就越大。后验就是知道了高斯分布,也知道了 x x x在哪里,求出 p ( z ∣ x ) p(z|x) p(z∣x),也就是这个点属于分布 z z z的概率。
那么这个后验分布就可以用贝叶斯公式来进行计算:
p ( z ∣ x ) = p ( x ∣ z ) p ( z ) p ( x ) , p ( x ) = ∑ z p ( z ) p ( x ∣ z ) p(z|x) = \frac{p(x|z)p(z)}{p(x)}, p(x) = \sum_zp(z)p(x|z) p(z∣x)=p(x)p(x∣z)p(z),p(x)=∑zp(z)p(x∣z)
其中, p ( z ) p(z) p(z)是先验分布, p ( x ) p(x) p(x)则是2.2节中所介绍的, p ( x ∣ z ) p(x|z) p(x∣z)就之后再介绍一下。
接下来需要介绍一种表示方法:
我们的 z k = 1 z_k = 1 zk=1事件也可以表示为一种1-of-k的方法,也就是 z = [ z 1 , . . . , z k , . . . , z K ] z = [z_1, ..., z_k, ..., z_K] z=[z1,...,zk,...,zK],其中只有 z k = 1 z_k = 1 zk=1,其他的为 0 0 0。这样表示的话,我们之前所提到的先验分布 p ( z k = 1 ) = π k p(z_k = 1) = \pi_k p(zk=1)=πk就表示为 p ( z ) = Π k = 1 K π k z k p(z) = \Pi_{k = 1}^K \pi_k^{z_k} p(z)=Πk=1Kπkzk。这也很好理解,毕竟其他值都是 0 0 0,任何数的 0 0 0次方都为 1 1 1,因此就和没有乘是一样的效果。
上面一段的意思就是: p ( z k = 1 ) = π k p(z_k = 1) = \pi_k p(zk=1)=πk等同于 p ( z ) = Π k = 1 K π k z k p(z) = \Pi_{k = 1}^K \pi_k^{z_k} p(z)=Πk=1Kπkzk。
我们再来看 p ( x ∣ z k = 1 ) p(x|z_k = 1) p(x∣zk=1),这个其实就坍塌成了一个普通的高斯分布,也就是 p ( x ∣ z k = 1 ) = N ( x ∣ μ k , Σ k ) p(x|z_k = 1) = N(x|\mu_k, \Sigma_k) p(x∣zk=1)=N(x∣μk,Σk)
再用上上面那一大段所描述的思想,是不是其实就是 p ( x ∣ z ) = Π k = 1 K N ( x ∣ μ k , Σ k ) z k p(x|z) = \Pi_{k = 1}^K N(x|\mu_k, \Sigma_k)^{z_k} p(x∣z)=Πk=1KN(x∣μk,Σk)zk
然后,我们利用联合分布进行计算,也就是 p ( x ) = ∑ z p ( x , z ) p(x) = \sum_zp(x, z) p(x)=∑zp(x,z),再利用全概率公式,即可得到:
p ( x ) = ∑ z p ( z ) p ( x ∣ z ) = ∑ k = 1 K π k N ( x ∣ μ k , Σ k ) p(x) = \sum_zp(z)p(x|z) = \sum_{k = 1}^K \pi_kN(x|\mu_k, \Sigma_k) p(x)=∑zp(z)p(x∣z)=∑k=1KπkN(x∣μk,Σk)
这下我们就可以计算出后验分布 p ( z ∣ x ) p(z|x) p(z∣x)咯,我们用 γ ( z k ) \gamma(z_k) γ(zk)来表示 p ( z k = 1 ∣ x ) p(z_k = 1|x) p(zk=1∣x),那么就会有:
p ( z ∣ x ) = p ( z , x ) p ( x ) = p ( z ) p ( x ∣ z ) ∑ j = 1 K p ( x ∣ z j ) p ( z j ) p(z|x) = \frac{p(z, x)}{p(x)} = \frac{p(z)p(x|z)}{\sum_{j = 1} ^ Kp(x|z_j)p(z_j)} p(z∣x)=p(x)p(z,x)=∑j=1Kp(x∣zj)p(zj)p(z)p(x∣z)
γ ( z k ) ≡ p ( z k = 1 ∣ x ) = p ( z k = 1 ) p ( x ∣ z k = 1 ) Σ j = 1 K p ( x ∣ z j = 1 ) p ( z j = 1 ) = π k N ( x n ∣ μ k , Σ k ) ∑ j = 1 K π j N ( x n ∣ μ j , Σ j ) \gamma(z_k) \equiv p(z_k = 1 | x) = \frac{p(z_k = 1)p(x|z_k = 1)}{\Sigma_{j = 1}^Kp(x|z_j = 1)p(z_j = 1)} = \frac{\pi_kN(x_n|\mu_k, \Sigma_k)}{\sum_{j = 1}^K \pi_jN(x_n|\mu_j, \Sigma_j)} γ(zk)≡p(zk=1∣x)=Σj=1Kp(x∣zj=1)p(zj=1)p(zk=1)p(x∣zk=1)=∑j=1KπjN(xn∣μj,Σj)πkN(xn∣μk,Σk)
但是!虽然我们可以计算出每一个点分布给每一个高斯分布的概率,可是高斯分布的参数( μ , Σ , π \mu,\Sigma,\pi μ,Σ,π)完全没有去进行计算,上面过程是假设已经确定好了而已。那么,应该如何去进行计算呢?这个时候就要用到MLE算法了。
2.4 MLE(Maximum Likelihood)
2.4.1 奇点问题
假如说,有一个分布是一个圆形的,也就是 Σ k = σ k 2 I \Sigma_k = \sigma_k^2I Σk=σk2I,然后这个点的位置就在这个分布的中心,也就是 x n = μ j x_n = \mu_j xn=μj,那么就会有:
N ( x n ∣ x n , σ j 2 I ) = 1 ( 2 π ) 1 / 2 1 σ j N(x_n|x_n, \sigma_j^2I) = \frac{1}{(2\pi)^{1/2}\frac{1}{\sigma_j}} N(xn∣xn,σj2I)=(2π)1/2σj11
但如果 σ j \sigma_j σj很小的话,这个值就会非常大,甚至会达到 inf \inf inf,也就是说一个分布里面只有一个点的话就容易出现这种情况。那么该如何避免奇点问题呢?最好的解决方式就是不使用MLE,转而使用MAP或者贝叶斯接近。
但是那两种方法太过麻烦,因此可以在 Σ k \Sigma_k Σk很小,就重新给它初始化一个很大的值就好了。
2.4.2 MLE的具体步骤
实际上这个过程就是要让各个分布能够很好的拟合点,实际上也就是最大化 p ( x ) p(x) p(x)。
对于单个点来说, p ( x ) = ∑ k = 1 K π k N ( x ∣ μ k , Σ k ) p(x) = \sum_{k = 1}^K\pi_kN(x|\mu_k, \Sigma_k) p(x)=∑k=1KπkN(x∣μk,Σk)
最终目标是要每个点的 p ( x ) p(x) p(x)连乘值最大,但是连乘是很难进行计算的,因此我们可以取对数,从而使得乘法变成加法:
ln p ( X ∣ π , μ , Σ ) = ∑ n = 1 N ln { ∑ k = 1 K π k N ( x n ∣ μ k , Σ k ) } \ln p(X|\pi, \mu, \Sigma) = \sum_{n = 1}^N\ln\{\sum_{k = 1}^K\pi_kN(x_n|\mu_k, \Sigma_k)\} lnp(X∣π,μ,Σ)=∑n=1Nln{∑k=1KπkN(xn∣μk,Σk)},然后将其最大化。
有三个参数该怎么办呢?很简单,这三个每次都固定两个,然后变化其中的一个。具体步骤我们放在下面:
2.4.3 对 μ k \mu_k μk进行操作
上面这一大串,我们首先对 μ k \mu_k μk求导,让它等于 0 0 0,结果就是:
0 = − ∑ n = 1 N π k N ( x n ∣ μ k , Σ k ) Σ j π j N ( x n ∣ μ j , Σ j ) ∑ k ( x n − μ k ) 0 = -\sum_{n = 1} ^N \frac{\pi_kN(x_n|\mu_k, \Sigma_k)}{\Sigma_j\pi_jN(x_n|\mu_j, \Sigma_j)}\sum_k(x_n - \mu_k) 0=−∑n=1NΣjπjN(xn∣μj,Σj)πkN(xn∣μk,Σk)∑k(xn−μk)
我们注意到,中间这一大坨( π k N ( x n ∣ μ k , Σ k ) Σ j π j N ( x n ∣ μ j , Σ j ) \frac{\pi_kN(x_n|\mu_k, \Sigma_k)}{\Sigma_j\pi_jN(x_n|\mu_j, \Sigma_j)} ΣjπjN(xn∣μj,Σj)πkN(xn∣μk,Σk))是我们之前算的后验概率 γ ( z n k ) \gamma(z_{nk}) γ(znk),那么就可以将上面的公式简化为:
0 = − ∑ n = 1 N γ ( z n k ) ∑ k ( x n − μ k ) 0 = -\sum_{n = 1}^N \gamma(z_{nk})\sum_k(x_n - \mu_k) 0=−∑n=1Nγ(znk)∑k(xn−μk)
计算一下:
符号和 Σ k \Sigma_k Σk都是可以去掉的: 0 = ∑ n = 1 N γ ( z n k ) ( x n − μ k ) 0 = \sum_{n = 1} ^N \gamma(z_{nk})(x_n - \mu_k) 0=∑n=1Nγ(znk)(xn−μk)
∑ n = 1 N γ ( z n k ) x n = μ k ∑ n = 1 N γ ( z n k ) \sum_{n = 1}^N\gamma(z_{nk})x_n = \mu_k\sum_{n = 1}^N\gamma(z_{nk}) ∑n=1Nγ(znk)xn=μk∑n=1Nγ(znk)
μ k = 1 N k ∑ n = 1 N γ ( z n k ) x n , N k = ∑ n = 1 N γ ( z n k ) \mu_k = \frac{1}{N_k}\sum_{n = 1}^N\gamma(z_{nk})x_n, N_k = \sum_{n = 1}^N\gamma(z_{nk}) μk=Nk1∑n=1Nγ(znk)xn,Nk=∑n=1Nγ(znk)
其中, N k N_k Nk感性理解,实际上就是有多少个点属于第 k k k类,就算后验概率为 0.5 0.5 0.5,也就是有 50 % 50\% 50%的概率属于 k k k,那也就可以算有 0.5 0.5 0.5个点属于 k k k。那么,实际上 μ k \mu_k μk不就是每个点的加权平均嘛?
2.4.4 对 Σ k \Sigma_k Σk进行操作
仍然是对 Σ k \Sigma_k Σk进行求导,得到的结果为:
Σ k = 1 N k ∑ n = 1 N γ ( z n k ) ( x n − μ k ) ( x n − μ k ) T \Sigma_k = \frac{1}{N_k}\sum_{n = 1}^N\gamma(z_{nk})(x_n - \mu_k)(x_n - \mu_k)^T Σk=Nk1∑n=1Nγ(znk)(xn−μk)(xn−μk)T
可以注意到,这个是对方差的加权平均。
2.4.5 对 π k \pi_k πk进行操作
针对 π k \pi_k πk,我们不能够像上面两个参数进行操作了,因为我们的 π k \pi_k πk是有约束条件的:
∑ k = 1 K π k = 1 \sum_{k = 1} ^ K \pi_k = 1 ∑k=1Kπk=1
那么我们就要使用拉格朗日乘子法,也就是让原式子变成:
ln p ( X ∣ π , μ , Σ ) + λ ( ∑ k = 1 K π k − 1 ) \ln p(X|\pi, \mu, \Sigma) + \lambda(\sum_{k = 1} ^K \pi_k - 1) lnp(X∣π,μ,Σ)+λ(∑k=1Kπk−1)
然后对 π k \pi_k πk求导让它等于 0 0 0:
0 = ∑ n = 1 N N ( x n ∣ μ k , Σ k ) ∑ j = 1 K π j N ( x n ∣ μ k , Σ k ) + λ 0 = \sum_{n = 1} ^N \frac{N(x_n|\mu_k, \Sigma_k)}{\sum_{j = 1}^K\pi_jN(x_n|\mu_k, \Sigma_k)} + \lambda 0=∑n=1N∑j=1KπjN(xn∣μk,Σk)N(xn∣μk,Σk)+λ
两边同时乘以 ∑ k = 1 K π k \sum_{k = 1}^K\pi_k ∑k=1Kπk,就会变成 0 = ∑ n = 1 N ∑ k = 1 K π k N ( x n ∣ μ k , Σ k ) ∑ j = 1 K π j N ( x n ∣ μ k , Σ k ) + ∑ k = 1 K π k λ 0 = \sum_{n = 1} ^N\sum_{k = 1}^K \frac{\pi_kN(x_n|\mu_k, \Sigma_k)}{\sum_{j = 1}^K\pi_jN(x_n|\mu_k, \Sigma_k)} + \sum_{k = 1}^K\pi_k\lambda 0=∑n=1N∑k=1K∑j=1KπjN(xn∣μk,Σk)πkN(xn∣μk,Σk)+∑k=1Kπkλ
把其中一个求和放到上面去, 0 = ∑ n = 1 N ∑ k = 1 K π k N ( x n ∣ μ k , Σ k ) ∑ j = 1 K π j N ( x n ∣ μ k , Σ k ) + ∑ k = 1 K π k λ 0 = \sum_{n = 1} ^N \frac{\sum_{k = 1}^K\pi_kN(x_n|\mu_k, \Sigma_k)}{\sum_{j = 1}^K\pi_jN(x_n|\mu_k, \Sigma_k)} + \sum_{k = 1}^K\pi_k\lambda 0=∑n=1N∑j=1KπjN(xn∣μk,Σk)∑k=1KπkN(xn∣μk,Σk)+∑k=1Kπkλ
就算字母不一样,但是分子分母还是一样的,就变成了 0 = ( ∑ n = 1 N 1 ) + λ 0 = (\sum_{n = 1}^N 1) + \lambda 0=(∑n=1N1)+λ,即 λ = N \lambda = N λ=N
那就变成了 0 = ∑ n = 1 N N ( x n ∣ μ k , Σ k ) ∑ j = 1 K π j N ( x n ∣ μ k , Σ k ) + N 0 = \sum_{n = 1} ^N \frac{N(x_n|\mu_k, \Sigma_k)}{\sum_{j = 1}^K\pi_jN(x_n|\mu_k, \Sigma_k)} + N 0=∑n=1N∑j=1KπjN(xn∣μk,Σk)N(xn∣μk,Σk)+N
我们搞一个 π k \pi_k πk出来,变成 0 = 1 π k ∑ n = 1 N π k N ( x n ∣ μ k , Σ k ) ∑ j = 1 K π j N ( x n ∣ μ k , Σ k ) + N 0 = \frac{1}{\pi_k}\sum_{n = 1} ^N \frac{\pi_kN(x_n|\mu_k, \Sigma_k)}{\sum_{j = 1}^K\pi_jN(x_n|\mu_k, \Sigma_k)} + N 0=πk1∑n=1N∑j=1KπjN(xn∣μk,Σk)πkN(xn∣μk,Σk)+N
中间这一坨,又变成先验概率 γ ( z n k ) \gamma(z_{nk}) γ(znk)咯,最后又成了 0 = 1 π k ∑ n = 1 N γ ( z n k ) − N 0 = \frac{1}{\pi_k}\sum_{n = 1} ^N \gamma(z_{nk}) - N 0=πk1∑n=1Nγ(znk)−N,结果就是简简单单的 π k = N k N \pi_k = \frac{N_k}{N} πk=NNk
2.5 总结算法
主要分为四步:
- 首先,初始化 μ k , Σ k , π k \mu_k, \Sigma_k, \pi_k μk,Σk,πk
- **E(expectation)步骤:**计算相应的后验概率 γ ( z k ) = π k N ( x n ∣ μ k , Σ k ) ∑ j = 1 K π j N ( x n ∣ μ j , Σ j ) \gamma(z_k) = \frac{\pi_kN(x_n|\mu_k, \Sigma_k)}{\sum_{j = 1}^K \pi_jN(x_n|\mu_j, \Sigma_j)} γ(zk)=∑j=1KπjN(xn∣μj,Σj)πkN(xn∣μk,Σk)
- **M(maximization)步骤:**更新
μ
k
,
Σ
k
,
π
k
\mu_k, \Sigma_k, \pi_k
μk,Σk,πk,即:
- μ k n e w = 1 N k ∑ n = 1 N γ ( z n k ) x n \mu_k^{new} = \frac{1}{N_k}\sum_{n = 1}^N\gamma(z_{nk})x_n μknew=Nk1∑n=1Nγ(znk)xn
- Σ k n e w = 1 N k ∑ n = 1 N γ ( z n k ) ( x n − μ k ) ( x n − μ k ) T \Sigma_k^{new} = \frac{1}{N_k}\sum_{n = 1}^N\gamma(z_{nk})(x_n - \mu_k)(x_n - \mu_k)^T Σknew=Nk1∑n=1Nγ(znk)(xn−μk)(xn−μk)T
- π k n e w = N k N \pi_k^{new} = \frac{N_k}{N} πknew=NNk
- N k = ∑ n = 1 N γ ( z n k ) N_k = \sum_{n = 1}^N\gamma(z_{nk}) Nk=∑n=1Nγ(znk)
- 然后计算 ln p ( X ∣ π , μ , Σ ) = ∑ n = 1 N ln { ∑ k = 1 K π k N ( x n ∣ μ k , Σ k ) } \ln p(X|\pi, \mu, \Sigma) = \sum_{n = 1}^N\ln\{\sum_{k = 1}^K\pi_kN(x_n|\mu_k, \Sigma_k)\} lnp(X∣π,μ,Σ)=∑n=1Nln{∑k=1KπkN(xn∣μk,Σk)},收敛了即可停止
2.6 代码
from sklearn import datasets
import numpy as np
from scipy.stats import multivariate_normal
import open3d as o3d
n_sample = 500
noisy_moon = datasets.make_moons(n_samples=n_sample, noise=.05)
# da = datasets.make_circles(n_samples=n_sample, factor=.5, noise=.05)
data = noisy_moon[0]
def GMM(data, k, tolerance, maxIter):
n, dim = data.shape
mu = data[np.random.choice(range(n), k, replace=False)]
var = np.array([np.eye(dim)] * k)
w = np.ones([n, k]) / k
pi = np.ones(k) / k
nll = np.inf
for j in range(maxIter):
# E Step
pdfs = np.zeros(((n, k)))
for i in range(k):
pdfs[:, i] = pi[i] * multivariate_normal.pdf(data, mean=mu[i], cov=np.diag(var[i]))
w = pdfs / pdfs.sum(axis=1).reshape(-1, 1)
# M Step
# pi
Nk = w.sum(axis=0)
pi = Nk / Nk.sum()
# mu
for i in range(k):
mu[i] = np.multiply(w[:, i].reshape(-1, 1), data).sum(axis=0) / Nk[i]
# var
for i in range(k):
var[i] = np.average((data - mu[i]) ** 2, axis=0, weights=w[:, i])
# nll
last_nll = nll
nll = np.sum(np.log(pdfs.sum(axis=0)))
if np.abs(nll - last_nll) < tolerance:
break
return np.argmax(w, axis=1)
cluster = GMM(data, 2, 0.0001, 1000)
datas = np.zeros([len(noisy_moon[0]), 3])
for i in range(len(noisy_moon[0])) :
datas[i][0] = noisy_moon[0][i][0]
datas[i][1] = noisy_moon[0][i][1]
datas[i][2] = 0
pcd = o3d.geometry.PointCloud()
pcd.points = o3d.utility.Vector3dVector(datas)
color = np.zeros([len(noisy_moon[0]), 3])
for i in range(len(noisy_moon[0])) :
if cluster[i] == 0 :
color[i][0] = 1
else :
color[i][1] = 1
pcd.colors = o3d.utility.Vector3dVector(color)
o3d.visualization.draw_geometries([pcd])
3 EM
在上面所介绍的两种聚类方法中,我们都用到了EM的思想。EM就是为了解决模型中的一些参数没有确定的情况,也就是为了解决诸如 p ( X ∣ θ ) p(X|\theta) p(X∣θ)中 θ \theta θ不确定的问题。EM的整体思路主要分为四步:
- 首先选定初始化参数 θ o l d \theta^{old} θold
- **E(expectation)步骤:**计算后验概率 p ( Z ∣ X , θ o l d ) p(Z|X,\theta^{old}) p(Z∣X,θold)
- **M(maximization)步骤:**求解优化问题来计算
θ
n
e
w
\theta^{new}
θnew。
- KaTeX parse error: Undefined control sequence: \Q at position 26: …w} = \arg \max \̲Q̲(\theta, \theta…
- KaTeX parse error: Undefined control sequence: \Q at position 1: \̲Q̲(\theta, \theta…
- 检查是否收敛,如果不收敛重新回到E步骤。
3.1 用EM解决GMM问题
首先我们知道先验概率有 p ( z ) = Π k = 1 K π n z k p(z) = \Pi_{k = 1}^K\pi_n^{z_k} p(z)=Πk=1Kπnzk
以及 p ( x ∣ z ) = Π k = 1 K N ( x ∣ μ k , Σ k ) z k p(x|z) = \Pi_{k = 1}^KN(x|\mu_k, \Sigma_k)^{z_k} p(x∣z)=Πk=1KN(x∣μk,Σk)zk
我们就可以计算出联合分布 p ( X , Z ∣ μ , Σ , π ) = Π n = 1 N Π k = 1 K N ( x n ∣ μ k , Σ k ) z n k p(X, Z|\mu, \Sigma, \pi) = \Pi_{n = 1}^N \Pi_{k = 1}^KN(x_n|\mu_k, \Sigma_k)^{z_{nk}} p(X,Z∣μ,Σ,π)=Πn=1NΠk=1KN(xn∣μk,Σk)znk
迎合一下EM算法,取一下对数 ln p ( X , Z ∣ μ , Σ , π ) = ∑ n = 1 N ∑ k = 1 K z n k { ln π k + ln N ( x n ∣ μ k , Σ k ) } \ln p(X, Z|\mu, \Sigma, \pi) = \sum_{n = 1}^N \sum_{k = 1}^Kz_{nk}\{\ln \pi_k + \ln N(x_n|\mu_k, \Sigma_k)\} lnp(X,Z∣μ,Σ,π)=∑n=1N∑k=1Kznk{lnπk+lnN(xn∣μk,Σk)}
我们要求的是KaTeX parse error: Undefined control sequence: \Q at position 1: \̲Q̲(\theta, \theta…,那我们就要在对数结果的基础上求一下期望。我们注意到,在 ln p ( X , Z ∣ μ , Σ , π ) \ln p(X, Z|\mu, \Sigma, \pi) lnp(X,Z∣μ,Σ,π)中,后面大括号里面的东西都和 z z z没有关系,所以:
E z [ ln p ( X , Z ∣ μ , Σ , π ) ] = ∑ n = 1 N ∑ k = 1 K E [ z n k ] { ln π k + ln N ( x n ∣ μ k , Σ k ) } E_z[\ln p(X, Z|\mu, \Sigma, \pi)] = \sum_{n = 1}^N \sum_{k = 1}^KE[z_{nk}]\{\ln \pi_k + \ln N(x_n|\mu_k, \Sigma_k)\} Ez[lnp(X,Z∣μ,Σ,π)]=∑n=1N∑k=1KE[znk]{lnπk+lnN(xn∣μk,Σk)}
而我们的 z n k z_{nk} znk只有等于 0 0 0和等于 1 1 1两种情况,我们再看一下我们之前所计算的后验概率:
γ ( z k ) ≡ p ( z k = 1 ∣ x ) = p ( z k = 1 ) p ( x ∣ z k = 1 ) Σ j = 1 K p ( x ∣ z j = 1 ) p ( z j = 1 ) = π k N ( x n ∣ μ k , Σ k ) ∑ j = 1 K π j N ( x n ∣ μ j , Σ j ) \gamma(z_k) \equiv p(z_k = 1 | x) = \frac{p(z_k = 1)p(x|z_k = 1)}{\Sigma_{j = 1}^Kp(x|z_j = 1)p(z_j = 1)} = \frac{\pi_kN(x_n|\mu_k, \Sigma_k)}{\sum_{j = 1}^K \pi_jN(x_n|\mu_j, \Sigma_j)} γ(zk)≡p(zk=1∣x)=Σj=1Kp(x∣zj=1)p(zj=1)p(zk=1)p(x∣zk=1)=∑j=1KπjN(xn∣μj,Σj)πkN(xn∣μk,Σk)
所以实际上 E [ z n k ] = 0 ∗ p ( z n k = 0 ∣ x n , μ k , Σ k , π k ) + 1 ∗ p ( z n k = 1 ∣ x n , μ k , Σ k , π k ) = γ ( z n k ) E[z_{nk}] = 0 * p(z_{nk} = 0|x_n, \mu_k, \Sigma_k, \pi_k) + 1 * p(z_{nk} = 1|x_n, \mu_k, \Sigma_k, \pi_k) = \gamma(z_{nk}) E[znk]=0∗p(znk=0∣xn,μk,Σk,πk)+1∗p(znk=1∣xn,μk,Σk,πk)=γ(znk)
我们最后的KaTeX parse error: Undefined control sequence: \Q at position 1: \̲Q̲函数就是 Q = E z [ ln p ( X , Z ∣ μ , Σ , π ) ] = ∑ n = 1 N ∑ k = 1 K γ ( z n k ) { ln π k + ln N ( x n ∣ μ k , Σ k ) } Q = E_z[\ln p(X, Z|\mu, \Sigma, \pi)] = \sum_{n = 1}^N \sum_{k = 1}^K\gamma(z_{nk})\{\ln \pi_k + \ln N(x_n|\mu_k, \Sigma_k)\} Q=Ez[lnp(X,Z∣μ,Σ,π)]=∑n=1N∑k=1Kγ(znk){lnπk+lnN(xn∣μk,Σk)}
解出来的结果和直接求是一样的:
- μ k n e w = 1 N k ∑ n = 1 N γ ( z n k ) x n \mu_k^{new} = \frac{1}{N_k}\sum_{n = 1}^N\gamma(z_{nk})x_n μknew=Nk1∑n=1Nγ(znk)xn
- Σ k n e w = 1 N k ∑ n = 1 N γ ( z n k ) ( x n − μ k ) ( x n − μ k ) T \Sigma_k^{new} = \frac{1}{N_k}\sum_{n = 1}^N\gamma(z_{nk})(x_n - \mu_k)(x_n - \mu_k)^T Σknew=Nk1∑n=1Nγ(znk)(xn−μk)(xn−μk)T
- π k n e w = N k N \pi_k^{new} = \frac{N_k}{N} πknew=NNk
3.2 K-Means再认识
K-Means实际上就是一种特殊的GMM!
- GMM中的 γ ( z n k ) \gamma(z_{nk}) γ(znk)实际上就是K-Means中的 r n k r_{nk} rnk
- K-Means就是 Σ k = 0 \Sigma_k = 0 Σk=0的GMM
证明一下:
我们有 γ ( z k ) ≡ p ( z k = 1 ∣ x ) = p ( z k = 1 ) p ( x ∣ z k = 1 ) Σ j = 1 K p ( x ∣ z j = 1 ) p ( z j = 1 ) = π k N ( x n ∣ μ k , Σ k ) ∑ j = 1 K π j N ( x n ∣ μ j , Σ j ) \gamma(z_k) \equiv p(z_k = 1 | x) = \frac{p(z_k = 1)p(x|z_k = 1)}{\Sigma_{j = 1}^Kp(x|z_j = 1)p(z_j = 1)} = \frac{\pi_kN(x_n|\mu_k, \Sigma_k)}{\sum_{j = 1}^K \pi_jN(x_n|\mu_j, \Sigma_j)} γ(zk)≡p(zk=1∣x)=Σj=1Kp(x∣zj=1)p(zj=1)p(zk=1)p(x∣zk=1)=∑j=1KπjN(xn∣μj,Σj)πkN(xn∣μk,Σk)
在K-Means中,我们认为它的分布都是圆形的,也就是各个方向都是相等的,即 Σ k = ϵ I \Sigma_k = \epsilon I Σk=ϵI
也就是说 p ( x ∣ μ k , Σ k ) = 1 ( 2 π ϵ ) 1 / 2 e x p { − 1 2 ϵ ∣ ∣ x − μ k ∣ ∣ 2 } p(x|\mu_k, \Sigma_k) = \frac{1}{(2\pi\epsilon)^{1/2}}exp\{-\frac{1}{2\epsilon}||x - \mu_k||^2\} p(x∣μk,Σk)=(2πϵ)1/21exp{−2ϵ1∣∣x−μk∣∣2}
稍微结合一下,就会有在K-Means情况下:
γ ( z n k ) = π k e x p { − ∣ ∣ x n − μ k ∣ ∣ 2 / 2 ϵ } ∑ j π j e x p { − ∣ ∣ x n − μ j ∣ ∣ 2 / 2 ϵ } \gamma(z_{nk}) = \frac{\pi_kexp\{-||x_n - \mu_k||^2 / 2\epsilon\}}{\sum_j\pi_jexp\{-||x_n - \mu_j||^2 / 2\epsilon\}} γ(znk)=∑jπjexp{−∣∣xn−μj∣∣2/2ϵ}πkexp{−∣∣xn−μk∣∣2/2ϵ}
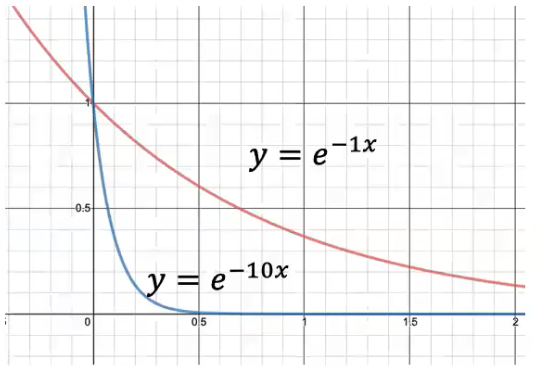
可以看到,exp函数的系数越大,就下降的越快,而 ϵ \epsilon ϵ又十分接近 0 0 0,因此系数应该是无限大的,也就是说这个函数下降的贼快,不是 0 0 0就是无穷大。那么我们用 j ∗ j* j∗来表示接近的类。只有当 j = j ∗ a n d k = j ∗ j = j* \ and\ k = j* j=j∗ and k=j∗是,才为 1 1 1。因此,这个函数就坍塌为了 r n k r_{nk} rnk
因此带入KaTeX parse error: Undefined control sequence: \Q at position 1: \̲Q̲函数中,得到: Q = E z [ ln p ( X , Z ∣ μ , Σ , π ) ] = ∑ n = 1 N ∑ k = 1 K r n k { ln π k + ln N ( x n ∣ μ k , Σ k ) } Q = E_z[\ln p(X, Z|\mu, \Sigma, \pi)] = \sum_{n = 1}^N \sum_{k = 1}^Kr_{nk}\{\ln \pi_k + \ln N(x_n|\mu_k, \Sigma_k)\} Q=Ez[lnp(X,Z∣μ,Σ,π)]=∑n=1N∑k=1Krnk{lnπk+lnN(xn∣μk,Σk)}
又因为我们有 Σ k = ϵ I , ϵ → 0 \Sigma_k = \epsilon I,\epsilon \rightarrow 0 Σk=ϵI,ϵ→0
于是就变成了 Q = E z [ ln p ( X , Z ∣ μ , Σ , π ) ] = − 1 2 ∑ n = 1 N ∑ k = 1 K r n k ∣ ∣ x n − μ k ∣ ∣ 2 + c o n s t Q = E_z[\ln p(X, Z|\mu, \Sigma, \pi)] = -\frac{1}{2}\sum_{n = 1}^N \sum_{k = 1}^Kr_{nk}||x_n - \mu_k||^2 + const Q=Ez[lnp(X,Z∣μ,Σ,π)]=−21∑n=1N∑k=1Krnk∣∣xn−μk∣∣2+const
里面的常数就是 π k \pi_k πk乘出来的一坨,没啥用。这样的话实际上就和我们学习K-Means中的 J J J函数长的一样啦。证明完毕。















 4550
4550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









